منبع: hooshio.com
مجله هوش مصنوعی
آخرین اخبار و تکنولوژی های هوش مصنوعی را در اینجا بخوانید.مجله هوش مصنوعی
آخرین اخبار و تکنولوژی های هوش مصنوعی را در اینجا بخوانید.چگونه می توانیم یک قطب علمی هوش مصنوعی ایجاد کنیم؟
هوش مصنوعی در چند دهه اخیر، یکی از تاثیرگذارترین فناوریهای حوزه کسبوکار بوده و نقش پررنگی دربهینهسازی بسیاری از فرآیندهای سازمانی داشته است. ما بر این باوریم که امروزه در هر شرکتی باید یک قطب علمی هوش مصنوعی وجود داشته باشد. این فناوری یک ابزار مهم در حوزه تجارت است که نباید با بیتوجهی از کنار آن گذشت.
هوش مصنوعی پایه و اساس برخی از ارزشمندترین سامانههای امروزی را تشکیل میدهد و بهزودی تبدیل به بخش جداناپذیری از دنیای کسبوکار و تجارت خواهد شد. علاوه براین، قابلیتهای هوش مصنوعی باید در طول زمان پایدار بمانند تا بتوان به کمک آن، مدلهای جدید کسبوکار را توسعه داده و پشتیبانی کرد. درحالحاضر، بسیاری از شرکتها بخش قابل توجهی از منابع مالی خود را به فنآوری هوش مصنوعی اختصاص دادهاند. افرادی که در این حوزه دارای مهارتهای ضروری و تجربه باشند بسیار کمیابند، به همین دلیل نیز باید این افرادی را گرد هم آورد تا به شکلی منسجم با یک دیگر به تعامل و همکاری بپردازند. همانطور که تجارت الکترونیک باعث ایجاد مشاغل و تیمهای جدیدی همچون مدیر ارشد دیجیتال و تیم پشتیبانی آنلاین شد، هوش مصنوعی نیز منجر به ایجاد یک قطب علمی و نقشهایی تازه در سازمانها خواهد شد.
ایده ایجاد یک مرکز یا قطب علمی هوش مصنوعی، یک ایده افراطی نیست. اخیراً در یک نظرسنجی، از هیئت مدیره شرکتهای بزرگی که از هوش مصنوعی استفاده میکنند، سؤالاتی پرسیده شد. ۳۷% از این مدیران در پاسخ گفتند که هماکنون یک قطب علمی هوش مصنوعی در سازمان خود دارند. بانک دویچه ، جی.پی. مورگان چیس ، پِفیزر ، پروکتِر و گامبِل ، انتِم و شرکت بیمه کشاورزان در میان شرکتهای غیر فناوری هستند که تیمهایی متمرکز و منسجم در حوزه هوش مصنوعی دارند.
برخی از فناوریهای مبتنی بر هوش مصنوعی از قبیل یادگیری ماشینی در میان سازمانها شناخته شدهاند. اما یادگیری ماشینی ریشه در رگرسیون آماری دارد و همین مسئله باعث میشود که ایده ادغام تیمهای تحلیل و هوش مصنوعی به ذهن خطور کند. اگر در سازمان خود یک تیم تحلیلگر دارید که پیشبینیهای تحلیلی انجام میدهد، اعضای این تیم که به یادگیری و پیشرفت علاقهمندند، میتوانند در پروژههای هوش مصنوعی شرکت کنند و در این حوزه تخصص کسب نمایند. در این صورت، ادغام تیمها در سازمان منطقی خواهد بود.
وظایف تیم هوش مصنوعی
یک تیم هوش مصنوعی چه از دل یک تیم تحلیلگر ایجاد شده باشد، چه یک تیم کاملاً جدید باشد، مسئولیتهای زیادی بر عهده خواهد داشت. تیم هوش مصنوعی برای انجام برخی از این وظایف (از قبیل طراحی و توسعه مدلها و سیستمهای هوش مصنوعی، همکاری با نمایندگیهای فروش و ایجاد زیرساخت فنی) میتواند با شرکتهای فعال در حوزه فناوری اطلاعات همکاری کند. برخی دیگر از فعالیتهای تیم هوش مصنوعی نیز نیازمند همکاری با مدیران کسبوکارها است. اگر چه این همکاریها از اهمیت زیادی برخوردارند، اما برخی مسئولیتها نیز تنها بر عهده تیم هوش مصنوعی خواهند بود؛ این مسئولیتها به شرح زیر میباشند:
تعریف چشمانداز شرکت در حوزه هوش مصنوعی: متخصصین حوزه هوش مصنوعی باید ماهیت هوش مصنوعی، تواناییها، قابلیتها و کاربرد آن در طراحی و تعریف مدلها و استراتژیهای کسبوکار را برای مدیران اجرایی بازگو کنند؛ در غیر این صورت، ممکن است نتوانیم از حداکثر قابلیتهای هوش مصنوعی بهره ببریم.
تشریح کاربردهای هوش مصنوعی در حوزه تجارت و کسبوکار: توسعهدهندگان قابلیتهای هوش مصنوعی باید فهرستی از اولویتهای شرکت برای بهکارگیری هوش مصنوعی داشته باشند تا بتوانند میان ارزش راهبردی این کاربردها و اهداف شرکت تعادل برقرار کنند. شرکتها ممکن است تنها برای آزمون و خطا وارد برخی از حوزههای کاربردی هوش مصنوعی شوند، اما درعین حال، باید برای خود مسیری روشن نیز ترسیم کنند که منتهی به تولید محصولات و خدمات مبتنی بر هوش مصنوعی شود.
هدفگذاری مناسب و واقعگرایانه: هوش مصنوعی به جای مشاغل و فرآیندهای کلی کسبوکار، کارها و فعالیتهای جزئی را هدف قرار میدهد؛ به همین دلیل بهترین استراتژی برای تعریف پروژههای هوش مصنوعی داشتن دیدگاهی واقعگرایانه است نه بلندپروازانه. اما درهمینحین، سازمان باید تعداد زیادی پروژه کوچک را در یک حوزه مشخص تعریف و اجرا کند تا بتواند توجه مدیریت شرکت را جلب کرده و در دنیای کسبوکار مؤثر واقع شود. این کار نیازمند طراحی نقشه مسیر و تعیین کاربردهای هوش مصنوعی در طول زمان است. مرکز هوش مصنوعی میتواند به یک شرکت کمک کند که «درعین حال که بزرگ میاندیشد، قدمهای کوچکی بردارد».
تعیین معماری هدف برای دادهها: چشمانداز و کاربردهای هوش مصنوعی تعیینکننده سامانه دادهای و ابزارهای موردنیاز سازمان خواهند بود. نکته کلیدی هر پروژه (مبتنی بر داده) این است که همه انواع دادهها (یعنی دادههای ساختاریافته، ساختارنیافته و خارجی) در آنها لحاظ شوند. امروزه بهطور معمول هَدوپ سامانهای استاندارد برای مدیریت داده درنظر گرفته میشود، اما مرکز هوش مصنوعی باید بین استفاده از سامانههای محلی یا ابری و راهحلهای متنباز و عمومی یا مجوزدار تصمیم بگیرد(برای مثال، شرکتها میتوانند از یکی از سامانههای هدوپِ کلودرا ، سرویسهای تحت وب آمازون و یا سامانههای متنباز استفاده کنند). درحال حاضر اکثر شرکتها به جای استفاده از پکیجهای ابزاری که در گذشته مبتنی بر هوش تجاری بودند (همچون نسخههای ابتدایی SAS و SPSS)، از ابزارهای تحلیلی آمادهای استفاده میکنند که بخشهایی از آنها متنباز است (همچون Alteryx) و به کمک آنها میتوان به سرعت، مدلهایی کاربرپسند طراحی کرد.
آگاهی از نوآوریهای برونسازمانی: تیم هوش مصنوعی میتواند به شرکت کمک کند تا روابطش با دانشگاهها، مراکز فروش، استارتآپهای مبتنی بر هوش مصنوعی و سایر متخصصین و نوآوران را بهبود بخشد. شرکتها میتوانند یک اکوسیستم هوش مصنوعی ایجاد کنند و حتی روی شرکتهای کوچکتری که میتوانند برای کسبوکار آنها ارزشآفرین باشند، سرمایهگذاری کنند. به علاوه، آگاهی از نوآوریها جدید به شرکت کمک میکند تا بهترین ابزارها و فناوریها را در اختیار بگیرد.
ایجاد شبکهای متشکل از حامیان هوش مصنوعی: در صورت ایجاد شبکهای متشکل از طرفدارن و حامیان، بهکارگیری فناوری در حوزه کسبوکار، عملکرد مرکز هوش مصنوعی به بالاترین سطح خود خواهد رسید. فرآیند ایجاد چنین شبکهای در بسیاری از شرکتها آغاز شده است. براساس نظرسنجی سازمان حسابرسی دلویت در سال ۲۰۱۸، ۴۵% از شرکتها، مدیران ارشد خود را به عنوان حامی و طرفدار هوش مصنوعی معرفی کردند. با تجاریسازی شدن برنامهنویسی (در اثر روی کار آمدن زبانهای برنامهنویسی آسانی همچون R و پایتون)، شرکتها برای ایجاد قابلیتهای درونسازمانی باید بهجای برنامهنویسی، بیشتر بر مباحث مدلسازی آماری و ریاضی متمرکز شوند.
انتشار داستان موفقیتها: یکی از عوامل کلیدی در موفقیت هوش مصنوعی و یا هر فناوری جدیدی، انتشار داستان موفقیتها و دستآوردهای اولیه آن در حوزههایی است که برای مخاطبین در اولویت قرار دارند. بدین ترتیب میتوان اشتیاق و رغبت افراد به فعالیتهای مبتنی بر هوش مصنوعی را افزایش داد. بازگو کردن این قبیل داستانها میتواند نوعی بازاریابی برای مرکز هوش مصنوعی نیز باشد.
جذب و پرورش استعدادها
یک عامل بسیار مهم در موفقیت مرکز هوش مصنوعی، جذب و یا پرورش افراد مستعد است. این حقیقت بر هیچکس پوشیده نیست که استخدام یک مهندس هوش مصنوعی یا دانشمند داده (آماردان) حرفهای حتی در سیلیکُون وَلی نیز تا چه حد دشوار است. سازمانها اغلب برای طراحی و اجرای الگوریتمهای هوش مصنوعی به تعداد زیادی نیروی انسانی نیاز ندارند و افرادی که دکترای هوش مصنوعی یا علوم رایانه داشته باشند، برای این جایگاه شغلی مناسبند. اما برای به انجام رسیدن بسیاری از امور مربوط به کسبوکار در یک مرکز هوش مصنوعی، به تحلیلگرانی با مدرک دانشگاهی MBA نیاز است که با مفاهیم و قابلیتهای هوش مصنوعی آشنایی داشته و بتوانند از ابزارهای خودکار یادگیری ماشینی استفاده کنند. البته میتوانید در ابتدا با استخدام مشاورین و فروشندگان، کار بر روی پروژههای ساده و اولیه را آغاز کنید. اما ادغام این تیم با سایر تیمهای شرکت اجتنابناپذیر است.
ممکن است شما به تازگی به فکر پرورش استعدادها در حوزه هوش مصنوعی افتاده باشید. آموزش مباحث هوش مصنوعی به کارمندانی که حتی اندکی با علوم دادهای آشنا هستند، غیرممکن نیست. برخی از شرکتها همچون سیسکو با همکاری دانشگاهها، دورههای آموزشی در حوزه علم داده برای کارمندان خود برگزار کردند. این دورهها در انتها متخصصینی دارای مدرک معتبر به شرکت تحویل دادند. این رویکرد را میتوان در حوزه هوش مصنوعی نیز به کار بست.
شرکتهایی همچون ریپلای و دیتاروبوت و دانشگاههایی همچون اِمآیتی ، دورههای آموزشی کوتاه و جامعی ارائه میدهند که در آنها مهارتهای متناسب با نیاز شرکتها و یا بهطورکلیتر، مهارتهای موردنیاز در حوزه هوش مصنوعی، به دانشجویان آموزش داده میشود.
فرآیندها و ساختارهای سازمانی
درواقع نمیتوان با قاطعیت گفت کدامیک از انواع ساختارهای سازمانی مناسب یک مرکز هوش مصنوعی است، اما ما بر این باوریم که سازمانها در اغلب موارد، با ایجاد یک ساختار متمرکز و داشتن کارمندانی رسمی که باید در برابر یک واحد اداری فراگیر پاسخگو باشند، موفقتر خواهند بود. همانطور که میدانید، افراد بااستعداد در حوزه هوش مصنوعی کمیابند، به همین دلیل، اگر این افراد در سازمان پراکنده باشند، نمیتوان یک تیم قدرتمند ساخت. براساس تجربهای که در زمان ایجاد تیم تحلیلگر بهدست آوردیم، متمرکزسازی فعالیتها منجر به افزایش رضایت شغلی و بقای این قبیل نقشها در سازمان خواهد شد.
برای پرهیز از تشریفات غیرضروری اداری، تیم متمرکز هوش مصنوعی باید به تعدادی از اعضای خود وظایفی در حوزه امور اداری بدهد، البته منظور اموری است که ممکن است تیم هوش مصنوعی به آنها نیاز پیدا کند. بدین ترتیب، کارمندان مرکز هوش مصنوعی با مسائل و مشکلات اداریِ تیم نیز آشنا خواهند شد و میتوانند با مدیران کلیدی شرکت ارتباط برقرار کنند. تغییر وظایف و مسئولیتهای افراد در درون یک واحد اداری میتواند دانش افراد را افزایش و روند انتقال دانش میان آنها را بهبود بخشد. با فراگیر شدن هوش مصنوعی، کارمندان رسمی میتوانند خطوط گزارشدهی سازمانی و اولیه خود را به بخشهای اداری منتقل کنند.
تیم هوش مصنوعی باید در زمینههای مختلفی گزارش تهیه کند، اما از نظر ما بهترین تیم برای دریافت این گزارش، تیمی است که مسئول طراحی راهبردها و فعالیتهای دیجیتال شرکت باشد. شرکت ProSiebenSat.1 (که بزرگترین شرکت خصوصی رسانهای در آلمان است) تیم تحلیل داده خود را بین دو تیم کسبوکار تجاری و فناوری اطلاعات قرار داده تا بتواند بر روی طراحی یک مدل کسبوکار جدید در حوزه اقتصاد سامانهای تمرکز کند. تیمهای هوش مصنوعی و تحلیل در شرکت Versicherungskammer (بزرگترین شرکت دولتی بیمه در آلمان) گزارشهای خود را به مدیر ارشد اطلاعات این شرکت ارائه میدهند. تیم هوش مصنوعی شرکت پروکتر اند گامبل نیز با تلاش مشترک تیمهای تحقیق و توسعه (R&D) و فناوری اطلاعات (IT) شکل گرفت. در شرکت اَنتم، قطب علمی هوش مصنوعی گزارش فعالیتهای خود را به مدیر ارشد دیجیتال این شرکت ارائه میدهد.
در اجرای پروژههای هوش مصنوعی همچون بسیاری از پروژههای فناوری دیگر، داشتن سرعت مهمترین عامل موفقیت است. بنابراین، تعریف دستاوردهای کوتاهمدت و برگزاری جلسات مکرر با سهامداران بهترین راهبرد برای اجرای این قبیل پروژههاست. البته، اگر سیستم به توسعه یا یکپارچهسازی اساسی نیاز داشته باشد، میتوان سایر روشهای سنتی مدیریت پروژه را نیز بهکار گرفت.
ممکن است برخی از فعالیتهای هوش مصنوعی با اصول اخلاقی تناقض داشته باشد، به همین دلیل هرگز نباید در صورت مواجهه با چنین مسائلی، آنها را نادیده بگیرید. ممکن است یک شرکت قصد داشته باشد که به عنوان بخشی از فعالیتهای خود در زمینه هوش مصنوعی، موضعی اخلاقی اتخاذ کند یا یک هیئت بازنگری در این زمینه تشکیل دهد. برای مثال، در شرکت مایکروسافت سمت جدیدی با عنوان «کارشناس اخلاقشناسی در حوزه هوش مصنوعی» تعریف شده است که کمک به سایر کسبوکارها در حوزه مسائل اخلاقی هوش مصنوعی از جمله بایاس الگوریتمی و بررسی تأثیرات نرمافزارهای هوش مصنوعی بر مصرفکنندگان از جمله وظایف این کارشناس است.
کسبوکارها برای رسیدن به موفقیت باید منابع خود را نظم بخشیده و تمرکز آنها را حفظ کنند. همانطور که میدانید افراد بااستعداد و متخصص در حوزه هوش مصنوعی کمیابند و به همین دلیل، این افراد به عنوان یکی از منابع موردنیاز شرکت برای ایجاد یک قطب علمی در حوزه هوش مصنوعی، اهمیت بیشتری از سایر منابع خواهند داشت. به نظر ما، در عمل یک سازمان نمیتواند بدون تخصیص یک بخش مجزا به هوش مصنوعی و کاربردهای آن، موفقیت چشمگیری در این حوزه کسب نماید.
بهترین دیتاست های یادگیری ماشینی برای مبتدیان
اگر به شیوههای آموزش الگوریتمهای یادگیری ماشینی در ۵ یا ۱۰ سال گذشته بنگرید و آن را با شیوههای جدید مقایسه کنید، متوجه تفاوتهای بزرگی میشوید. امروزه آموزش الگوریتمها در یادگیری ماشینی بهتر و کارآمدتر از گذشته است و دلیل آن نیز حجم زیاد دادههایی است که امروزه در دسترس ما قرار گرفتهاند. اما یادگیری ماشینی چگونه از این دادههای استفاده میکند؟
به تعریف اصطلاح «یادگیری ماشینی» دقت کنید: «در یادگیری ماشینی، رایانهها یا ماشینها بدون برنامهنویسی مستقیم و بهطور خودکار از تجربیات گذشته میآموزند». منظور از آموزش ماشینها درواقع همان عبارت «از تجربیات میآموزند» است. طی این فرآیند، دادهها و اطلاعات نقش مهمی ایفا میکنند. اما ماشینها چگونه آموزش داده میشوند؟ پاسخ دیتاستها هستند. به همین دلیل است که دادن اطلاعات و دادههای درست به ماشینی که قرار است مسئله مدنظر شما را حل کند، مسئلهای حیاتی است. در این مقاله دیتاست های یادگیری ماشینی را معرفی میکنیم.
اهمیت دیتاستها در یادگیری ماشینی چیست؟
پاسخ این است که ماشینها نیز همچون انسانها توانایی یادگیری مسائل را دارند و تنها کافی است اطلاعات مرتبط با آن موضوع را مشاهده کنند. اما تفاوت آنها با یک انسان، در مقدار دادهای است که برای یادگیری یک موضوع نیاز دارند. دادههایی که به یک ماشین میدهید، از لحاظ کمیت باید چنان باشد که ماشین درنهایت، کاری که از آن خواستهاید را انجام دهد. به همین دلیل، برای آموزش ماشینها به حجم زیادی از دادهها نیاز داریم.
دادههای یادگیری ماشینی را میتوان مشابه دادههای جمعآوریشده برای انجام یک پژوهش درنظر گرفت، بدین معنا که هر چه حجم دادههای نمونه شما بزرگتر و نمونه گیری شما کاملتر باشد، نتایج حاصل از آن پژوهش معتبرتر خواهد بود. اگر حجم نمونه کافی نباشد، نمیتوانید تمامی متغیرها را مدنظر قرار دهید. این مسئله منجر به کاهش دقت یادگیری و استخراج ویژگی های میشود که اصلا بیانگر داده ها نیستند و در نهایت استنتاج اشتباه ماشین خواهد شد.
دیتاستها دادههای موردنیاز شما را در اختیارتان قرار میدهند. دیتاستها مدلی آموزش میدهند که قادر است واکنشهای مختلفی نشان دهد. آنها مدلی از الگوریتمها میسازند که میتواند روابط را آشکار کند، الگوها را تشخیص دهد، مسائل دشوار را درک کند و تصمیم بگیرد.
نکته مهم در استفاده از دیتاستها این است که دیتاست موردنیاز خود را بهدرستی انتخاب کنید. یعنی دیتاستی را انتخاب کنید که دارای فرمت مناسب و ویژگیها و متغیرهای معناداری در رابطه با پروژه شما باشد، زیرا عملکرد نهایی سیستم به آنچه که از دادهها یاد گرفته، بستگی دارد. علاوه براین، دادن دادههای درست به ماشین، متضمن این خواهد بود که ماشین عملکرد کارآمدی داشته باشد و بتواند بدون دخالت انسان، به نتایج دقیقی برسد.
برای مثال، اگر برای آموزش یک سیستم بازشناسی گفتار از دیتاستی حاوی دادههای مربوط به کتب درسی انگلیسی زبان استفاده کنیم، این ماشین در درک مطالب غیر درسی دچار مشکل خواهد شد. زیرا در این دیتاست، دادههای مربوط به دستورزبان محاورهای، لهجههای خارجی و اختلالات گفتاری وجود ندارد و ماشین نیز نمیتواند چیزی در این خصوص بیاموزد. بنابراین، برای آموزش این سیستم باید از دیتاستی استفاده کرد که متغیرهای گستردهای که در زبان محاوره و در بین جنسیتهای مختلف، سنین متفاوت و لهجههای مختلف وجود دارد را شامل شود.
بنابراین، باید بخاطر داشته باشید که دادههای آموزشی شما باید هر سه ویژگی کیفیت، کمیت و تنوع را داشته باشند، زیرا تمامی این عوامل در موفقیت مدلهای یادگیری ماشینی مؤثر هستند.
برترین دیتاست های یادگیری ماشینی برای مبتدیان
امروزه دیتاستهای فراوانی برای استفاده در فرآیند یادگیری ماشینی دردسترس قرار گرفتهاند. به همین دلیل، ممکن است مبتدیان در تشخیص و انتخاب دیتاست درست برای یک پروژه دچار سردرگمی شوند.
بهترین راهحل برای این مسئله، انتخاب دیتاستی است که بهسرعت دانلود و با مدل سازگار شود. بهعلاوه، همیشه از دیتاستهای استاندارد، قابلدرک و پرکاربرد استفاده کنید. بدین ترتیب، شما میتوانید نتایج کارتان را با نتایج حاصل از کار سایر افرادی که از همان دیتاست استفاده کردهاند، مقایسه کنید و پیشرفت خود را بسنجید.
دیتاست خود را میتوانید براساس نتیجهای که از فرآیند یادگیری ماشین انتظار دارید، انتخاب نمایید. در ادامه، مروری خلاصه بر پرکاربردترین دیتاستها در حوزههای مختلف یادگیری ماشینی از پردازش تصویر و ویدیو گرفته تا بازشناسی متن سیستمهای خودمختار خواهیم داشت.
پردازش تصویر
همانطور که گفته شد، دیتاستهای یادگیری ماشینی متعددی در دردسترس ما قرار دارند، اما برای انتخاب دیتاست باید کارکردی که از برنامه کاربردی خود انتظار دارید را درنظر بگیرید. پردازش تصویر در یادگیری ماشینی برای پردازش تصاویر و استخراج اطلاعات مفید از آنها بهکار گرفته میشود.برای مثال، اگر روی یک نرمافزار ساده تشخیص چهره کار میکنید، میتوانید آن را با استفاده از دیتاستی که حاوی تصاویری از چهره انسانهاست، آموزش دهید. این همان روشی است که فیسبوک برای شناسایی یک فرد در عکسهای دستهجمعی استفاده میکند. همچنین، گوگل و سایتهای جستوجوی تصویری محصول نیز در بخش جستوجوی تصویری خود از چنین دیتاستهایی استفاده کردهاند.
| نام دیتاست | توضیح مختصر |
| ۱۰k US Adult Faces Database | این دیتاست شامل ۱۰.۱۶۸ عکس از چهره طبیعی افراد و ۲.۲۲۲ معیار از چهره است. برخی از معیارهایی که در این دیتاست برای چهره درنظر گرفته شدهاند عبارتند از: بهیادماندنی بودن، بینایی یارانهای و صفات روانشناختی. تصاویر این دیتاست در فرمت JPEG هستند، وضوح تصاویر ۷۲ پیکسل در هر اینچ و ارتفاع آنهاها ۲۵۶ پیکسل است. |
| Google’s Open Images | Open Image دیتاستی است متشکل از ۹ میلیون نشانی اینترنتی که شما را به تصاویر موجود در اینترنت هدایت میکند. این تصاویر دارای برچسبهای توضیحی هستند که در ۶۰۰۰ دسته مختلف طبقهبندی شدهاند. این برچسبها بیشتر عناصر واقعی را شامل میشوند. تنها تصاویری در این دیتاست قرار میگیرند که مجوز انتساب مشترکات خلاقانه را دریافت کرده باشند. |
| Visual Genome | این دیتاست حاوی بیش از ۱۰۰ هزار تصویر است که کاملاً تفسیر شدهاند. نواحی هر یک از این تصاویر به این صورت توصیف شدهاند؛ توضیح ناحیه: دختری که به فیل غذا میدهد، شیء: فیل، صفت: بزرگ، رابطه: غذا دادن. |
| Labeled Faces in the Wild | در این دیتاست بیش از ۱۳.۰۰۰ تصویر از چهره افراد جمعآوری شده است. این تصاویر، تصاویری هستند که در فضای اینترنت به اشتراک گذاشته شده بودند و در برچسب هر تصویر، نام فرد درون تصویر ذکر شده است. |
ایدههایی آسان و سرگرمکننده برای استفاده از دیتاستهای تصویری
• گربه یا سگ: با استفاده از دیتاست گربهها و دیتاست استنفورد که حاوی تصاویر سگها است، برنامه شما میتواند تشخیص دهد که در تصویر دادهشده، سگ وجود دارد یا گربه؟
• طبقهبندی گلهای زنبق: میتوانید به کمک دیتاست گلهای زنبق یک برنامه کاربردی مبتنی بر یادگیری ماشینی طراحی کنید که گلها را در ۳ گونه گیاهی طبقهبندی کند. با اجرای این پروژه دستهبندی صفات فیزیکی برپایه محتوا را خواهید آموخت که به شما در طراحی برنامهها و پروژههای کاربردی همچون ردیابی کلاهبرداری،شناسایی مجرمین، مدیریت درد (برای مثال، برنامه ePAT را درنظر بگیرید که با استفاده از فنآوری تشخیص چهره، نشانههای درد را در صورت فرد شناسایی میکند.) و غیره کمک میکند.
• هاتداگ است یا نه؟: برنامه شما با استفاده از دیتاست Food 101، قادر خواهد بود تا غذاها را شناسایی کند و به شما بگوید که آیا این غذا ساندویچ هاتداگ است یا خیر.
تحلیل احساس
حتی مبتدیان نیز میتوانند با استفاده از دیتاستهای تحلیل احساس برنامههای جالبی طراحی کنند. در یادگیری ماشینی میتوان ماشینها را با بهکارگیری دیتاستهای تحلیل احساس به نحوی آموزش داد که عواطف و احساسات موجود در یک جمله، یک کلمه یا یک متن کوتاه را تحلیل و پیشبینی کنند. بهطور معمول، از این قبیل برنامهها برای تحلیل فیلمها و نظرات مشتریان درمورد محصولات استفاده میشود. اگر کمی خلاقیت به خرج دهید، میتوانید برنامهای طراحی کنید که با استفاده از تحلیلهای احساسی، موضوعی که بحثبرانگیزتر از سایرین خواهد بود را شناسایی کند.
| نام دیتاست | توضیح مختصر |
| Sentiment140 | این دیتاست حاوی ۱۶۰.۰۰۰ توییت است که شکلکهای استفادهشده در آنها حذف شدهاند. |
| Yelp Reviews | این دیتاست یک دیتاست رایگان است که توسط شرکت Yelp منتشر شده و حاوی بیش از ۵ میلیون نظر درباره رستورانها، فروشگاهها، تفریحهای شبانه، غذاها، سرگرمیها و غیره است. |
| Twitter US Airline Sentiment | در این دیتاست دادههای مربوط به خطوط هواپیمایی آمریکا در شبکه اجتماعی توییترT از سال ۲۰۱۵ جمعآوری شده و به هر یک از آنها یکی از برچسبهای مثبت، منفی و خنثی داده شده است. |
| Amazon reviews | در این دیتاست بیش از ۳۵ میلیون نظر ثبتشده در وبسایت آمازون طی دوره زمانی ۱۸ ساله جمعآوری شده است. دادههای موجود شامل اطلاعاتی درخصوص محصولات، امتیاز کاربران و نظرات متنی هستند. |
ایدههایی آسان و سرگرمکننده برای استفاده از دیتاستهای تحلیل احساسی
مثبت یا منفی: با استفاده از دیتاست Spambase در مدل خود، توییتها را تحلیل کنید و آنها در دو دسته مثبت و منفی طبقهبندی کنید.
راضی یا ناراضی: با استفاده از دیتاست Yelp Reviews پروژهای تعریف کنید که در آن یک ماشین بتواند با مشاهده نظر یک فرد درخصوص یک محصول تشخیص دهد که فرد از آن محصول راضی بوده یا ناراضی.
خوب یا بد: میتوانید با استفاده از دیتاست Amazon reviews، یک ماشین را به نحوی آموزش دهید که خوب یا بد بودن نظرات کاربران را تشخیص دهد.
پردازش زبان طبیعی
در فنآوری پردازش زبان طبیعی ماشینها درجهت تحلیل و پردازش حجم زیادی از دادههای مربوط به زبانهای طبیعی آموزش میبینند. موتورهای جستوجو همچون گوگل به کمک این فنآوری میتوانند آنچه شما در بخش جستوجو مینویسید را پیدا کنند. شما نیز میتوانید با استفاده از این قبیل دیتاستها، یک برنامه کاربردی جالب پردازش زبان طبیعی و مبتنی بر یادگیری ماشینی طراحی کنید.
| نام دیتاست | توضیح مختصر |
| Speech Accent Archive | این دیتاست حاوی ۲۱۴۰ نمونه صوتی است که در آنها افرادی از ۱۷۷ کشور و ۲۱۴ ریشه زبانی مختلف حضور دارند و متن واحدی را به زبان انگلیسی میخوانند. |
| Wikipedia Links data | این دیتاست حاوی تقریبا ۱.۹ میلیارد واژه است که از بیش از ۴ میلیون مقاله جمعآوری شدهاند. در این دیتاست میتوان واژهها، عبارات یا بخشی از یک پاراگراف را جستوجو کرد. |
| Blogger Corpus | این دیتاست متشکل از ۶۸۱.۲۸۸ پست از وبلاگهای مختلف است که از وبسایت Blogger.com جمعآوری شدهاند. در هر یک از این وبلاگهای منتخب، حداقل ۲۰۰ واژه پرکاربر انگلیسی استفاده شده است. |
ایدههایی جالب برای استفاده از دیتاستهای پردازش زبان طبیعی:
• هرزنامه یا مفید: با استفاده از دیتاست Spambase میتوانید برنامهای طراحی کنید که قادر باشد ایمیلهای هرزنامه را از ایمیلهای مفید و خوب تشخیص دهد.
پردازش ویدیو
با استفاده از دیتاستهای پردازش ویدیو، ماشین شما میآموزد که صحنههای مختلف یک ویدیو و اشیاء، احساسات و کنش و واکنشهای درون آن را شناسایی و تحلیل کند. به این منظور، شما باید حجم زیادی از دادههای مربوط به واکنشها، اشیاء و فعالیتها را به ماشین خود بدهید.
| نام دیتاست | توضیح مختصر |
| UCF101 – Action Recognition Data Set | این دیتاست شامل ۱۳.۳۲۰ ویدیو است که براساس عملی که در آنها اتفاق میافتد در ۱۰۱ گروه دستهبندی شدهاند. |
| Youtube 8M | Youtube 8M دیتاستی متشکل از تعداد زیادی ویدیوهای برچسب گذاری شده است. این دیتاست شامل شناسههای میلیونها ویدیو از یوتیوب و تفسیرهای ماشینی بسیار باکیفیت از این ویدیوهاست. در این تفسیرهای ماشینی از بیش از ۳.۸۰۰ واژه مربوط به اشیاء دیداری استفاده شده است. |
یک ایده جالب یرای استفاده از دیتاستهای پردازش ویدیو
- تشخیص عمل: با استفاده از دیتاستهای UCF101 – Action Recognition Data Set یا Youtube 8M میتوانیدبه برنامه کاربردی خود آموزش دهید تا اعمال مختلف چون راهرفتن یا دویدن را در یک ویدیو شناسایی کند.
تشخیص گفتار
تشخیص گفتار به این معناست که یک ماشین میتواند واژهها و عبارات را در زبان گفتاری شناسایی یا تحلیل کند. اگر کیفیت و کمیت دادههایی که به ماشین خود دادهاید مناسب باشد، عملکرد بهتری در حوزه تشخیص گفتار خواهد داشت. با ترکیب دو فنآوری پردازش زبان طبیعی و پردازش گفتار میتوانید دستیار شخصی شبیه به الکسا طراحی کنید که بتواند خواسته شما را به درستی متوجه شود.
| نام دیتاست | توضیح مختصر |
| Gender Recognition by Voice and speech analysis | این دیتاست براساس ویژگیهای آوایی صدا و گفتار، صدای زنان را از مردان تمیز میدهد. این دیتاست حاوی ۳.۱۶۸ فایل صوتی ضبطشده از صدای زنان و مردان مختلف در هنگام سخن گفتن است. |
| Human Activity Recognition w/Smartphone | دیتاست Human Activity Recognition حاوی ویدیوهایی است که از ۳۰ فرد در حین انجام فعالیتهای روزانهشان گرفته شده است. در حین انجام این فعالیتها یک گوشی موبایل (سامسونگ گلکسی S2) نیز به کمر آنها متصل شده بود. |
| TIMIT | از دیتاست TIMIT در مطالعات آواشناسی آکوستیک و توسعه سیستمهای خودکار تشخیص گفتار استفاده میشود. این دیتاست متشکل از فایلهای صوتی ضبطشده از ۶۳۰ نفر است که با ۸ گویش رایج انگلیسی آمریکایی صحبت میکردند. هر یک از افراد حاضر در این فرآیند باید کلمات، مصوتها و جملاتی را میخواندند که از لحاظ آوایی بسیار غنی بودند. |
| Speech Accent Archive | این دیتاست حاوی ۲۱۴۰ نمونه صوتی است که در آنها افرادی از ۱۷۷ کشور و ۲۱۴ ریشه زبانی مختلف حضور دارند و متن واحدی را به زبان انگلیسی میخوانند. |
ایدههایی جالب برای استفاده از دیتاستهای تشخیص گفتار
• تشخیص لهجه: با استفاده از دیتاست Speech Accent Archive، برنامه کاربردی شما قادر خواهد بود لهجههای مختلف را از میان لهجههای نمونه تشخیص دهد.
• شناسایی عمل: با استفاده از دیتاست Human Activity Recognition w/Smartphone میتوانید برنامهای طراحی کنید که فعالیتهای انسان را تشخیص دهد.
تولید زبان طبیعی
تولید زبان طبیعی به معنای توانایی ماشینها در شبیهسازی گفتار انسان است. به کمک این فنآوری میتوان مطالب نوشتهشده را به فایلهای شنیداری تبدیل کرد. همچنین این فنآوری میتواند با خواندن مطالبی که روی صفحه نقش بستهاند، به افراد کمبینا و دارای نقص بینایی کمک کند. این درواقع همان روشی است که دستیارهای هوشمندی چون الکسا و سیری به شما پاسخ میدهند.
| نام دیتاست | توضیح مختصر |
| Common Voice by Mozilla | دیتاست Common Voice حاوی دادههای گفتاری است که در وبسایت Common Voice توسط کاربران خوانده شدهاند. متون خوانده شده در این وبسایت، از منابع عمومی همچون پستهای کاربران در وبلاگها، کتابهای قدیمی و فیلمها است. |
| LibriSpeech | این دیتاست شامل حدود ۵۰۰ ساعت فایل صوتی است. این فایلها حاوی کتابهای صوتی هستند که توسط افراد مختلف و به زبانی روان خوانده شدهاند. در این دیتاست فایل صوتی و متن اصلی هر کتاب به تفکیک فصول آن، موجود است. |
ایدههایی جالب برای استفاده از دیتاستهای تولید زبان طبیعی
• تبدیل متن به گفتار: با استفاده از دیتاست Blogger Corpus، میتوانید برنامهای طراحی کنید که متون موجود در وبسایت را با صدای بلند بخواند.
اتومبیلهای خودران
شما نیز میتوانید یک برنامه یادگیری ماشینی ساده برای اتومبیلهای خودران طراحی کنید. دیتاستهای یادگیری ماشینی موجود در حوزه اتومبیلهای خودران برای درک محیط و هدایت خودرو بدون نیاز به دخالت انسان، به شما کمک خواهند کرد. از این الگوریتمها میتوان برای هدایت اتومبیلهای خودران، پهبادها، رباتهای انباردار و غیره استفاده کرد. اهمیت دیتاستها در این حوزه بیشتر از سایر حوزههای یادگیری ماشینی است، زیرا ریسک دراین حوزه بیشتر است و هزینه یک اشتباه ممکن است جان یک انسان باشد.
| نام دیتاست | توضیح مختصر |
| Berkeley DeepDrive BDD100k | این دیتاست یکی از بزرگترین دیتاستهای موجود در حوزه اتومبیلهای خودران مبتنی بر هوش مصنوعی است. این دیتاست حاوی بیش از ۱۰۰.۰۰۰ ویدیو از بیش از ۱۰۰۰ ساعت رانندگی در شرایط آبوهوایی ساعات مختلف روز میباشد. |
| Baidu Apolloscapes | Baidu Apolloscapes دیتاستی بزرگ متشکل از ۲۶ قلم شیء معنایی از جمله خودرو، دوچرخه، عابرین پیاده، ساختمان، چراغ برق و غیره است. |
| Comma.ai | این دیتاست حاوی بیش از ۷ ساعت ویدیو از رانندگی در بزرگراه است. این دادهها شامل اطلاعاتی درخصوص سرعت، شتاب، زاویه فرمان و مختصات مکانی خودرو میشوند. |
| Cityscape Dataset | این دیتاست متشکل از حجم زیادی از دادههای ویدیوی تهیهشده از خیابانهای ۵۰ شهر مختلف است. |
| nuScenes | این دیتاست حاوی بیش از ۱۰۰۰ تصویر از مناظر، حدود ۱.۴ میلیون تصویر، ۴۰۰.۰۰۰ داده درخصوص وسعت دید سیستم لیدار (سیستمی که با استفاده از لیزر، فاصله بین اجسام را میسنجد) و ۱.۳ میلیون کادر محاطی ۳ بعدی (که با کمک دوربینهای RGB، رادارها و لیدار اشیاء را شناسایی میکند) است. |
ایدههایی جالب برای استفاده از دیتاستهای اتومبیلهای خودران
• طراحی برنامهای ساده برای اتومبیلهای خودران: با استفاده از یکی از دیتاستهای بالا و دادههای مربوط به تجربیات مختلف رانندگی در شرایط آبوهوایی متفاوت، برنامه خود را آموزش دهید.
اینترنت اشیاء
کاربردهای یادگیری ماشینی در حوزه اینترنت اشیاء روزبهروز درحال گسترش است. شما به عنوان یک مبتدی در دنیای یادگیری ماشینی ممکن است دانش لازم برای طراحی برنامههای اینترنت اشیاء کاربردی و پیشرفته که از یادگیری ماشینی استفاده میکنند را نداشته باشید، اما قطعاً میتوانید با شناخت دیتاستهای مربوطه، به این دنیای شگفتانگیز قدم بگذارید.
| نام دیتاست | توضیح مختصر |
| Wayfinding, Path Planning, and Navigation Dataset | این دیتاست حاوی نمونههایی از مسیریابی درون یک ساختمان (کتابخانه Waldo در دانشگاه غرب میشیگان) است. این دادهها بهطورمعمول در نرمافزارهای مسیریابی بهکار گرفته میشوند. |
| ARAS Human Activity Dataset | این دیتاست یک دیتاست در حوزه تشخیص فعالیتهای انسانی است که از ۲ خانوار واقعی جمعآوری شده که شامل بیش از ۲۶ میلیون داده از حسگرها و بیش از ۳۰۰۰ فعالیت انجامشده میباشد. |
یک ایده جالب برای استفاده از دیتاستهای اینترنت اشیاء:
• طراحی یک دستگاه پوشیدنی برای پیگیری فعالیتهای افراد: با استفاده از دیتاست ARAS Human Activity Dataset، یک دستگاه پوشیدنی را آموزش دهید تا بتواند فعالیتهای افراد را تمیز دهد.
پس از به پایان رساندن مطالعه این لیستها، نباید احساس محدودیت کنید. این دیتاستها تنها تعدادی از دیتاستهایی هستند که میتوانید در برنامههای کاربردی مبتنی بر یادگیری ماشینی از آنها استفاده کنید. در فضای اینترنت میتوانید دیتاستهای بهتری نیز برای پروژه یادگیری ماشینی خود پیدا کنید.
میتوانید در وبسایتهای Kaggle، UCI Machine Learning Repository، Kdnugget، Awesome Public Datasets, و Reddit Datasets Subredditدیتاستهای بیشتری پیدا کنید.
حال وقت آن است که این دیتاستها را در پروژه خود به کار بگیرید. اگر در حوزه یادگیری ماشینی مبتدی هستید این مقاله نیز در آشنایی بیشتر با این فنآوری به شما کمک خواهد کرد.
جدا از این که تازهکار هستید یا مدتی در دنیای یادگیری ماشینی فعالیت داشتهاید، باید همواره بهخاطر داشته باشید که دیتاستی را انتخاب کنید که پرکاربرد باشد و بتوان آن را بهسرعت از یک منبع قابلاعتماد بارگیری کرد.
منبع: hooshio.com
با یادگیری بدون نظارت برای سفر به پاریس برنامهریزی کنید
تاکنون به این موضوع فکر کردهاید که یادگیری بدون نظارت برای سفر میتواند به شما در برنامهریزی سفر به پاریس کمک کند؟ با ما همراه باشید تا بگوییم چگونه این کار شدنی است. ابتدا ما فهرستی از چشماندازها و مکانهای دیدنی پاریس تهیه کردهایم تا علاقمندان از آن استفاده کنند. پس از اینکه فهرستبندی مکانها و جاذبههای گردشگری به پایان رسید، یک نقشه گوگل هم ساخته شد. مشاهده تمامی جاذبههای گردشگری پاریس به برنامهریزی خاصی احتیاج دارد؛ اما سوال اینجاست که چطور میتوان تصمیم گرفت از کدام جاذبهها در وهله اول دیدن کرد و از چه ترتیبی باید پیروی کرد؟ ما این کار را به منزلۀ یک مسئله خوشهبندی تلقی میکنیم. روش یادگیری بدون نظارت میتواند نقش مهمی در حل این مسئله ایفا کند.
الگوریتم هایی نظیر K-Means یا DBScan هم در این مسئله میتوانند به کار آیند. اما در ابتدا باید دادهها را آماده کرد تا چنین الگوریتمهایی مطابق خواستهها عمل کند.
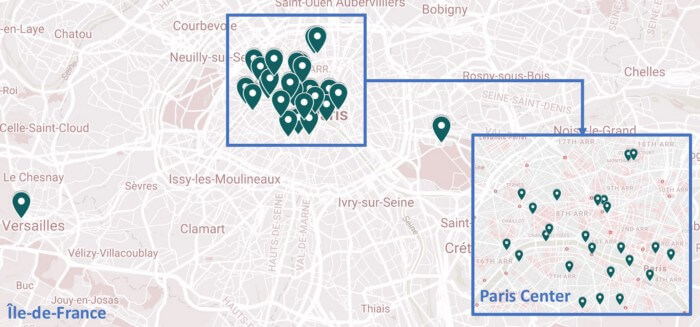
موقعیت جغرافیایی و آمادهسازی دادهها
پیش از هرچیز موقعیتهای جغرافیایی را در پین نقشه گوگل با فرمت دوبعدی بررسی کردیم. تبدیل پینها به طول جغرافیایی و عرض جغرافیایی میتواند اقدام بسیار خوبی باشد. ما به دنبال راهی سریعتر برای استخراج این اطلاعات از نقشه گوگل بودیم. StackOverflow کمک میکند تا به همه خواستههایمان برسیم. شما باید به این لینک مراجعه کرده و فایل *.kmz را دانلود کنید. سپس باید این فایل را به فایل *.zip تغییر دهید. در وهله بعد، نوبت به استخراج فایل و باز کردن doc.kml با نرمافزار ویرایش متن دلخواهتان میرسد (ما از SublimeText استفاده میکنیم).
حال، میتوانید از فرمان CTRL+F برای جستجوی فیلدها استفاده کنید یا از BeautifulSoup استفاده کنید (همان طور که در ذیل مشاهده میکنید). به محض استخراج مختصات از فایل XML، مختصات را در دیتافریم ذخیره کردم. در مجموع ۲۶ مکان دیدنی وجود دارد (که با عنوان در فایل XML ذخیره شده است).
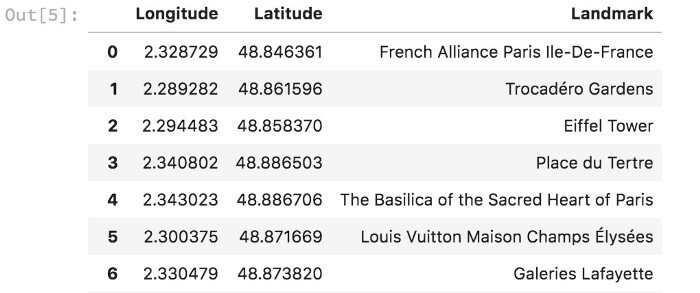
این دیتافریم حاوی اطلاعاتی از فایل XML میباشد (فقط ۷ ردیف نخست نشان داده شده است).
ما از دیتافریمی که مختصات و نام مکانهای دیدنی در آن ذخیره شده بود، برای ایجاد نقشه پراکندگی استفاده کردیم.
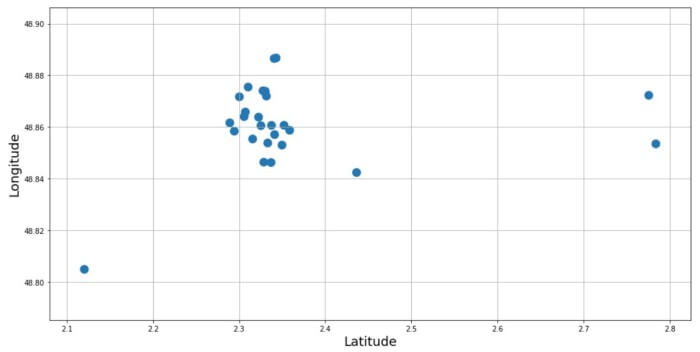
نقشه پراکندگی پینهای نقشه گوگل
خوشهبندی K-MEANS
زمانی که ابهام در پیامد مورد پیشبینیمان وجود داشته باشد، روشهای یادگیری بدون نظارت عموماً برای دادههایی که فاقد برچسبهای AND هستند، بسیار مفید واقع میشوند. این الگوریتمها معمولاً به دو شکل قابل دسترس هستند:
۱) الگوریتمهای خوشهبندی
۲) الگوریتمهای کاهش بُعد
در این بخش، میخواهیم عمده تمرکزمان را روی الگوریتم خوشهبندی K-Means بگذاریم. در این الگوریتم، تعداد خوشهها به عنوان ورودی از پیش تعیین شده است و الگوریتم به ایجاد خوشهها در دیتاست بدون برچسب میپردازد. K-Means مجموعهای از نقاط مرکزی خوشه K و برچسبی از چیدمان ورودی X ایجاد میکند. به این ترتیب، کلیه نقاط واقع در X به خوشه منحصربفردی اختصاص داده میشوند. این الگوریتم نقاط مرکزی خوشهها را به عنوان میانگین کلیه نقاط متعلق به خوشه محاسبه میکند.

این کار با پایتون به شکل زیر انجام میشود:
همانطور که از نمودار پراکندگی زیر پیداست، ما ۱۰ خوشه ساختم؛ یعنی یک خوشه برای هر روز از سفر. چون مراکز دیدنی در مرکز پاریس فاصله نزدیکی با هم دارند، تفکیک یک خوشه از خوشه دیگر کار دشواری است. پیشبینیها مرتب شده و در دیتافریم ذخیره شدند. k-means برای ایجاد ۱۰ خوشه مورد استفاده قرار گرفت. نقاط سیاه مرکز خوشهها را نشان میدهند. من از ۱۰ خوشهای که با k-means ایجاد شده بود، برای ساخت دیتافریمی استفاده کردم که روزهای هفته را به هر خوشه تخصیص میدهد. به این ترتیب، یک نمونه برنامه زمانی به دست میآید.
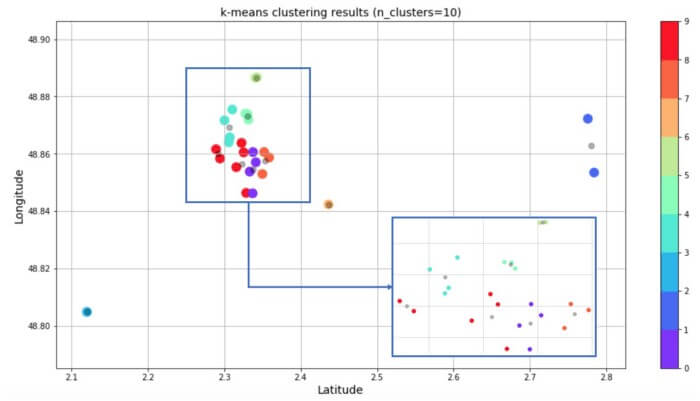
نتایج k-means (روزهای سفر در هفته – فقط سه روز اول نشان داده شده است.)
اکنون، در این مرحله، دیتافریم مرتب شده و پینهای نقشه گوگل مجدداً ساماندهی میشوند (هر لایه نشاندهندۀ یک روز است). خودشه! برنامه سفر تهیه شد.

اما یک مورد همچنان اذیتکننده است. k-means بر اساس فاصله اقلیدسی میان نقاط به خوشهسازی میپرداخت. اما میدانیم که زمین تخت نیست؛ مابه دنبال بررسی این مسئله بودیم که آیا این تقریب بر خوشههای ایجاد شده تاثیر میگذارد یا خیر. باید به این نکته هم توجه داشت که چند نقطه دیدنی با فاصله از مرکز پاریس واقع شده است.

با HDBSCAN آشنا شوید!
پس به یک روش خوشهبندی احتیاج داریم که فواصل جغرافیایی (طول کوتاهترین منحنی میان دو نقطه در امتداد سطح زمین) را بطور کارآمد مدیریت کند.

تابع تراکم جمعیت HDBSCAN که بر پایه الگوریتم DBScan قرار دارد، میتواند نقش سودمندی در این فرایند داشته باشد. هر دو الگوریتمِ HDBSCAN و DBSCAN از جمله روشهای خوشهبندی مکانی به شمار میروند و بر پایه تراکم قرار دارند. این الگوریتمها بر اساس اندازهگیری فاصله و تعداد حداقلی نقاط، به گروهبندی آن دسته از نقاطی میپردازند که در فاصله نزدیکی به همدیگر واقع شدهاند. این الگوریتمها داده پرتها را نیز در مناطقی با تراکم پایین تعیین میکنند. خوشبختانه، HDBSCAN از طول جغرافیایی و عرض جغرافیایی هم پشتیبانی میکند. بنابراین، زمینه برای محاسبه میان موقعیتهای جغرافیایی فراهم میآید.
HDBSCAN در نسخه عادی پایتون منظور نشده است، پس مجبورید آن را به صورت pip یا conda نصب کنید. پس از این کار کد زیر را به جرا درآوردیم. سرانجام، دیتافریم و نمودار پراکندگی زیر به دست آمد. همان طور که ملاحظه میکنید، نقاط مجزا در خوشه ۱- جای دارند؛ پس این نقاط «نویز» به حساب میآیند.
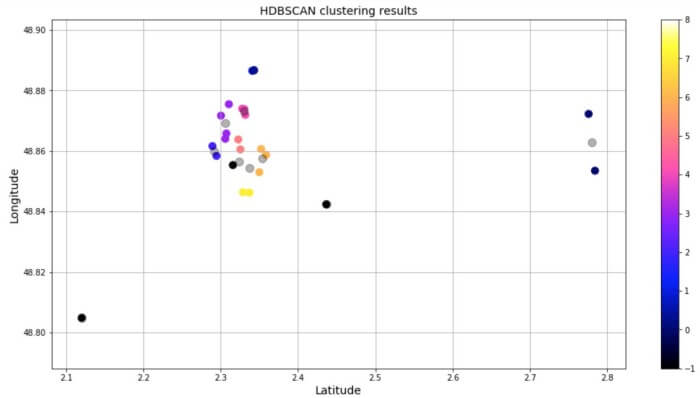
HDBSCAN نه خوشه و سه نقطه داده به عنوان «نویز» ایجاد کرد.
نتایج HDBSCAN (روزهای سفر در هفته – فقط سه روز اول نشان داده شده است.)
اصلاً تعجببرانگیز نیست که چندین نقطه به عنوان نویز وجود داشته باشد. چون حداقل تعداد نقاط در خوشه HDBSCAN برابر است با ۲، نقاط مجزا از قبیل کاخ ورسای به عنوان نویز طبقهبندی شدهاند. مکانهایی نظیر کلیسای Sainte-Chapelle de Vincennes و موزه Musée Rodin با سرنوشت مشابهی روبرو شدند. اما نکته جالب به تعداد خوشههایی مربوط میشود که HDBSCAN شناسایی کرد (یعنی ۹ عدد). روش خوشهبندیِ مورد استفاده در این پست آموزشی میتواند ارتقاء یابد. برای نمونه، میتوان ویژگی وزن را در نقاط داده به کار برد. وزنها میتوانند مقدار زمان مورد نیاز برای بازدید از یک مکان دیدنی را نشان دهند. به این ترتیب، تعداد کل نقاط داده در خوشه تحت تاثیر قرار میگیرد.
منبع: hooshio.com
چگونه دیتاست های نامتوازن را در یادگیری عمیق مدیریت کنیم؟
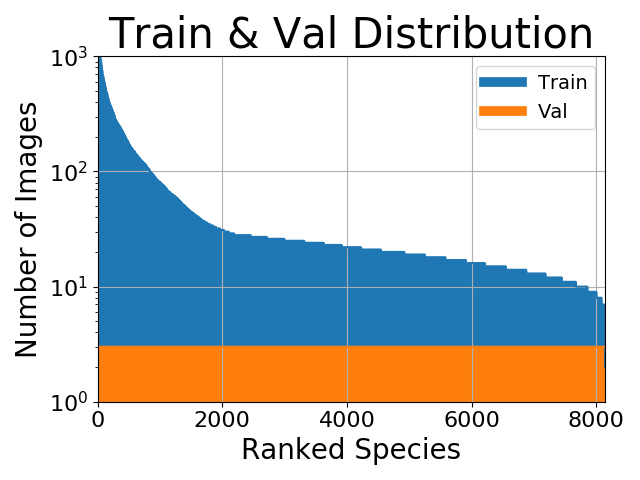
همیشه همه دادهها کامل و خالی از عیب و نقص نیستند. اگر دیتاست کاملاً متوازنی در اختیار داشته باشید، آدم بسیار خوششانسی هستید در غیر این صورت مدیریت دیتاست های نامتوازن اهمیت بسیاری پیدا میکند. اکثر مواقع، دادهها تا حدی نامتوازن هستند. این مورد زمانی اتفاق میافتد که هر کدام از دستهها تعداد نمونههای متفاوتی داشته باشند.
چرا ما بیشتر تمایل داریم تا دادههای متوازن داشته باشیم؟
پیش از آنکه زمان زیادی برای انجام پروژههای طولانی یادگیری عمیق اختصاص دهید، باید بدانید که هدف از انجام این کار چیست. کسب این دانش باید آنقدر با اهمیت باشد و بیارزد که ارزش وقت گذاشتن را داشته باشد. روشهای متوازنکردن دستههای دیتاست تنها زمانی ضروری هستند که دستههای اقلیت را مورد توجه قرار دهیم. برای نمونه، فرض کنید میخواهیم بدانیم که آیا خرید مسکن با توجه به شرایط فعلی بازار، خصوصیات مسکن و توان مالیمان منطقی است یا خیر. اگر مدل، عدم خرید خانه را به ما توصیه کند، فرق چندانی نخواهد کرد. در این مورد، اگر در خرید مسکن موفق شویم، گام مهمی برداشتهایم چرا که سرمایهگذاری عظیمی به شمار میآید. اگر در خرید مسکن دلخواهمان موفق نشویم، این فرصت را داریم که دنبال موارد دیگر باشیم. در صورتی که به اشتباه روی چنین دارایی بزرگی سرمایهگذاری کنیم، یقیناً باید منتظر پیامدهای کارمان بمانیم.
در این مثال، نیاز داریم که دسته “خرید” که در اقلیت هستند بسیار بسیار دقیق تعیین شده باشند، اما برای دسته «عدم خرید» این مورد اهمیت چندانی ندارد (چون به اندازه کافی داده در این دسته وجود دارد). از آنجا که «خرید» در دادههای ما نادر است، مدلمان در یادگیری دستۀ «عدم خرید» سوگیری خواهد داشت زیرا بیشترین داده را دارد و احتمال میرود عملکرد ضعیفی در دسته «خرید» بر جای بگذارد. به همین منظور، لازم است دادههای خود را متوازن کنیم. اگر دستههای اقلیت را مورد بیتوجهی قرار دهیم، چه اتفاقی رخ میدهد؟ برای مثال، فرض کنید در حال دستهبندی تصاویر هستیم و توزیع دسته به شکل زیر در آمده است:
دیتاست های نامتوازن
در نگاه اول، به نظر میرسد که متوازنکردن دادهها میتواند نقش سودمندی داشته باشد. اما شاید علاقه چندانی به آن دستههای اقلیت نداشته باشیم. یا شاید هدف اصلیمان این است که بالاترین درصد دقت را رقم بزنیم. در این صورت، متوازن کردن دادهها منطقی نیست زیرا دستههایی که نمونههای آموزشی بیشتری داشته باشند، میزان دقت را بالا خواهند برد. در ثانی، توابع آنتروپی متقاطع در شرایطی بهترین عملکردشان را دارند که بالاترین درصد دقت را به دست آورند؛ حتی زمانی که دیتاست های نامتوازن باشد. روی هم رفته، دستههای اقلیتمان نقش قابل توجهی در تحقق هدف اصلیمان ندارد؛ بنابراین، متوازن کردن ضرورت چندانی ندارد. با توجه به همه مطالبی که تا به اینجا ذکر شد، اگر با موردی مواجه شویم که نیاز باشد دادههایمان را متوازن کنیم، میتوانیم از دو روش برای تحقق هدفمان استفاده کنیم.
روش «متوازن کردن وزن »
روش «متوازن کردن وزن» با تغییر وزنهای هر نمونه آموزشی سعی در متوازن کردنِ دادهها دارد. در حالت عادی، هر نمونه و دسته در تابع زیان وزن یکسانی خواهد داشت. اما اگر برخی دستهها یا نمونههای آموزشی اهمیت بیشتری داشته باشند، وزن بیشتری خواهند داشت. بگذارید یک بار دیگر به مثال فوق در رابطه با خرید مسکن اشاره کنیم. به دلیل اینکه دقتِ دستۀ «خرید» برایمان اهمیت دارد، انتظار میرود نمونههای آموزشیِ آن دسته تاثیر بسزایی بر تابع زیان داشته باشند.
با ضرب زیان هر نمونه به ضریبی معین (بسته به دستهها)، میتوان به دستهها وزن داد. میتوان در Keras اقدام به چنین کاری کرد:
۱
۲
۳
۴
import keras
class_weight = {"buy": ۰.۷۵,
"don't buy": ۰.۲۵}
model.fit(X_train, https://hooshio.com/%da%۸۶%da%af%d9%۸۸%d9%۸۶%d9%۸۷-%d8%af%db%۸c%d8%aa%d8%a7%d8%b3%d8%aa-%d9%۸۷%d8%a7%db%۸c-%d9%۸۶%d8%a7%d9%۸۵%d8%aa%d9%۸۸%d8%a7%d8%b2%d9%۸۶-%d8%b1%d8%a7-%d8%af%d8%b1-%db%۸c%d8%a7%d8%af%da%af%db%۸c%d8%b1/Y_train, epochs=۱۰, batch_size=۳۲, class_weight=class_weight)
در کد بالا در متغیری که تحت عنوان class_weight تعریف کردیم ، دستۀ «خرید» باید ۷۵ درصد از وزنِ تابع زیان را داشته باشد چرا که اهمیت بیشتری دارد. دستۀ «عدم خرید» نیز باید ۲۵ درصد باقیمانده را به خود اختصاص دهد. البته امکان دستکاری و تغییر این مقادیر برای ایجاد مناسبترین شرایط وجود دارد. اگر یکی از دستههایمان نمونههای بیشتری از دیگری داشته باشد، میتوانیم از این روش متوازنسازی استفاده کنیم. به جای اینکه زمان و منابع خود را به جمعآوری بیشتر دستههای اقلیت اختصاص دهیم، میتوانیم شرایطی را رقم بزنیم که طی آن، روش متوازنسازی وزن همه دستهها را وادار کند به میزان یکسان در تابع زیان نقش داشته باشند.
یکی دیگر از روشها برای متوازن کردن وزن نمونههای آموزشی، «زیان کانونی» نام دارد. بیایید جزئیات کار را با هم بررسی کنیم: ما در دیتاستمان چند نمونه آموزشی داریم که دستهبندی راحتتری در مقایسه با بقیه دارند. در طی فرایند آموزش، این نمونهها با ۹۹ درصد دقت دستهبندی خواهند شد، اما شاید نمونههای دیگر عملکرد بسیار ضعیفی داشته باشند. مشکل این است که آن دسته از نمونههای آموزشی که به راحتی دستهبندی شدهاند، کماکان در تابع زیان به ایفای نقش میپردازند. اگر دادههای چالشبرانگیز بسیاری وجود دارد که در صورت دستهبندی درست میتوانند دقت کار را تا حد زیادی بالا ببرند، چرا باید وزن برابری به آنها بدهیم؟
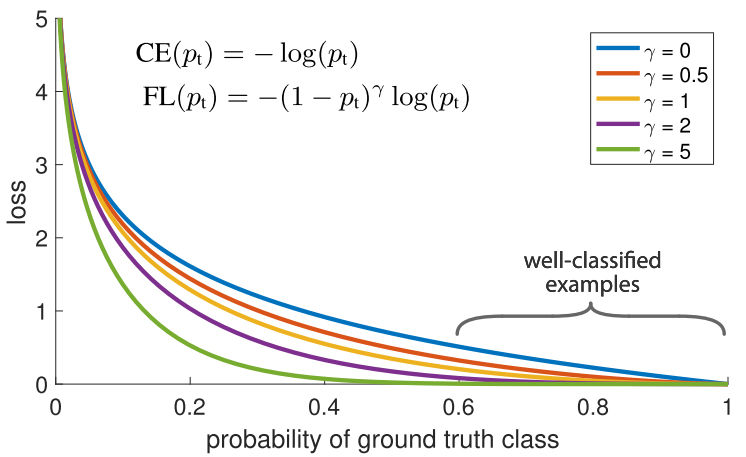
«زیان کانونی» دقیقاً برای حل چنین مسئلهای در نظر گرفته شده است. زیان کانونی به جای اینکه وزن برابری به همه نمونههای آموزشی دهد، وزن نمونههای دستهبندی شده با دقت بالا (داده هایی که دسته بندی شان به راحتی برای شبکه امکان پذیر است) را کاهش میدهد. پس دادههایی که دستهبندی آنها به سختی انجام میشود، مورد تاکید قرار میگیرند. در عمل، وقتی با عدم توازن دادهها روبرو هستیم، دسته اکثریتمان به سرعت دستهبندی میشود زیرا دادههای زیادی برای آن داریم. بنابراین، برای اینکه مطمئن شویم دقت بالایی در دسته اقلیت حاصل میآید، میتوانیم از تابع زیان استفاده کنیم تا وزن بیشتری به نمونه دستههای اقلیت داده شود. تابع زیان میتواند به راحتی در Keras به اجرا درآید.
۱
۲
۳
۴
۵
۶
۷
۸
۹
۱۰
۱۱
۱۲
import keras
from keras import backend as K
import tensorflow as tf
# Define our custom loss function
def focal_loss(y_true, y_pred):
gamma = ۲.۰, alpha = ۰.۲۵https://hooshio.com/%da%۸۶%da%af%d9%۸۸%d9%۸۶%d9%۸۷-%d8%af%db%۸c%d8%aa%d8%a7%d8%b3%d8%aa-%d9%۸۷%d8%a7%db%۸c-%d9%۸۶%d8%a7%d9%۸۵%d8%aa%d9%۸۸%d8%a7%d8%b2%d9%۸۶-%d8%b1%d8%a7-%d8%af%d8%b1-%db%۸c%d8%a7%d8%af%da%af%db%۸c%d8%b1/
pt_1 = tf.where(tf.equal(y_true, ۱), y_pred, tf.ones_like(y_pred))
pt_0 = tf.where(tf.equal(y_true, ۰), y_pred, tf.zeros_like(y_pred))
return -K.sum(alpha * K.pow(۱. - pt_1, gamma) * K.log(pt_1))-K.sum((۱-alpha) * K.pow( pt_0, gamma) * K.log(۱. - pt_0))
# Compile our model
adam = Adam(lr=۰.۰۰۰۱)
model.compile(loss=[focal_loss], metrics=["accuracy"], optimizer=adam)
روشهای نمونهگیری OVER-SAMPLING و UNDER-SAMPLING
انتخاب وزن دسته مناسب از جمله کارهای پیچیده است. فرایند «فراوانی معکوس» همیشه جوابگو نیست. زیان کانونی میتواند مفید واقع شود، اما حتی این راهکار نیز باعث خواهد شد همه نمونههایی که به خوبی دستهبندی شدهاند، با کاهش وزن روبرو شوند. از این رو، یکی دیگر از روشهای برقراری توازن در دادهها، انجام مستقیمِ آن از طریق نمونهگیری است. به تصویر زیر توجه داشته باشید.
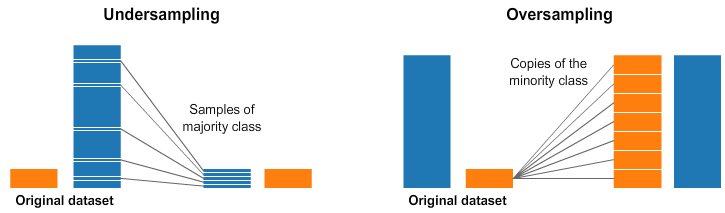
Under and and Over Sampling
در سمت چپ و راست تصویر فوق، دسته آبی نمونههای بیشتری نسبت به دسته نارنجی دارد. در این مورد، دو گزینه پیشپردازش وجود دارد که میتواند به آموزش مدلهای یادگیری ماشین کمک کند. روش Under-sampling بدین معناست که تنها بخشی از دادهها را از دسته اکثریت انتخاب میکنیم. این گزینش باید برای حفظ توزیع احتمال دسته انجام شود. چقدر راحت! نمونههای کمتر باعث میشود دیتاست متوازن گردد. روش Oversampling هم به این معناست که نسخههایی از دسته اقلیت ایجاد خواهد شد. هدف از این کار، ایجاد تساویِ تعداد نمونه دستههای اقلیت با اکثریت است. ما موفق شدیم دیتاست های نامتوازن را بدون کسب دادههای بیشتر متوازن کنیم!
منبع: hooshio.com
همیشه همه دادهها کامل و خالی از عیب و نقص نیستند. اگر دیتاست کاملاً متوازنی در اختیار داشته باشید، آدم بسیار خوششانسی هستید در غیر این صورت مدیریت دیتاست های نامتوازن اهمیت بسیاری پیدا میکند. اکثر مواقع، دادهها تا حدی نامتوازن هستند. این مورد زمانی اتفاق میافتد که هر کدام از دستهها تعداد نمونههای متفاوتی داشته باشند.
چرا ما بیشتر تمایل داریم تا دادههای متوازن داشته باشیم؟
پیش از آنکه زمان زیادی برای انجام پروژههای طولانی یادگیری عمیق اختصاص دهید، باید بدانید که هدف از انجام این کار چیست. کسب این دانش باید آنقدر با اهمیت باشد و بیارزد که ارزش وقت گذاشتن را داشته باشد. روشهای متوازنکردن دستههای دیتاست تنها زمانی ضروری هستند که دستههای اقلیت را مورد توجه قرار دهیم. برای نمونه، فرض کنید میخواهیم بدانیم که آیا خرید مسکن با توجه به شرایط فعلی بازار، خصوصیات مسکن و توان مالیمان منطقی است یا خیر. اگر مدل، عدم خرید خانه را به ما توصیه کند، فرق چندانی نخواهد کرد. در این مورد، اگر در خرید مسکن موفق شویم، گام مهمی برداشتهایم چرا که سرمایهگذاری عظیمی به شمار میآید. اگر در خرید مسکن دلخواهمان موفق نشویم، این فرصت را داریم که دنبال موارد دیگر باشیم. در صورتی که به اشتباه روی چنین دارایی بزرگی سرمایهگذاری کنیم، یقیناً باید منتظر پیامدهای کارمان بمانیم.
در این مثال، نیاز داریم که دسته “خرید” که در اقلیت هستند بسیار بسیار دقیق تعیین شده باشند، اما برای دسته «عدم خرید» این مورد اهمیت چندانی ندارد (چون به اندازه کافی داده در این دسته وجود دارد). از آنجا که «خرید» در دادههای ما نادر است، مدلمان در یادگیری دستۀ «عدم خرید» سوگیری خواهد داشت زیرا بیشترین داده را دارد و احتمال میرود عملکرد ضعیفی در دسته «خرید» بر جای بگذارد. به همین منظور، لازم است دادههای خود را متوازن کنیم. اگر دستههای اقلیت را مورد بیتوجهی قرار دهیم، چه اتفاقی رخ میدهد؟ برای مثال، فرض کنید در حال دستهبندی تصاویر هستیم و توزیع دسته به شکل زیر در آمده است:
دیتاست های نامتوازن
در نگاه اول، به نظر میرسد که متوازنکردن دادهها میتواند نقش سودمندی داشته باشد. اما شاید علاقه چندانی به آن دستههای اقلیت نداشته باشیم. یا شاید هدف اصلیمان این است که بالاترین درصد دقت را رقم بزنیم. در این صورت، متوازن کردن دادهها منطقی نیست زیرا دستههایی که نمونههای آموزشی بیشتری داشته باشند، میزان دقت را بالا خواهند برد. در ثانی، توابع آنتروپی متقاطع در شرایطی بهترین عملکردشان را دارند که بالاترین درصد دقت را به دست آورند؛ حتی زمانی که دیتاست های نامتوازن باشد. روی هم رفته، دستههای اقلیتمان نقش قابل توجهی در تحقق هدف اصلیمان ندارد؛ بنابراین، متوازن کردن ضرورت چندانی ندارد. با توجه به همه مطالبی که تا به اینجا ذکر شد، اگر با موردی مواجه شویم که نیاز باشد دادههایمان را متوازن کنیم، میتوانیم از دو روش برای تحقق هدفمان استفاده کنیم.
روش «متوازن کردن وزن »
روش «متوازن کردن وزن» با تغییر وزنهای هر نمونه آموزشی سعی در متوازن کردنِ دادهها دارد. در حالت عادی، هر نمونه و دسته در تابع زیان وزن یکسانی خواهد داشت. اما اگر برخی دستهها یا نمونههای آموزشی اهمیت بیشتری داشته باشند، وزن بیشتری خواهند داشت. بگذارید یک بار دیگر به مثال فوق در رابطه با خرید مسکن اشاره کنیم. به دلیل اینکه دقتِ دستۀ «خرید» برایمان اهمیت دارد، انتظار میرود نمونههای آموزشیِ آن دسته تاثیر بسزایی بر تابع زیان داشته باشند.
با ضرب زیان هر نمونه به ضریبی معین (بسته به دستهها)، میتوان به دستهها وزن داد. میتوان در Keras اقدام به چنین کاری کرد:
۱ ۲ ۳ ۴ | import keras class_weight = {"buy": ۰.۷۵, "don't buy": ۰.۲۵} model.fit(X_train, https://hooshio.com/%da%۸۶%da%af%d9%۸۸%d9%۸۶%d9%۸۷-%d8%af%db%۸c%d8%aa%d8%a7%d8%b3%d8%aa-%d9%۸۷%d8%a7%db%۸c-%d9%۸۶%d8%a7%d9%۸۵%d8%aa%d9%۸۸%d8%a7%d8%b2%d9%۸۶-%d8%b1%d8%a7-%d8%af%d8%b1-%db%۸c%d8%a7%d8%af%da%af%db%۸c%d8%b1/Y_train, epochs=۱۰, batch_size=۳۲, class_weight=class_weight) |
در کد بالا در متغیری که تحت عنوان class_weight تعریف کردیم ، دستۀ «خرید» باید ۷۵ درصد از وزنِ تابع زیان را داشته باشد چرا که اهمیت بیشتری دارد. دستۀ «عدم خرید» نیز باید ۲۵ درصد باقیمانده را به خود اختصاص دهد. البته امکان دستکاری و تغییر این مقادیر برای ایجاد مناسبترین شرایط وجود دارد. اگر یکی از دستههایمان نمونههای بیشتری از دیگری داشته باشد، میتوانیم از این روش متوازنسازی استفاده کنیم. به جای اینکه زمان و منابع خود را به جمعآوری بیشتر دستههای اقلیت اختصاص دهیم، میتوانیم شرایطی را رقم بزنیم که طی آن، روش متوازنسازی وزن همه دستهها را وادار کند به میزان یکسان در تابع زیان نقش داشته باشند.
یکی دیگر از روشها برای متوازن کردن وزن نمونههای آموزشی، «زیان کانونی» نام دارد. بیایید جزئیات کار را با هم بررسی کنیم: ما در دیتاستمان چند نمونه آموزشی داریم که دستهبندی راحتتری در مقایسه با بقیه دارند. در طی فرایند آموزش، این نمونهها با ۹۹ درصد دقت دستهبندی خواهند شد، اما شاید نمونههای دیگر عملکرد بسیار ضعیفی داشته باشند. مشکل این است که آن دسته از نمونههای آموزشی که به راحتی دستهبندی شدهاند، کماکان در تابع زیان به ایفای نقش میپردازند. اگر دادههای چالشبرانگیز بسیاری وجود دارد که در صورت دستهبندی درست میتوانند دقت کار را تا حد زیادی بالا ببرند، چرا باید وزن برابری به آنها بدهیم؟
«زیان کانونی» دقیقاً برای حل چنین مسئلهای در نظر گرفته شده است. زیان کانونی به جای اینکه وزن برابری به همه نمونههای آموزشی دهد، وزن نمونههای دستهبندی شده با دقت بالا (داده هایی که دسته بندی شان به راحتی برای شبکه امکان پذیر است) را کاهش میدهد. پس دادههایی که دستهبندی آنها به سختی انجام میشود، مورد تاکید قرار میگیرند. در عمل، وقتی با عدم توازن دادهها روبرو هستیم، دسته اکثریتمان به سرعت دستهبندی میشود زیرا دادههای زیادی برای آن داریم. بنابراین، برای اینکه مطمئن شویم دقت بالایی در دسته اقلیت حاصل میآید، میتوانیم از تابع زیان استفاده کنیم تا وزن بیشتری به نمونه دستههای اقلیت داده شود. تابع زیان میتواند به راحتی در Keras به اجرا درآید.
۱ ۲ ۳ ۴ ۵ ۶ ۷ ۸ ۹ ۱۰ ۱۱ ۱۲ | import keras from keras import backend as K import tensorflow as tf # Define our custom loss function def focal_loss(y_true, y_pred): gamma = ۲.۰, alpha = ۰.۲۵https://hooshio.com/%da%۸۶%da%af%d9%۸۸%d9%۸۶%d9%۸۷-%d8%af%db%۸c%d8%aa%d8%a7%d8%b3%d8%aa-%d9%۸۷%d8%a7%db%۸c-%d9%۸۶%d8%a7%d9%۸۵%d8%aa%d9%۸۸%d8%a7%d8%b2%d9%۸۶-%d8%b1%d8%a7-%d8%af%d8%b1-%db%۸c%d8%a7%d8%af%da%af%db%۸c%d8%b1/ pt_1 = tf.where(tf.equal(y_true, ۱), y_pred, tf.ones_like(y_pred)) pt_0 = tf.where(tf.equal(y_true, ۰), y_pred, tf.zeros_like(y_pred)) return -K.sum(alpha * K.pow(۱. - pt_1, gamma) * K.log(pt_1))-K.sum((۱-alpha) * K.pow( pt_0, gamma) * K.log(۱. - pt_0)) # Compile our model adam = Adam(lr=۰.۰۰۰۱) model.compile(loss=[focal_loss], metrics=["accuracy"], optimizer=adam) |
روشهای نمونهگیری OVER-SAMPLING و UNDER-SAMPLING
انتخاب وزن دسته مناسب از جمله کارهای پیچیده است. فرایند «فراوانی معکوس» همیشه جوابگو نیست. زیان کانونی میتواند مفید واقع شود، اما حتی این راهکار نیز باعث خواهد شد همه نمونههایی که به خوبی دستهبندی شدهاند، با کاهش وزن روبرو شوند. از این رو، یکی دیگر از روشهای برقراری توازن در دادهها، انجام مستقیمِ آن از طریق نمونهگیری است. به تصویر زیر توجه داشته باشید.
Under and and Over Sampling
در سمت چپ و راست تصویر فوق، دسته آبی نمونههای بیشتری نسبت به دسته نارنجی دارد. در این مورد، دو گزینه پیشپردازش وجود دارد که میتواند به آموزش مدلهای یادگیری ماشین کمک کند. روش Under-sampling بدین معناست که تنها بخشی از دادهها را از دسته اکثریت انتخاب میکنیم. این گزینش باید برای حفظ توزیع احتمال دسته انجام شود. چقدر راحت! نمونههای کمتر باعث میشود دیتاست متوازن گردد. روش Oversampling هم به این معناست که نسخههایی از دسته اقلیت ایجاد خواهد شد. هدف از این کار، ایجاد تساویِ تعداد نمونه دستههای اقلیت با اکثریت است. ما موفق شدیم دیتاست های نامتوازن را بدون کسب دادههای بیشتر متوازن کنیم!
منبع: hooshio.com
هوش مصنوعی در کسب و کار ؛ فرصتها و چالشها
بررسی چالشها و فرصت های هوش مصنوعی در کسب و کار را با چند سوال آغاز میکنیم:
• کسب و کارها برای اجرای هوش مصنوعی با چه فرصتها و چالشهایی روبرو هستند؟
• آیا از بکارگیری فناوریهای هوش مصنوعی در کسب و کار خودتان تردید دارید؟
• هوش مصنوعی چه تاثیری روی رشد و سودآوری کسب و کار شما گذاشته است؟امروزه حتی انسانهای عادی نیز به درک قابلیتهای هوش مصنوعی رغبت نشان میدهند. دلیل چنین تمایلی را میتوان در این امر جستجو کرد که هوش مصنوعی تمامی جنبههای زندگی ما را تحتالشعاع قرار داده است. ظاهراً این فناوری توانسته اشتیاق و تردید را به طور همزمان در انسانها برانگیزد. البته معیارهای مختلفی در آن دخیل است! حال بیایید آمار و حقایق مربوط به هوش مصنوعی را بررسی کنیم:• فناوری هوش مصنوعی میتواند بهرهوری کسب و کار را تا ۴۰ درصد افزایش دهد (منبع: Accenture).
• تعداد استارتآپهای هوش مصنوعی از سال ۲۰۰۰ به میزان چهارده برابر افزایش یافته است (Forbes).
• هوش مصنوعی باعث خواهد شد ۱۶ درصد از مشاغل در آمریکا توسط ماشینها انجام شود (Forrester).
• ۱۵ درصد کسب و کارها از هوش مصنوعی استفاده میکنند. ۳۱ درصد از کسب و کارها اعلام کردهاند که بکارگیری هوش مصنوعی تا ۱۲ ماه آینده در دستور کارشان قرار دارد (Adobe).کاملاً مبرهن است که هوش مصنوعی فقط به آزمایشگاههای نوآوری محدود نمیشود. این فناوری به دلیل قابلیت بالایی که در متحول ساختنِ کسب و کارها دارد، تحسین همگان را برانگیخته است. با این حال، کسب و کارها پیش از آنکه از ظرفیتهای واقعی این فناوری در کسب و کارهایشان بهره گیرند، باید خود را آماده رویارویی با چند چالش نمایند.
بکارگیری هوش مصنوعی در کسب و کار با چالشهای بسیاری همراه است.
۱. محاسبه یا رایانش چندان پیشرفته نیست!
روشهای یادگیری عمیق و یادگیری ماشین در نگاه اول از فواید بسیاری برخوردارند، اما برای اینکه سرعت عمل بالایی داشته باشد، باید یک سری محاسبات را پشت سر بگذارند. کاملاً مشهود است که این روشهای هوش مصنوعی به قدرت پردازش قابل ملاحظهای نیاز دارند. هوش مصنوعی برای چندین سال در محافل علمی و تخصصی مورد بحث و بررسی قرار گرفته است. همواره محققان و کارشناسان این مسئله را به پیش کشیدهاند که کماکان قدرت لازم برای اجرای این قبیل از روشهای هوش مصنوعی در دسترس نیست. رایانش ابری و سیستمهای پردازش موازی در کوتاهمدت این امیدواری را در دل همگان ایجاد کردهاند که اجرای روشهای مصنوعی سرانجام میتواند با موفقیت همراه باشد؛ اما با افزایش حجم دادهها و ایجاد الگوریتمهای فوقالعاده پیچیده توسط روشهای یادگیری عمیق، نمیتوان فقط به رایانش ابری دل بست.
| فواید احتمالی هوش مصنوعی | چالشها و ریسکهای هوش مصنوعی |
| • انجام کارهای تکراری و ملالآور • انجام کارهای پیچیده، تنها در کسری از ثانیه • تولید نتایج قابل درک • بکارگیری ماشینهای هوش مصنوعی در محیطهای خطرناک و کاهش خطرات جانی برای انسانها • ایفای نقش مکمل در انجام امور • قابل اطمینانتر بودن سیستمهای هوش مصنوعی نسبت به انسان | • توسعه آن دسته از سیستمهای هوش مصنوعی که قدرت تفکر دارند، در حال حاضر کار دشواری است. • استفاده وسیع از هوش مصنوعی باعث بروز یک سری مسائل اخلاقی و حقوقی شده است. تلاشها برای رفع این مسائل کماکان ادامه دارد. • فقط مالکان سرمایههای عظیم از مزایا و منافع فناوریهای هوش مصنوعی بهرهمند میشوند. • تاثیر منفی روی مهارتهای سنتی و افزایش نابرابری |
۲. حمایت مردمیِ ناچیز
موارد استفاده از هوش مصنوعی در بازار اندک است. به عبارت دیگر، سازمانهای انگشتشماری به سرمایهگذاری در توسعه محصولات هوش مصنوعی ابراز علاقه کردهاند. افزون بر این، سایر کسب و کارها نمیتوانند این واقعیت را بپذیرند که جهان با سرعت قابل ملاحظهای به سوی ماشینی شدن پیش میرود و نباید از این قافله عقب ماند. عده بسیار اندکی میدانند که ماشینها چگونه فکر کرده و خودشان اقدام به یادگیری میکنند. در همین راستا، میتوان پلتفرمها و ابزارهایی را به کار بست که زمینه را برای انجام کارهای هوش مصنوعی در قالب خدمات فراهم میکنند. سازمانها به جای اینکه همه کارها را از صفر شروع کنند، میتوانند از راهحلهای آماده استفاده کنند.
۳. اعتمادسازی
یکی از مشکلات هوش مصنوعی این است که همه آن را به عنوان جعبه سیاه در نظر میگیرند. وقتی افراد از نحوه تصمیمگیری سر در نیاورند، احساس راحتی نمیکنند. برای نمونه، بانکها از الگوریتمهای سادهای استفاده میکنند که بر پایه ریاضی خطی است. بنابراین، میتوان الگوریتم و چگونگی ارائه واکنش از ورودی تا خروجی را به راحتی توضیح داد. متاسفانه، هوش مصنوعی در امرِ اعتمادسازی عملکرد درخشانی نداشته است. تنها راهحل ممکن برای این مشکل این است که کارآیی این فناوری برای افراد نشان داده شود. با این حال، واقعیت قدری متفاوت است. فرصتهای فراوانی برای بهبود وضعیت وجود دارد . پیشبینیهای دقیق هوش مصنوعی میتواند نقش بیبدیلی در تحقق این امر داشته باشد. البته این مورد به مذاق دولتها خوش نخواهد آمد. قانونی را تصور کنید که این حقوق را به افراد اعطا میکند تا با تکیه بر هوش مصنوعی، درباره تصمیمات اتخاذ شده توسط دولت از او توضیح بخواهند.
۴. تفکر یکبعدی
یکی از مسائل بزرگی که باید مد نظر قرار داد این است که اکثر موارد استفاده از هوش مصنوعی جنبه تخصصی دارند. هوش مصنوعی تخصصی با عنوان «هوش مصنوعی کاربردی» نیز شناخته میشود. هوش مصنوعی کاربردی فقط برای انجام یک کار ساخته شده و در انجام همین کار سعی میکند بهتر و بهتر شود. هوش مصنوعی در این فرایند به ورودیها ارائه شده و نتایج بدست آمده توجه میکند. لذا بهترین نتایج را مورد بررسی قرار داده و مقادیر ورودی را یادداشت میکند. هوش مصنوعی تعمیمیافته جنبههای متفاوتی را در برمیگیرد و توان انجام امور مختلفی را دارد. اما برای تحقق این اهداف باید صبر کرد. سیستمهای هوش مصنوعی باید به گونهای آموزش داده شوند که از بروز مشکلات دیگر توسط آنها اطمینان حاصل گردد.
۵. قابلیت اثبات
سازمانهایی که محصولات هوش مصنوعی را در دستور کارشان قرار دادهاند، نمیتوانند به روشنی درباره چشماندازها و دستاوردهایشان به کمک روشهای هوش مصنوعی سخن بگویند. افراد کماکان درباره چگونگی اتخاذ تصمیم توسط این فناوری با دیدۀ تردید مینگرند؛ این مسئله در اذهان عمومی هست که آیا تصمیمات هوش مصنوعی همگی بیعیب و نقص است یا خیر. سازمانها در حال حاضر با آغوش باز به استقبال پیشبینیهای هوش مصنوعی نمیروند و جانب احتیاط را در این خصوص رعایت میکنند. سازمانها با اِثبات این قضیه مشکل دارند که فرایند تصمیمگیری سیستمهای هوش مصنوعی بی هیچ عیب و نقصی پیش میرود. باید هوش مصنوعی قابل تبیین، قابل اثبات و شفاف باشد. سازمانها باید آن دسته از سیستمهای هوش مصنوعی را به کار گیرند که قابل تبیین باشد.
۶. امنیت و حریم خصوصی دادهها
سیستمهای هوش مصنوعی عمدتاً به حجم قابل ملاحظهای داده برای یادگیری و اتخاذ تصمیمهای هوشمندانه نیاز دارند. سیستمهای یادگیری ماشین به داده وابستهاند؛ داده نیز غالبا! ماهیت حساس و فردی دارد. این سیستمها از روی داده اقدام به یادگیری کرده و خود را ارتقاء میبخشند. به دلیل این نوع یادگیری سیستماتیک، این سیستمهای یادگیری ماشین در معرض سرقت هویت و نقض داده قرار میگیرند. اتحادیه اروپا قانونی تحت عنوان «قانون عمومی محافظت از اطلاعات» تصویب کرده تا از محافظت کامل از دادههای فردی اطمینان حاصل کند. این اقدام بلافاصله پس از افزایش آگاهی افراد درباره طیف فزایندۀ تصمیمات ماشین به انجام رسید. علاوه بر این، روش منحصربفردی موسوم به یادگیری فدراسیونی وجود دارد که سعی در مختل کردن پارادایم هوش مصنوعی دارد. یادگیری فدراسیونی دانشمندان داده را ترغیب میکند تا سیستمهای هوش مصنوعی را بدون تحت تاثیر قرار دادنِ امنیت داده کاربران بسازند.
۷. سوگیری الگوریتم
یکی از مسائل بزرگی که سیستمهای هوش مصنوعی با خود به همراه دارند این است که میزان خوب یا بد بودنشان به حجم دادههایی بستگی دارد که با آنها آموزش دیدهاند. دادههای بد دارای سوگیریهای نژادی، جنسیتی، قومیتی و … هستند. الگوریتمهای اختصاصی کاربردهای مختلفی دارند که از جمله آنها میتوان به این موارد اشاره کرد: چه کسی بسته مالی ارائه کرد؟ چه نهادی به اعطای وام پرداخته است؟ و … اگر سوگیری به صورت پنهان در الگوریتم باقی بماند و تصمیمهای حیاتی را تحتالشعاع قرار دهد، میتوان انتظار داشت که نتایج غیراخلاقی و غیرمنصفانه به بار آید. کارشناسان بر این باورند که این سوگیریها در آینده افزایش خواهد یافت زیرا سیستمهای هوش مصنوعی کماکان به استفاده از دادههای بد ادامه میدهند. بنابراین، سازمانهایی که هوش مصنوعی را در محوریت کارهای خود قرار دادهاند، باید این سیستمها را به کمک دادههای بدون سوگیری آموزش دهند و الگوریتمهایی را بسازند که به راحتی قابل توضیح باشند.
۸. امنیت داده
این واقعیت غیرقابل انکار است که امروزه سازمانها به حجم بسیار بالایی از دادهها نسبت به گذشته دسترسی دارند. با این حال، دیتاستهایی که در نرمافزارهای هوش مصنوعی با هدف یادگیری به کار برده میشوند، خیلی نادر هستند. این نوع یادگیری مستلزم دادههای برچسبدار میباشد. دادههای برچسبدار ساختاریافته هستند و ماشینها به راحتی میتوانند از آن دادهها برای یادگیری استفاده کنند. علاوه بر این، دادههای برچسبدار محدودیت دارند. احتمال میرود ساخت خودکار الگوریتمهای پیچیده در آینده به وخامت این مسئله بیفزاید. خوشبختانه، کماکان بارقهای از امید وجود دارد. سازمانها در حال سرمایهگذاری بر روی روشهای طراحی هستند و علیرغم کمیاب بودن دادههای برچسبدار، تمرکزشان را روی مدلهای هوش مصنوعی معطوف ساختهاند.
فرصت های هوش مصنوعی در حوزه کسب و کار
بکارگیری سیستمهای هوش مصنوعی در حوزه کسب و کار با ریسکها و چالشهای بسیاری همراه است. اما مثل دو روی متفاوت سکه، هوش مصنوعی میتواند فرصتهای متعددی برای کسب و کارها به ارمغان آورَد. به لطف فرصتهایی که هوش مصنوعی پدید آورده، توسعهدهندگان کاربلد هندی در بسیاری از کسب و کارها استخدام میشوند تا نرمافزارهای هوش مصنوعی اختصاصیشان را ایجاد کنند. بگذارید تکتک این موارد را بررسی کنیم.
۱. هوش مصنوعی در بازاریابی
همه کسب و کارهای کوچک رویایِ کاهش بودجه بازاریابی و تمرکز بر روی راهبردهای کارآمدِ بازاریابی را در سر میپرورانند. علاوه بر این، شرکتها راغب هستند بدانند کدام فعالیتهای بازاریابی بیشترین سودآوری را به همراه دارد. اما تجزیه و تحلیل دادهها در میان همه کانالهای رسانهای کار دشواری است و زمان بسیاری را میطلبد. اینجاست که هوش مصنوعی به ارائه راهحلهای بازاریابی میپردازد! پلتفرمهای هوش مصنوعی از قبیل Acquisio نقش بسیار مهمی در مدیریت عملیات بازاریابی دارند؛ به ویژه در کانالهای گوناگونی نظیر Google Adwords، فیسبوک و Bing.
۲. استفاده از روشهای هوش مصنوعی برای ردیابی رقبا
همیشه باید بدانید رقبایتان در چه وضعیتی به سر میبرند و چه سیاستهایی در پیش گرفتهاند. شوربختانه، اکثر مالکان کسب و کارها به دلیل مشغله کاری بسیار بالایی که دارند، به مقوله رقابت رسیدگی نمیکنند. آنها معمولاً از فعالیتهای رقبای خود اطلاعات چندانی در اختیار ندارند. اما میتوان از هوش مصنوعی برای انجام چنین کارهایی کمک گرفت. ابزارهای تحلیل رقابت گوناگونی وجود دارد که از جمله آنها میتوان به Crayon اشاره کرد. این ابزارها با تکیه بر کانالهای مختلفی مثل وبسایتها، شبکههای اجتماعی و نرمافزارها به ردیابی و بررسی وضعیت رقبا میپردازند. علاوه بر این، ابزارهای مذکور این فرصت را در اختیار مالکان کسب و کارها میگذارند تا تغییرات موجود در برنامهریزی بازاریابی رقبا را با دقت بالایی زیر نظر داشته باشند.
۳. بررسی سریع کلان دادهها
اصلاً جای تعجب نیست که مالکان کسب و کارهای کوچک تمایل بالایی به استفاده از حجم قابل ملاحظهای از اطلاعات آنلاین و آفلاین دارند. این اطلاعات به کسب و کارها کمک میکنند تا تصمیمهای مهمی در راستای رشد و توسعه خود اتخاذ نمایند. مهمترین نکته در خصوص بکارگیری ابزارهای هوش مصنوعی در حوزه کسب و کار این است که آنها در تمامی فرایندهای دادهسازی قابلیت کاربرد دارند و میتوانند به بینشهایی ختم شوند که عملاً به کار میآیند. ابزارهای کسب و کار هوش مصنوعی مثل Monkey Learn به یکپارچهسازی و تحلیل دادهها در کانالهای گوناگون پرداخته و باعث صرفهجویی در زمان میشوند.
۴. راهحلهای حمایت از مشتری بر پایه هوش مصنوعی
سیستمهای چت خودکار این فرصت را در اختیار کسب و کارهای کوچک قرار میدهند تا فعالیتهای خدمترسانی به مشتریان را زیر نظر گرفته و منابع لازم برای تعاملات دشوار مشتری را در خود توسعه دهند. آن دسته از ابزارهای خدمترسانی به مشتریان که بر پایه سیستمهای هوش مصنوعی قرار دارند (مثلDigitalGenius یا ChattyPeople)، فرایند پاسخگویی به پرسشهای مشتریان و طبقهبندی بلیطها یا پیامرسانی مستقیم به بخش مربوطه را تسهیل میکنند. بکارگیری هوش مصنوعی در بخش حمایت از مشتریان باعث صرفهجویی در زمان میشود.
۵. هوش مصنوعی در حوزه «مدیریت روابط مشتریان»
چه احساسی به شما دست میدهد اگر بتوانید در مدیریت روابط خود با مشتریان گام مهم و رو به جلویی بردارید و بینش مفیدی درباره چگونگی تعامل با مشتریان فعلی و آتی کسب کنید؟ آن دسته از پلتفرمهای CRM که از هوش مصنوعی بهره میبرند، قابلیت تحلیل داده دارند. این پلتفرمها بر اساس دادههای مشتریان و فرایندهای کسب و کار منحصربفرد شرکت به پیشبینی و حتی توصیه میپردازند.
{“type”:”block”,”srcIndex”:1,”srcClientId”:”da42a25a-25da-44bb-a5c7-df86f727b6b9″,”srcRootClientId”:””}
نتیجهگیری
در این مقاله فهمیدیم که گویا سرانجام نوبت هوش مصنوعی فرا رسیده، اما هنوز جا برای پیشرفت وجود دارد. شرکتها و سازمانهای مختلف به طور غیریکنواخت از هوش مصنوعی استفاده میکنند. علاوه بر این، مقاله حاضر به بررسی فرصتها و چالشهایی پرداخت که اجرای هوش مصنوعی به همراه دارد. حال، امیدواریم به دید روشنی در خصوص توسعه هوش مصنوعی در شرکت خود دست یافته باشید. موفق باشید!
منبع: hooshio.com