تحلیلها نشان میدهد که محاسبات لازم برای آموزش شبکههای عصبی با کارایی یکسان جهت طبقه بندی پایگاه داده imageNet، از سال ۲۰۱۲ هر ۱۶ ماه یکبار دو برابر کاهش یافته است. در مقایسه با سال ۲۰۱۲، کاهش ۴۴ برابریِ محاسبات در آموزش شبکههای عصبی نسبت به«AlexNet2» به ثبت رسیده است. بر اساس نتایجِ بدست آمده، کارایی الگوریتمی منجر به پیشرفت در هوش مصنوعی شده است. ارتقای الگوریتمها یکی از عوامل اصلی در پیشرفت هوش مصنوعی به حساب میآید. در همین راستا، باید به دنبال معیارهایی باشیم که زمینه را برای ارتقای الگوریتمها فراهم میکنند، حتی اگر این کار از اندازهگیری چنین روندهایی در فرایند محاسبه دشوارتر باشد.

میزان کل محاسبه به صورت ترافلاپس در روز برای آموزش عملکرد سطح AlexNet. پایینترین نقاط محاسبه در هر زمان با رنگ آبی نشان داده شده است؛ همه نقاط محاسبه شده به رنگ خاکستری دیده میشوند.
اندازهگیریِ کارآیی
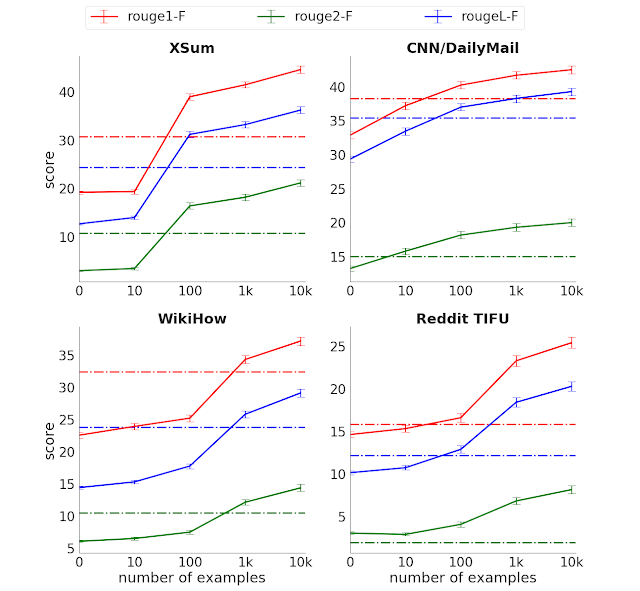
کارآیی الگوریتمی عبارتست از کاهش مراحل محاسبات برای آموزش یک قابلیت خاص. کارآیی یکی از روشهای پایه برای اندازهگیری بهبود عملکرد الگوریتم در مسائل کلاسیک علوم رایانهای مثل مرتبسازی است. اندازهگیریِ کارآیی در مسائل سنتی از قبیل مرتبسازی، آسانتر از یادگیری ماشین است زیرا آن مسائل معیار واضحتری از سطح دشواری کار به دست میدهند. برای مثال در مسئله «مرتبسازی» سطح دشواری با طول لیست مرتبط است. هزینه الگوریتمِ پرکابرد «Quicksort» به این صورت نشان داده میشود: O(n\log{}n)O(nlogn). با این حال، میتوان ابزارِ کارآیی را با ثابت نگه داشتنِ عملکرد در یادگیری ماشین به کار بست. امکان مقایسۀ روندهای کارآیی در حوزههایی نظیر توالی DNA، انرژی خورشیدی و تراکم ترانزیستور وجود دارد. در تحلیل حاضر، از فرایند اجرای مجدد منبع باز برای اندازهگیری میزان بهبود عملکرد استفاده شده است. سرعت بهبود عملکرد در بازههای زمانی کوتاه در Translation، Go و Dota 2 بالاتر بود:
- در بخش ترجمه، Transformer عملکرد بهتری از seq2seq در ترجمه انگلیسی به فرانسوی داشت.
- AlphaZero برای رسیدن به سطح عملکرد AlphaGoZero در یک سال بعد، به ۸ برابر محاسبه کمتر احتیاج داشت.
- OpenAI Five Run برای پیشی گرفتن از OpenAI Five در سه ماه بعد، ۵ برابر محاسبات کمتری انجام داد.
همگان به این نکته واقفاند که شیوه محاسبه در سال ۲۰۱۹ تفاوت محسوسی با سال ۲۰۱۲ پیدا کرده است. محاسباتی که در سال ۲۰۱۹ به انجام رسیدند، قطعاً کارآیی بیشتری نسبت به سال ۲۰۱۲ داشتهاند. به این نکته توجه داشته باشید که تحقیقات هوش مصنوعی در دو مرحله انجام میشود؛ مشابهِ مدل توسعه «tick tock» که در نیمهرساناها دیده شد. قابلیتهای جدید هزینههای محاسباتی قابل توجهی را میطلبند. نسخههای ارتقایافته از این قابلیتها (tock) نیز به سطح بالایی از کارآیی میرسند. افزایش کارآیی الگوریتمها این فرصت را در اختیار محققان قرار میدهد تا در زمانی مشخص با هزینهای مشخص به انجام آزمایشهای مختلف بپردازند. کارآیی الگوریتم که معیاری برای اندازهگیری پیشرفت کلی به حساب میآید، نقش مهمی در تسریعِ تحقیقات هوش مصنوعی در آینده دارد.
سایر معیارهای بهبود عملکرد هوش مصنوعی
علاوه بر کارآیی، چند معیار دیگر نیز وجود دارد که میتوانند اطلاعات خوبی از بهبود عملکرد الگوریتمها در هوش مصنوعی در اختیارمان بگذارند. هزینه آموزش به دلار از معیارهای مرتبط است، اما تمرکز اندکی بر بهبود عملکرد الگوریتمها دارد زیرا تحت تاثیر ارتقایِ نرمافزارها، سختافزارها و زیرساخت رایانش قرار دارد. کارآیی نمونه زمانی نقش کلیدی ایفا میکند که با دادههای کمتری سروکار داشته باشیم. در صورتی که مدلها سریعتر آموزش داده شوند، روند تحقیقات نیز به سرعت انجام میشود و میتوان آن به عنوان معیار موازیسازیِ قابلیتهای یادگیری قلمداد کرد. کارآیی استنتاج نیز به لحاظ زمان GPU، پارامترها و فلاپها افزایش معناداری پیدا کرده است. Shufflenet توانست در عرض ۵ سال به ۱۸ برابر کارآیی استنتاج بیشتر از سطح عملکرد AlexNet دست یابد. این نشان میدهد که کارآیی آموزش و کارآیی استنتاج شاید با سرعت مشابهی ارتقاء پیدا کنند. ساخت دیتاست ها، محیطها و معیارهای سنجش میتواند روش قدرتمندی برای قابلاندازهگیری کردنِ قابلیتهای ویژۀ هوش مصنوعی باشد.
محدودیتهای اصلی
- مشخص نیست که آیا روندهای کارآییِ مشاهده شده در سایر امور و مسائل هوش مصنوعی تعمیمپذیر هستند یا خیر. اندازهگیری نظاممند میتواند این مسئله را به روشنی توضیح دهد که آیا معادل الگوریتمی برای قانون مور وجود دارد یا خیر. در مقاله حاضر، قانون مور به روندِ موجود در دلار/فلاپ اطلاق میشود.
- اگرچه جای تردید نیست که AlexNet پیشرفت چشمگیری به ارمغان آورده، اما در تحلیل حاضر نمیخواهیم این پیشرفت را اندازه بگیریم. نباید به سادگی از کنار این مسئله گذشت که بهبود عملکرد الگوریتمها میتواند سطح پیچیدگی در برخی امور را کاهش دهد. مشاهده مستقیم این نوع افزایش کارآیی در برخی از قابلیتها دشوار است و در این راستا میتوان از تحلیل مجانبی استفاده کرد.
- تحلیلِ حاضر به بررسی هزینه آموزش نهایی در مدلهای بهینهسازی شده میپردازد. بهبود عملکرد الگوریتمها میتواند در برخی از موارد آموزشِ مدلها را آسان کند. این کار با بزرگتر کردنِ فضای پارامترهایی که عملکرد نهایی را ارتقاء میبخشند، انجام میشود.
اندازهگیری و سیاست هوش مصنوعی
اگر اندازهگیری و ارزیابی سیستمهای هوش مصنوعی به لحاظ خصوصیات فنی و تاثیر اجتماعی مورد توجه قرار گیرد، سیاستگذاری در زمینه هوش مصنوعی میتواند بهبود پیدا کند. هر نوع ابتکار عملی در اندازهگیری میتواند موجب شفافسازی پرسشهای مهمی در زمینه سیاستگذاری شود. تحلیلهای هوش مصنوعی و Compute نشان میدهد که سیاستگذاران باید منابع مالی بیشتری برای انجام محاسبات در اختیار دانشگاهها قرار دهند. در صورت انجام این کار، محققان میتوانند تحقیقات صنعت را تکرار، تکثیر و گسترش دهند. تحلیل حاضر حاکی از آن است که سیاستگذاران میتوانند بینش بهتری درباره هزینۀ استفاده از قابلیتهای هوش مصنوعی بدست آورند. باید سرعت ارتقای کارآیی در سیستمهای هوش مصنوعی به دقت مورد ارزیابی قرار گیرد.
گامهای روبه جلو برای ارتقای کارآیی
آن دسته از مدلهایی که در قابلیتهای معنادار، به کارآیی آموزشی مطلوبی دست مییابند، گزینههای نویدبخشی برای ارتقای عملکرد محسوب میشوند. افزون بر این، تحقیق حاضر به آموزشِ نمونه مدلهای PyTorch پرداخت. تغییراتی نیز برای ارتقای یادگیری اولیه اِعمال شد. اندازهگیری روندهای بلندمدت در میزان کارآیی میتواند تصویر بهتری از فرایند الگوریتمی ارائه کند. نتایج نشان میدهد که در آن دسته از امور هوش مصنوعی که سطح بالای سرمایهگذاری وجود دارد (زمان تحقیق یا رایانش)، احتمال میرود کارآیی الگوریتمی از کارآیی سختافزاری پیشی گیرد (قانون مور). زمانی که قانون مور ابداع شد (سال ۱۹۶۵)، مدارهای یکپارچه ۶۴ ترانزیستور داشتند، اما اکنون فناوری تا جایی پیشرفت کرده که گوشی آیفون ۱۱ دارای ۸.۵ میلیارد ترانزیستور است. اگر رشد تصاعدیِ کارآیی الگوریتمیِ هوش مصنوعی برای چندین دهه تداوم داشته باشد، سرانجام چه نتیجهای حاصل میشود؟ پاسخِ این پرسش مشخص نیست. در هر حال، امیدواریم طرح چنین پرسشهایی زمینه را برای توسعه فناوریها و خدمات هوش مصنوعی قویتر فراهم کند.
بنا به دلایلی که تاکنون اشاره کردیم، تصمیم بر این شده که میزان کارآیی را به طور علنی بررسی و ردیابی کنیم. میخواهیم کار را با ابزارهای سنجش کارآیی ترجمه و بینایی آغاز کنیم. ImageNet تنها منبع داده آموزشی برای سنجش بینایی است. استفاده از تصاویر یا دادههای دیگر مجاز است. رهبران صنعت، سیاستگذاران، اقتصاددانها و محققان در تلاشاند تا به درک بهتری از بهبود عملکرد هوش مصنوعی رسیده و در خصوص میزان توجه و سرمایهگذاری در این حوزه تصمیمگیری کنند. فعالیتهایی که در راستای اندازهگیری صورت میگیرد، میتواند در اتخاذ تصمیمهای بهتر نقش داشته باشد.
منبع: hooshio.com