حوزه یادگیری ماشین با دو نوع یادگیری تحت عنوان یادگیری بانظارت و بدون نظارت بدون نظارتشناخته میشود. اصلیترین تفاوت یادگیری بانظارت و بدون نظارت آن است که یادگیری بانظارت با وضعیت واقعیانجام میشود؛ به عبارت دیگر، از قبل میدانیم که نمونههایمان باید چه مقادیر خروجی داشته باشند.بنابراین، هدف یادگیری بانظارت این است که تابعی را فرا گیرد که به بهترین شکل رابطه میان ورودی و خروجی را در دادهها تخمین میزند. از سوی دیگر، یادگیری بدون نظارت فاقد خروجی برچسبدار است. بر اساس این نوع یادگیری، ساختار طبیعیِ موجود در یک مجموعه نقاط دادهای استنتاج میشود.
یادگیری بانظارت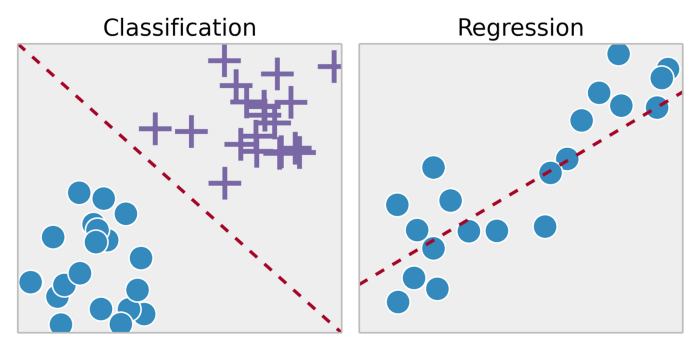
یادگیری بانظارت معمولاً در زمینه دستهبندی به کار گرفته میشود. وقتی بخواهیم ورودی را در برچسبهای گسسته خروجی یا خروجی پیوسته نگاشت دهیم، این نوع یادگیری به کارمان میآید. از جمله الگوریتمهای متداول در یادگیری بانظارت میتوان به رگرسیون لجستیک ،بیزی ساده ، ماشینهای بردار پشتیبان(SVM)، شبکههای عصبی مصنوعیو غیره اشاره کرد. در رگرسیونو دستهبندی، هدف این است که در ابتدا ساختارها یا روابط خاص در دادهها را پیدا کنیم. این کار میتواند نقش موثری در تولید دادههای خروجی صحیح داشته باشد. توجه داشته باشید که خروجی صحیح به طور کلی از دادههای آموزشی به دست میآید؛ پس گرچه این پیشفرض وجود دارد که مدلمان به درستی عمل میکند، اما نمیتوان مدعی شد که برچسب دادهها همیشه و در هر شرایطی درست و بینقص هستند. برچسبهای دادهای نویزدار یا نادرست میتوانند از تاثیرگذاری مدل کاسته و کارآیی را پایین آورند.
پیچیدگی مدلو مصالحه بایاس-واریانساز جمله نکات مهمی هستند که در هنگام بکارگیری روش یادگیری بانظارت مستلزم توجه هستند. پیچیدگی مدل اشاره به سطح پیچیدگیِ تابعی دارد که خواهان یادگیری آن هستید. ماهیت دادههای آموزشی یک عامل تعیینکننده در سطح پیچیدگی مدل برشمرده میشود. اگر میزان داده اندکی در اختیار دارید یا اگر دادههایتان در سناریوهای احتمالیِ مختلف به طور یکنواخت توزیع نشده است، باید سراغ مدلی بروید که سطح پیچیدگی کمتری دارد. زیرا اگر مدل بسیار پیچیدهای در تعداد اندکی از نقاط داده مورد استفاده قرار گیرد، مدل دچار بیشبرازش خواهد شد. بیشبرازش به یادگیری تابعی اشاره میکند که مطابقت بالایی با دادههای آموزشی دارد و امکان تعمیم آن به سایر نقاط داده وجود ندارد. به عبارت دیگر، مدل سعی میکند دادههای آموزشی خود را بدون خطا بازتولید کند در حالی که ساختار یا روندی حقیقی در دادهها را یاد نگرفته است. فرض کنید میخواهید یک منحنی را بین دو نقطه برازش کنید. از دید نظری، میتوانید از تابعی با درجه دلخواه استفاده کنید؛ اما از دید عمَلی، ترجیح میدهید که تابع خطی را برگزینید.
رابطه بایاس-واریانس
رابطه بایاس-واریانس به تعمیم مدل اشاره میکند. در همه مدلها، تعادلی میان بایاس (عبارت خطای ثابت) و واریانس (مقدار خطایی که میتواند در مجموعههای آموزشی مختلف متغیر باشد) برقرار است. بنابراین، بایاس زیاد و واریانس کم میتواند مدلی باشد که ۲۰ درصد مواقع دچار اشتباه میشود. اما مدل بایاس کم و واریانس زیاد میتواند بسته به دادههای استفاده شده برای آموزش مدل، ۵ اِلی ۵۰ درصد مواقع اشتباه کند. به این مسئله توجه داشته باشید که بایاس و واریانس در جهت مخالف یکدیگر حرکت میکنند؛ افزایش بایاس معمولاً واریانس کمتر را در پی دارد، و بالعکس.
مسئله و ماهیت دادهها در هنگام ساخت مدل باید این فرصت را در اختیارمان بگذارد تا در خصوص طیف بایاس-واریانس تصمیم آگاهانهای اتخاذ کنیم. به طور کلی، اگر سطح بایاس زیاد باشد، عملکرد مدل با تضمین کمتری همراه خواهد بود. عملکرد مدل در انجام برخی از امور اهمیت فراوانی دارد. افزون بر این، برای اینکه مدلهایی بسازیم که به خوبی قابلیت تعمیم داشته باشند، واریانس مدل باید با اندازه و پیچیدگی دادههای آموزشی همخوانی داشته باشد. معمولاً یادگیری دیتاستهای ساده و کوچک با مدلهایی انجام میشود که واریانس کمتری دارند. در حالیکه دیتاست های بزرگ و پیچیده مستلزم مدلهایی با واریانس بالاتر هستند تا ساختار دادهها را به طور کامل یاد گیرند.
یادگیری بدون نظارت
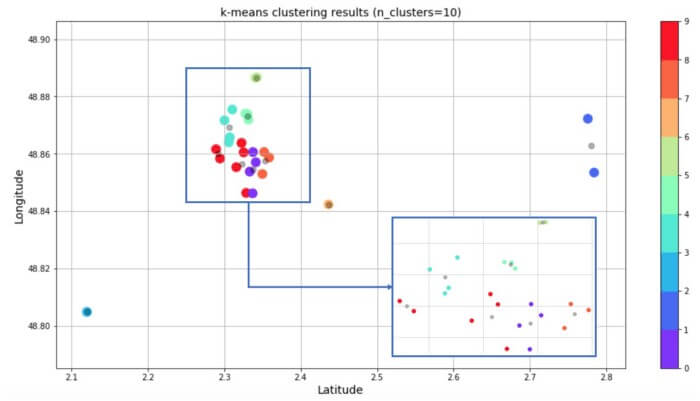
از جمله متداولترین کارهایی که میتوان با یادگیری بدون نظارت انجام داد، میتوان به خوشهبندی ، یادگیری ارائه و تخمین چگالی اشاره کرد. در همه این موارد، به دنبال یادگیری ساختار ذاتی دادهها بدون استفاده از برچسب داده¬های هستیم. برخی از الگوریتمهای رایج عبارتند از خوشه بندی k-means، تحلیل مولفه اصلی ، خود رمزگذار. چون هیچ برچسبی ارائه نشده، هیچ روش مشخصی برای مقایسه عملکرد مدل در اکثر روشهای یادگیری بدون نظارت موجود نیست. روشهای یادگیری بدون نظارت در تحلیلهای اکتشافی و کاهش بُعد نیز مورد استفاده قرار میگیرند. روشهای یادگیری بدون نظارت در تجزیه و تحلیلهای اکتشافی خیلی مفید هستند زیرا قادرند ساختار را به طور خودکار در داده شناسایی کنند. برای نمونه، اگر تحلیلگری بخواهد مصرفکنندگان را تفکیک کند، روشهای یادگیری بدون نظارت میتواند شروع بسیار خوبی برای تحلیل باشد. در مواردی که بررسی روندهای موجود در دادهها برای انسان امکانناپذیر است، روشهای یادگیری بدون نظارت میتوانند بینش مناسبی فراهم کرده و برای آزمودن تکتکِ فرضیهها به کار برده شوند. کاهش بُعد به روشهایی اطلاق میشود که دادهها را با استفاده از ویژگیها یا ستونهای کمتری به نمایش میگذارند. روشهای یادگیری بدون نظارت در اجرای این روش «کاهش بعد» کاربرد دارد. در یادگیری ارائه، یادگیری روابط میان ویژگیهای فردی در دستور کار قرار میگیرد. لذا این فرصت برایمان ایجاد میشود تا دادههای خود را با استفاده از ویژگیهای پنهان ارائه کنیم. این ساختارهای پنهان معمولا با تعداد ویژگی های کمتری نسبت به ویژگی های اولیه نمایش داده میشوند، همین مسئله به ما اجازه میدهد که پردازش بیشتری با حساسیت کمتری بر روی داده ها داشته باشیم، همچنین از این طریق ویژگی های اضافی حذف میگردند.

تفاوت یادگیری بانظارت و بدون نظارت: دستهبندی الگوریتمهای یادگیری ماشین
منبع: hooshio.com