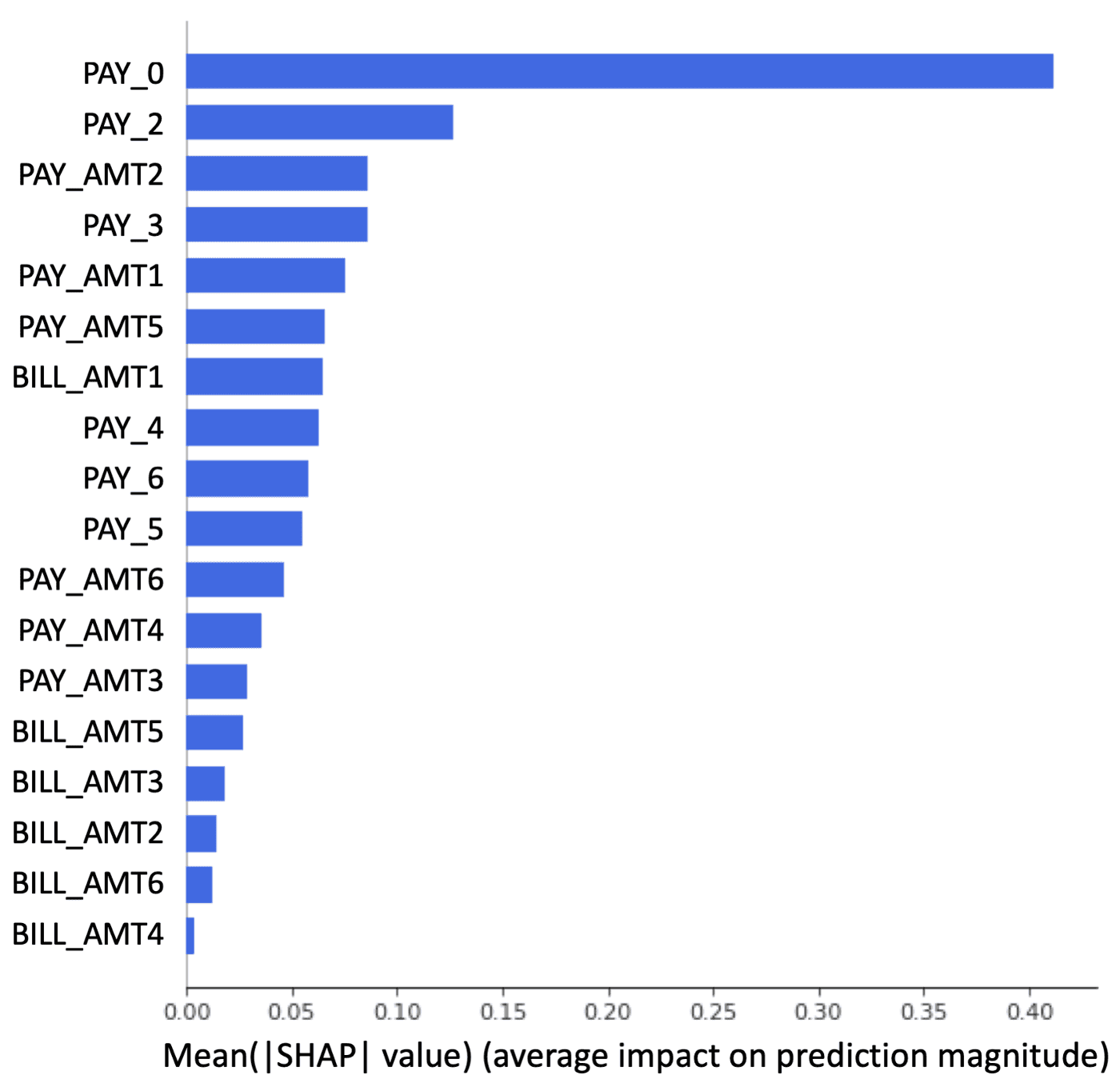
اگر به شیوههای آموزش الگوریتمهای یادگیری ماشینی در ۵ یا ۱۰ سال گذشته بنگرید و آن را با شیوههای جدید مقایسه کنید، متوجه تفاوتهای بزرگی میشوید. امروزه آموزش الگوریتمها در یادگیری ماشینی بهتر و کارآمدتر از گذشته است و دلیل آن نیز حجم زیاد دادههایی است که امروزه در دسترس ما قرار گرفتهاند. اما یادگیری ماشینی چگونه از این دادههای استفاده میکند؟
به تعریف اصطلاح «یادگیری ماشینی» دقت کنید: «در یادگیری ماشینی، رایانهها یا ماشینها بدون برنامهنویسی مستقیم و بهطور خودکار از تجربیات گذشته میآموزند». منظور از آموزش ماشینها درواقع همان عبارت «از تجربیات میآموزند» است. طی این فرآیند، دادهها و اطلاعات نقش مهمی ایفا میکنند. اما ماشینها چگونه آموزش داده میشوند؟ پاسخ دیتاستها هستند. به همین دلیل است که دادن اطلاعات و دادههای درست به ماشینی که قرار است مسئله مدنظر شما را حل کند، مسئلهای حیاتی است. در این مقاله دیتاست های یادگیری ماشینی را معرفی میکنیم.
اهمیت دیتاستها در یادگیری ماشینی چیست؟
پاسخ این است که ماشینها نیز همچون انسانها توانایی یادگیری مسائل را دارند و تنها کافی است اطلاعات مرتبط با آن موضوع را مشاهده کنند. اما تفاوت آنها با یک انسان، در مقدار دادهای است که برای یادگیری یک موضوع نیاز دارند. دادههایی که به یک ماشین میدهید، از لحاظ کمیت باید چنان باشد که ماشین درنهایت، کاری که از آن خواستهاید را انجام دهد. به همین دلیل، برای آموزش ماشینها به حجم زیادی از دادهها نیاز داریم.
دادههای یادگیری ماشینی را میتوان مشابه دادههای جمعآوریشده برای انجام یک پژوهش درنظر گرفت، بدین معنا که هر چه حجم دادههای نمونه شما بزرگتر و نمونه گیری شما کاملتر باشد، نتایج حاصل از آن پژوهش معتبرتر خواهد بود. اگر حجم نمونه کافی نباشد، نمیتوانید تمامی متغیرها را مدنظر قرار دهید. این مسئله منجر به کاهش دقت یادگیری و استخراج ویژگی های میشود که اصلا بیانگر داده ها نیستند و در نهایت استنتاج اشتباه ماشین خواهد شد.
دیتاستها دادههای موردنیاز شما را در اختیارتان قرار میدهند. دیتاستها مدلی آموزش میدهند که قادر است واکنشهای مختلفی نشان دهد. آنها مدلی از الگوریتمها میسازند که میتواند روابط را آشکار کند، الگوها را تشخیص دهد، مسائل دشوار را درک کند و تصمیم بگیرد.
نکته مهم در استفاده از دیتاستها این است که دیتاست موردنیاز خود را بهدرستی انتخاب کنید. یعنی دیتاستی را انتخاب کنید که دارای فرمت مناسب و ویژگیها و متغیرهای معناداری در رابطه با پروژه شما باشد، زیرا عملکرد نهایی سیستم به آنچه که از دادهها یاد گرفته، بستگی دارد. علاوه براین، دادن دادههای درست به ماشین، متضمن این خواهد بود که ماشین عملکرد کارآمدی داشته باشد و بتواند بدون دخالت انسان، به نتایج دقیقی برسد.
برای مثال، اگر برای آموزش یک سیستم بازشناسی گفتار از دیتاستی حاوی دادههای مربوط به کتب درسی انگلیسی زبان استفاده کنیم، این ماشین در درک مطالب غیر درسی دچار مشکل خواهد شد. زیرا در این دیتاست، دادههای مربوط به دستورزبان محاورهای، لهجههای خارجی و اختلالات گفتاری وجود ندارد و ماشین نیز نمیتواند چیزی در این خصوص بیاموزد. بنابراین، برای آموزش این سیستم باید از دیتاستی استفاده کرد که متغیرهای گستردهای که در زبان محاوره و در بین جنسیتهای مختلف، سنین متفاوت و لهجههای مختلف وجود دارد را شامل شود.
بنابراین، باید بخاطر داشته باشید که دادههای آموزشی شما باید هر سه ویژگی کیفیت، کمیت و تنوع را داشته باشند، زیرا تمامی این عوامل در موفقیت مدلهای یادگیری ماشینی مؤثر هستند.
برترین دیتاست های یادگیری ماشینی برای مبتدیان
امروزه دیتاستهای فراوانی برای استفاده در فرآیند یادگیری ماشینی دردسترس قرار گرفتهاند. به همین دلیل، ممکن است مبتدیان در تشخیص و انتخاب دیتاست درست برای یک پروژه دچار سردرگمی شوند.
بهترین راهحل برای این مسئله، انتخاب دیتاستی است که بهسرعت دانلود و با مدل سازگار شود. بهعلاوه، همیشه از دیتاستهای استاندارد، قابلدرک و پرکاربرد استفاده کنید. بدین ترتیب، شما میتوانید نتایج کارتان را با نتایج حاصل از کار سایر افرادی که از همان دیتاست استفاده کردهاند، مقایسه کنید و پیشرفت خود را بسنجید.
دیتاست خود را میتوانید براساس نتیجهای که از فرآیند یادگیری ماشین انتظار دارید، انتخاب نمایید. در ادامه، مروری خلاصه بر پرکاربردترین دیتاستها در حوزههای مختلف یادگیری ماشینی از پردازش تصویر و ویدیو گرفته تا بازشناسی متن سیستمهای خودمختار خواهیم داشت.
پردازش تصویر
همانطور که گفته شد، دیتاستهای یادگیری ماشینی متعددی در دردسترس ما قرار دارند، اما برای انتخاب دیتاست باید کارکردی که از برنامه کاربردی خود انتظار دارید را درنظر بگیرید. پردازش تصویر در یادگیری ماشینی برای پردازش تصاویر و استخراج اطلاعات مفید از آنها بهکار گرفته میشود.برای مثال، اگر روی یک نرمافزار ساده تشخیص چهره کار میکنید، میتوانید آن را با استفاده از دیتاستی که حاوی تصاویری از چهره انسانهاست، آموزش دهید. این همان روشی است که فیسبوک برای شناسایی یک فرد در عکسهای دستهجمعی استفاده میکند. همچنین، گوگل و سایتهای جستوجوی تصویری محصول نیز در بخش جستوجوی تصویری خود از چنین دیتاستهایی استفاده کردهاند.
| نام دیتاست | توضیح مختصر |
| ۱۰k US Adult Faces Database | این دیتاست شامل ۱۰.۱۶۸ عکس از چهره طبیعی افراد و ۲.۲۲۲ معیار از چهره است. برخی از معیارهایی که در این دیتاست برای چهره درنظر گرفته شدهاند عبارتند از: بهیادماندنی بودن، بینایی یارانهای و صفات روانشناختی. تصاویر این دیتاست در فرمت JPEG هستند، وضوح تصاویر ۷۲ پیکسل در هر اینچ و ارتفاع آنهاها ۲۵۶ پیکسل است. |
| Google’s Open Images | Open Image دیتاستی است متشکل از ۹ میلیون نشانی اینترنتی که شما را به تصاویر موجود در اینترنت هدایت میکند. این تصاویر دارای برچسبهای توضیحی هستند که در ۶۰۰۰ دسته مختلف طبقهبندی شدهاند. این برچسبها بیشتر عناصر واقعی را شامل میشوند. تنها تصاویری در این دیتاست قرار میگیرند که مجوز انتساب مشترکات خلاقانه را دریافت کرده باشند. |
| Visual Genome | این دیتاست حاوی بیش از ۱۰۰ هزار تصویر است که کاملاً تفسیر شدهاند. نواحی هر یک از این تصاویر به این صورت توصیف شدهاند؛ توضیح ناحیه: دختری که به فیل غذا میدهد، شیء: فیل، صفت: بزرگ، رابطه: غذا دادن. |
| Labeled Faces in the Wild | در این دیتاست بیش از ۱۳.۰۰۰ تصویر از چهره افراد جمعآوری شده است. این تصاویر، تصاویری هستند که در فضای اینترنت به اشتراک گذاشته شده بودند و در برچسب هر تصویر، نام فرد درون تصویر ذکر شده است. |
ایدههایی آسان و سرگرمکننده برای استفاده از دیتاستهای تصویری
• گربه یا سگ: با استفاده از دیتاست گربهها و دیتاست استنفورد که حاوی تصاویر سگها است، برنامه شما میتواند تشخیص دهد که در تصویر دادهشده، سگ وجود دارد یا گربه؟
• طبقهبندی گلهای زنبق: میتوانید به کمک دیتاست گلهای زنبق یک برنامه کاربردی مبتنی بر یادگیری ماشینی طراحی کنید که گلها را در ۳ گونه گیاهی طبقهبندی کند. با اجرای این پروژه دستهبندی صفات فیزیکی برپایه محتوا را خواهید آموخت که به شما در طراحی برنامهها و پروژههای کاربردی همچون ردیابی کلاهبرداری،شناسایی مجرمین، مدیریت درد (برای مثال، برنامه ePAT را درنظر بگیرید که با استفاده از فنآوری تشخیص چهره، نشانههای درد را در صورت فرد شناسایی میکند.) و غیره کمک میکند.
• هاتداگ است یا نه؟: برنامه شما با استفاده از دیتاست Food 101، قادر خواهد بود تا غذاها را شناسایی کند و به شما بگوید که آیا این غذا ساندویچ هاتداگ است یا خیر.
تحلیل احساس
حتی مبتدیان نیز میتوانند با استفاده از دیتاستهای تحلیل احساس برنامههای جالبی طراحی کنند. در یادگیری ماشینی میتوان ماشینها را با بهکارگیری دیتاستهای تحلیل احساس به نحوی آموزش داد که عواطف و احساسات موجود در یک جمله، یک کلمه یا یک متن کوتاه را تحلیل و پیشبینی کنند. بهطور معمول، از این قبیل برنامهها برای تحلیل فیلمها و نظرات مشتریان درمورد محصولات استفاده میشود. اگر کمی خلاقیت به خرج دهید، میتوانید برنامهای طراحی کنید که با استفاده از تحلیلهای احساسی، موضوعی که بحثبرانگیزتر از سایرین خواهد بود را شناسایی کند.
| نام دیتاست | توضیح مختصر |
| Sentiment140 | این دیتاست حاوی ۱۶۰.۰۰۰ توییت است که شکلکهای استفادهشده در آنها حذف شدهاند. |
| Yelp Reviews | این دیتاست یک دیتاست رایگان است که توسط شرکت Yelp منتشر شده و حاوی بیش از ۵ میلیون نظر درباره رستورانها، فروشگاهها، تفریحهای شبانه، غذاها، سرگرمیها و غیره است. |
| Twitter US Airline Sentiment | در این دیتاست دادههای مربوط به خطوط هواپیمایی آمریکا در شبکه اجتماعی توییترT از سال ۲۰۱۵ جمعآوری شده و به هر یک از آنها یکی از برچسبهای مثبت، منفی و خنثی داده شده است. |
| Amazon reviews | در این دیتاست بیش از ۳۵ میلیون نظر ثبتشده در وبسایت آمازون طی دوره زمانی ۱۸ ساله جمعآوری شده است. دادههای موجود شامل اطلاعاتی درخصوص محصولات، امتیاز کاربران و نظرات متنی هستند. |
ایدههایی آسان و سرگرمکننده برای استفاده از دیتاستهای تحلیل احساسی
مثبت یا منفی: با استفاده از دیتاست Spambase در مدل خود، توییتها را تحلیل کنید و آنها در دو دسته مثبت و منفی طبقهبندی کنید.
راضی یا ناراضی: با استفاده از دیتاست Yelp Reviews پروژهای تعریف کنید که در آن یک ماشین بتواند با مشاهده نظر یک فرد درخصوص یک محصول تشخیص دهد که فرد از آن محصول راضی بوده یا ناراضی.
خوب یا بد: میتوانید با استفاده از دیتاست Amazon reviews، یک ماشین را به نحوی آموزش دهید که خوب یا بد بودن نظرات کاربران را تشخیص دهد.
پردازش زبان طبیعی
در فنآوری پردازش زبان طبیعی ماشینها درجهت تحلیل و پردازش حجم زیادی از دادههای مربوط به زبانهای طبیعی آموزش میبینند. موتورهای جستوجو همچون گوگل به کمک این فنآوری میتوانند آنچه شما در بخش جستوجو مینویسید را پیدا کنند. شما نیز میتوانید با استفاده از این قبیل دیتاستها، یک برنامه کاربردی جالب پردازش زبان طبیعی و مبتنی بر یادگیری ماشینی طراحی کنید.
| نام دیتاست | توضیح مختصر |
| Speech Accent Archive | این دیتاست حاوی ۲۱۴۰ نمونه صوتی است که در آنها افرادی از ۱۷۷ کشور و ۲۱۴ ریشه زبانی مختلف حضور دارند و متن واحدی را به زبان انگلیسی میخوانند. |
| Wikipedia Links data | این دیتاست حاوی تقریبا ۱.۹ میلیارد واژه است که از بیش از ۴ میلیون مقاله جمعآوری شدهاند. در این دیتاست میتوان واژهها، عبارات یا بخشی از یک پاراگراف را جستوجو کرد. |
| Blogger Corpus | این دیتاست متشکل از ۶۸۱.۲۸۸ پست از وبلاگهای مختلف است که از وبسایت Blogger.com جمعآوری شدهاند. در هر یک از این وبلاگهای منتخب، حداقل ۲۰۰ واژه پرکاربر انگلیسی استفاده شده است. |
ایدههایی جالب برای استفاده از دیتاستهای پردازش زبان طبیعی:
• هرزنامه یا مفید: با استفاده از دیتاست Spambase میتوانید برنامهای طراحی کنید که قادر باشد ایمیلهای هرزنامه را از ایمیلهای مفید و خوب تشخیص دهد.
پردازش ویدیو
با استفاده از دیتاستهای پردازش ویدیو، ماشین شما میآموزد که صحنههای مختلف یک ویدیو و اشیاء، احساسات و کنش و واکنشهای درون آن را شناسایی و تحلیل کند. به این منظور، شما باید حجم زیادی از دادههای مربوط به واکنشها، اشیاء و فعالیتها را به ماشین خود بدهید.
| نام دیتاست | توضیح مختصر |
| UCF101 – Action Recognition Data Set | این دیتاست شامل ۱۳.۳۲۰ ویدیو است که براساس عملی که در آنها اتفاق میافتد در ۱۰۱ گروه دستهبندی شدهاند. |
| Youtube 8M | Youtube 8M دیتاستی متشکل از تعداد زیادی ویدیوهای برچسب گذاری شده است. این دیتاست شامل شناسههای میلیونها ویدیو از یوتیوب و تفسیرهای ماشینی بسیار باکیفیت از این ویدیوهاست. در این تفسیرهای ماشینی از بیش از ۳.۸۰۰ واژه مربوط به اشیاء دیداری استفاده شده است. |
یک ایده جالب یرای استفاده از دیتاستهای پردازش ویدیو
- تشخیص عمل: با استفاده از دیتاستهای UCF101 – Action Recognition Data Set یا Youtube 8M میتوانیدبه برنامه کاربردی خود آموزش دهید تا اعمال مختلف چون راهرفتن یا دویدن را در یک ویدیو شناسایی کند.
تشخیص گفتار
تشخیص گفتار به این معناست که یک ماشین میتواند واژهها و عبارات را در زبان گفتاری شناسایی یا تحلیل کند. اگر کیفیت و کمیت دادههایی که به ماشین خود دادهاید مناسب باشد، عملکرد بهتری در حوزه تشخیص گفتار خواهد داشت. با ترکیب دو فنآوری پردازش زبان طبیعی و پردازش گفتار میتوانید دستیار شخصی شبیه به الکسا طراحی کنید که بتواند خواسته شما را به درستی متوجه شود.
| نام دیتاست | توضیح مختصر |
| Gender Recognition by Voice and speech analysis | این دیتاست براساس ویژگیهای آوایی صدا و گفتار، صدای زنان را از مردان تمیز میدهد. این دیتاست حاوی ۳.۱۶۸ فایل صوتی ضبطشده از صدای زنان و مردان مختلف در هنگام سخن گفتن است. |
| Human Activity Recognition w/Smartphone | دیتاست Human Activity Recognition حاوی ویدیوهایی است که از ۳۰ فرد در حین انجام فعالیتهای روزانهشان گرفته شده است. در حین انجام این فعالیتها یک گوشی موبایل (سامسونگ گلکسی S2) نیز به کمر آنها متصل شده بود. |
| TIMIT | از دیتاست TIMIT در مطالعات آواشناسی آکوستیک و توسعه سیستمهای خودکار تشخیص گفتار استفاده میشود. این دیتاست متشکل از فایلهای صوتی ضبطشده از ۶۳۰ نفر است که با ۸ گویش رایج انگلیسی آمریکایی صحبت میکردند. هر یک از افراد حاضر در این فرآیند باید کلمات، مصوتها و جملاتی را میخواندند که از لحاظ آوایی بسیار غنی بودند. |
| Speech Accent Archive | این دیتاست حاوی ۲۱۴۰ نمونه صوتی است که در آنها افرادی از ۱۷۷ کشور و ۲۱۴ ریشه زبانی مختلف حضور دارند و متن واحدی را به زبان انگلیسی میخوانند. |
ایدههایی جالب برای استفاده از دیتاستهای تشخیص گفتار
• تشخیص لهجه: با استفاده از دیتاست Speech Accent Archive، برنامه کاربردی شما قادر خواهد بود لهجههای مختلف را از میان لهجههای نمونه تشخیص دهد.
• شناسایی عمل: با استفاده از دیتاست Human Activity Recognition w/Smartphone میتوانید برنامهای طراحی کنید که فعالیتهای انسان را تشخیص دهد.
تولید زبان طبیعی
تولید زبان طبیعی به معنای توانایی ماشینها در شبیهسازی گفتار انسان است. به کمک این فنآوری میتوان مطالب نوشتهشده را به فایلهای شنیداری تبدیل کرد. همچنین این فنآوری میتواند با خواندن مطالبی که روی صفحه نقش بستهاند، به افراد کمبینا و دارای نقص بینایی کمک کند. این درواقع همان روشی است که دستیارهای هوشمندی چون الکسا و سیری به شما پاسخ میدهند.
| نام دیتاست | توضیح مختصر |
| Common Voice by Mozilla | دیتاست Common Voice حاوی دادههای گفتاری است که در وبسایت Common Voice توسط کاربران خوانده شدهاند. متون خوانده شده در این وبسایت، از منابع عمومی همچون پستهای کاربران در وبلاگها، کتابهای قدیمی و فیلمها است. |
| LibriSpeech | این دیتاست شامل حدود ۵۰۰ ساعت فایل صوتی است. این فایلها حاوی کتابهای صوتی هستند که توسط افراد مختلف و به زبانی روان خوانده شدهاند. در این دیتاست فایل صوتی و متن اصلی هر کتاب به تفکیک فصول آن، موجود است. |
ایدههایی جالب برای استفاده از دیتاستهای تولید زبان طبیعی
• تبدیل متن به گفتار: با استفاده از دیتاست Blogger Corpus، میتوانید برنامهای طراحی کنید که متون موجود در وبسایت را با صدای بلند بخواند.
اتومبیلهای خودران
شما نیز میتوانید یک برنامه یادگیری ماشینی ساده برای اتومبیلهای خودران طراحی کنید. دیتاستهای یادگیری ماشینی موجود در حوزه اتومبیلهای خودران برای درک محیط و هدایت خودرو بدون نیاز به دخالت انسان، به شما کمک خواهند کرد. از این الگوریتمها میتوان برای هدایت اتومبیلهای خودران، پهبادها، رباتهای انباردار و غیره استفاده کرد. اهمیت دیتاستها در این حوزه بیشتر از سایر حوزههای یادگیری ماشینی است، زیرا ریسک دراین حوزه بیشتر است و هزینه یک اشتباه ممکن است جان یک انسان باشد.
| نام دیتاست | توضیح مختصر |
| Berkeley DeepDrive BDD100k | این دیتاست یکی از بزرگترین دیتاستهای موجود در حوزه اتومبیلهای خودران مبتنی بر هوش مصنوعی است. این دیتاست حاوی بیش از ۱۰۰.۰۰۰ ویدیو از بیش از ۱۰۰۰ ساعت رانندگی در شرایط آبوهوایی ساعات مختلف روز میباشد. |
| Baidu Apolloscapes | Baidu Apolloscapes دیتاستی بزرگ متشکل از ۲۶ قلم شیء معنایی از جمله خودرو، دوچرخه، عابرین پیاده، ساختمان، چراغ برق و غیره است. |
| Comma.ai | این دیتاست حاوی بیش از ۷ ساعت ویدیو از رانندگی در بزرگراه است. این دادهها شامل اطلاعاتی درخصوص سرعت، شتاب، زاویه فرمان و مختصات مکانی خودرو میشوند. |
| Cityscape Dataset | این دیتاست متشکل از حجم زیادی از دادههای ویدیوی تهیهشده از خیابانهای ۵۰ شهر مختلف است. |
| nuScenes | این دیتاست حاوی بیش از ۱۰۰۰ تصویر از مناظر، حدود ۱.۴ میلیون تصویر، ۴۰۰.۰۰۰ داده درخصوص وسعت دید سیستم لیدار (سیستمی که با استفاده از لیزر، فاصله بین اجسام را میسنجد) و ۱.۳ میلیون کادر محاطی ۳ بعدی (که با کمک دوربینهای RGB، رادارها و لیدار اشیاء را شناسایی میکند) است. |
ایدههایی جالب برای استفاده از دیتاستهای اتومبیلهای خودران
• طراحی برنامهای ساده برای اتومبیلهای خودران: با استفاده از یکی از دیتاستهای بالا و دادههای مربوط به تجربیات مختلف رانندگی در شرایط آبوهوایی متفاوت، برنامه خود را آموزش دهید.
اینترنت اشیاء
کاربردهای یادگیری ماشینی در حوزه اینترنت اشیاء روزبهروز درحال گسترش است. شما به عنوان یک مبتدی در دنیای یادگیری ماشینی ممکن است دانش لازم برای طراحی برنامههای اینترنت اشیاء کاربردی و پیشرفته که از یادگیری ماشینی استفاده میکنند را نداشته باشید، اما قطعاً میتوانید با شناخت دیتاستهای مربوطه، به این دنیای شگفتانگیز قدم بگذارید.
| نام دیتاست | توضیح مختصر |
| Wayfinding, Path Planning, and Navigation Dataset | این دیتاست حاوی نمونههایی از مسیریابی درون یک ساختمان (کتابخانه Waldo در دانشگاه غرب میشیگان) است. این دادهها بهطورمعمول در نرمافزارهای مسیریابی بهکار گرفته میشوند. |
| ARAS Human Activity Dataset | این دیتاست یک دیتاست در حوزه تشخیص فعالیتهای انسانی است که از ۲ خانوار واقعی جمعآوری شده که شامل بیش از ۲۶ میلیون داده از حسگرها و بیش از ۳۰۰۰ فعالیت انجامشده میباشد. |
یک ایده جالب برای استفاده از دیتاستهای اینترنت اشیاء:
• طراحی یک دستگاه پوشیدنی برای پیگیری فعالیتهای افراد: با استفاده از دیتاست ARAS Human Activity Dataset، یک دستگاه پوشیدنی را آموزش دهید تا بتواند فعالیتهای افراد را تمیز دهد.
پس از به پایان رساندن مطالعه این لیستها، نباید احساس محدودیت کنید. این دیتاستها تنها تعدادی از دیتاستهایی هستند که میتوانید در برنامههای کاربردی مبتنی بر یادگیری ماشینی از آنها استفاده کنید. در فضای اینترنت میتوانید دیتاستهای بهتری نیز برای پروژه یادگیری ماشینی خود پیدا کنید.
میتوانید در وبسایتهای Kaggle، UCI Machine Learning Repository، Kdnugget، Awesome Public Datasets, و Reddit Datasets Subredditدیتاستهای بیشتری پیدا کنید.
حال وقت آن است که این دیتاستها را در پروژه خود به کار بگیرید. اگر در حوزه یادگیری ماشینی مبتدی هستید این مقاله نیز در آشنایی بیشتر با این فنآوری به شما کمک خواهد کرد.
جدا از این که تازهکار هستید یا مدتی در دنیای یادگیری ماشینی فعالیت داشتهاید، باید همواره بهخاطر داشته باشید که دیتاستی را انتخاب کنید که پرکاربرد باشد و بتوان آن را بهسرعت از یک منبع قابلاعتماد بارگیری کرد.
منبع: hooshio.com