منبع: hooshio.com
مجله هوش مصنوعی
آخرین اخبار و تکنولوژی های هوش مصنوعی را در اینجا بخوانید.مجله هوش مصنوعی
آخرین اخبار و تکنولوژی های هوش مصنوعی را در اینجا بخوانید.بازدید معاون علمی و فناوری رئیسجمهور از مجموعه پارت و مرکز تحقیقات هوش مصنوعی
شرکت دانشبنیان پارت روز یکشنبه ۱۲ مرداد ماه، میزبان دکتر سورنا ستاری، معاون علمی و فناوری رئیسجمهور بود. در این دیدار که با حضور دکتر علی رسولیزاده مدیرعامل شرکت دانشبنیان پارت همراه بود، دکتر ستاری از بخشهای مختلف پارت از جمله مرکز تحقیقات هوش مصنوعی پارت بازدید و از سامانههای هوش مصنوعی ساها، سهاب، هوشیو، سرویس پنلهای پهبادی و همچنین کتاب بومشناسی هوش مصنوعی رونمایی کرد.
این بازدید در ساعت ۱۴:۳۰ شروع شد و در ابتدای آن متخصصان مرکز تحقیقات هوش مصنوعی پارت توضیحاتی را در مورد پیشرفت هوش مصنوعی در کشور و پروژههای کنونی و آتی این مرکز ارائه کردند. دکتر ستاری با تاکید بر پیشرو بودن ایران در حوزه ICT افزود:
شرکت پارت از شرکتهای بزرگ این حوزه است که دارای محصولات و سرویسهایی با قابلیت صادرات است و باید مورد حمایت بیشتری قرار بگیرد و با این روند، قطعا سال آینده رشد چند برابری را تجربه خواهد کرد.
دکتر ستاری بومیبودن هوش مصنوعی را مهم ارزیابی کرد و گفت برخی از سرویسها باید حتما داخلی باشند چون به زبان فارسی و لهجههای محلی حساس هستند و نیاز است برای بهرهبرداری از سرویسهای داخلی، هوش مصنوعی بیش از پیش توسعه یابد.

همچنین در این مراسم دکتر علی رسولیزاده به سرمایهگذاری ۷ ساله پارت به میزان ۱۵ میلیارد تومان در زیرساخت فناوری و فراهمکردن توان پردازشی بیش از ۵۰۰ ترافلاپس و ایجاد تیمهای بزرگ و متخصص هوش مصنوعی اشاره کرد. مدیرعامل پارت با بیان اینکه در حال حاضر ۱۰۰ نفر متخصص هوش مصنوعی در این مرکز مشغول به کار هستند افزود نرخ رشد نیروی متخصص هوش مصنوعی در پارت سالانه ۵۰ نفر است.
مدیر عامل مجموعه پارت در معرفی سامانههای تولید شده، “سهاب” را به عنوان نخستین مارکتپِلِیس حوزه هوش مصنوعی معرفی کرد و در توضیح “ساها” گفت سامانه احراز هویت غیرحضوری است که با استفاده از هوش مصنوعی پیادهسازی شده و کاربردهای فراوانی برای احراز هویت افراد در بازار سرمایه، بانکها و آزمونها دارد. رسولیزاده در ادامه از هوشیو به عنوان پایگاه جامع محتوایی در حوزه هوش مصنوعی نام برد. این سامانه اطلاعات و آموزشهای متنوعی را در حوزههای مختلف هوش مصنوعی در اختیار مخاطبان خود قرار میدهد. همچنین سامانه معاملات الگوریتمی آیکوانت که برای فعالان بازار سرمایه توسعه داده شده است و سرویس پنلهای پهبادی از دیگر محصولاتی بودند که معرفی شدند. در انتهای این مراسم از سومین شماره سالنامه «بومشناسی هوش مصنوعی» رونمایی شد. این سالنامه روندها و شرکتهای هوش مصنوعی در ایران را بررسی میکند و به مقایسهی آن با بازار جهانی میپردازد.
مجموعه دانش بنیان پارت امیدوار است این بازدیدها دریچهای نوین را به سوی هوشمندسازی فرایندهای زندگی باز کند و بتواند به عنوان بزرگترین مرکز هوش مصنوعی کشور، فضایی را برای تعامل متخصصان و مخاطبان این حوزه فراهم آورد.
تفاوت یادگیری بانظارت و بدون نظارت
حوزه یادگیری ماشین با دو نوع یادگیری تحت عنوان یادگیری بانظارت و بدون نظارت بدون نظارتشناخته میشود. اصلیترین تفاوت یادگیری بانظارت و بدون نظارت آن است که یادگیری بانظارت با وضعیت واقعیانجام میشود؛ به عبارت دیگر، از قبل میدانیم که نمونههایمان باید چه مقادیر خروجی داشته باشند.بنابراین، هدف یادگیری بانظارت این است که تابعی را فرا گیرد که به بهترین شکل رابطه میان ورودی و خروجی را در دادهها تخمین میزند. از سوی دیگر، یادگیری بدون نظارت فاقد خروجی برچسبدار است. بر اساس این نوع یادگیری، ساختار طبیعیِ موجود در یک مجموعه نقاط دادهای استنتاج میشود.
یادگیری بانظارت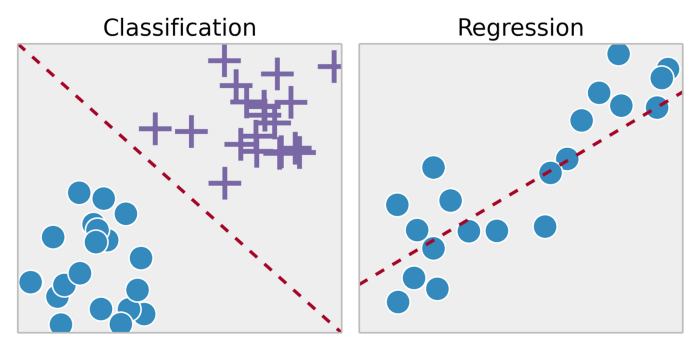
یادگیری بانظارت معمولاً در زمینه دستهبندی به کار گرفته میشود. وقتی بخواهیم ورودی را در برچسبهای گسسته خروجی یا خروجی پیوسته نگاشت دهیم، این نوع یادگیری به کارمان میآید. از جمله الگوریتمهای متداول در یادگیری بانظارت میتوان به رگرسیون لجستیک ،بیزی ساده ، ماشینهای بردار پشتیبان(SVM)، شبکههای عصبی مصنوعیو غیره اشاره کرد. در رگرسیونو دستهبندی، هدف این است که در ابتدا ساختارها یا روابط خاص در دادهها را پیدا کنیم. این کار میتواند نقش موثری در تولید دادههای خروجی صحیح داشته باشد. توجه داشته باشید که خروجی صحیح به طور کلی از دادههای آموزشی به دست میآید؛ پس گرچه این پیشفرض وجود دارد که مدلمان به درستی عمل میکند، اما نمیتوان مدعی شد که برچسب دادهها همیشه و در هر شرایطی درست و بینقص هستند. برچسبهای دادهای نویزدار یا نادرست میتوانند از تاثیرگذاری مدل کاسته و کارآیی را پایین آورند.
پیچیدگی مدلو مصالحه بایاس-واریانساز جمله نکات مهمی هستند که در هنگام بکارگیری روش یادگیری بانظارت مستلزم توجه هستند. پیچیدگی مدل اشاره به سطح پیچیدگیِ تابعی دارد که خواهان یادگیری آن هستید. ماهیت دادههای آموزشی یک عامل تعیینکننده در سطح پیچیدگی مدل برشمرده میشود. اگر میزان داده اندکی در اختیار دارید یا اگر دادههایتان در سناریوهای احتمالیِ مختلف به طور یکنواخت توزیع نشده است، باید سراغ مدلی بروید که سطح پیچیدگی کمتری دارد. زیرا اگر مدل بسیار پیچیدهای در تعداد اندکی از نقاط داده مورد استفاده قرار گیرد، مدل دچار بیشبرازش خواهد شد. بیشبرازش به یادگیری تابعی اشاره میکند که مطابقت بالایی با دادههای آموزشی دارد و امکان تعمیم آن به سایر نقاط داده وجود ندارد. به عبارت دیگر، مدل سعی میکند دادههای آموزشی خود را بدون خطا بازتولید کند در حالی که ساختار یا روندی حقیقی در دادهها را یاد نگرفته است. فرض کنید میخواهید یک منحنی را بین دو نقطه برازش کنید. از دید نظری، میتوانید از تابعی با درجه دلخواه استفاده کنید؛ اما از دید عمَلی، ترجیح میدهید که تابع خطی را برگزینید.
رابطه بایاس-واریانس
رابطه بایاس-واریانس به تعمیم مدل اشاره میکند. در همه مدلها، تعادلی میان بایاس (عبارت خطای ثابت) و واریانس (مقدار خطایی که میتواند در مجموعههای آموزشی مختلف متغیر باشد) برقرار است. بنابراین، بایاس زیاد و واریانس کم میتواند مدلی باشد که ۲۰ درصد مواقع دچار اشتباه میشود. اما مدل بایاس کم و واریانس زیاد میتواند بسته به دادههای استفاده شده برای آموزش مدل، ۵ اِلی ۵۰ درصد مواقع اشتباه کند. به این مسئله توجه داشته باشید که بایاس و واریانس در جهت مخالف یکدیگر حرکت میکنند؛ افزایش بایاس معمولاً واریانس کمتر را در پی دارد، و بالعکس.
مسئله و ماهیت دادهها در هنگام ساخت مدل باید این فرصت را در اختیارمان بگذارد تا در خصوص طیف بایاس-واریانس تصمیم آگاهانهای اتخاذ کنیم. به طور کلی، اگر سطح بایاس زیاد باشد، عملکرد مدل با تضمین کمتری همراه خواهد بود. عملکرد مدل در انجام برخی از امور اهمیت فراوانی دارد. افزون بر این، برای اینکه مدلهایی بسازیم که به خوبی قابلیت تعمیم داشته باشند، واریانس مدل باید با اندازه و پیچیدگی دادههای آموزشی همخوانی داشته باشد. معمولاً یادگیری دیتاستهای ساده و کوچک با مدلهایی انجام میشود که واریانس کمتری دارند. در حالیکه دیتاست های بزرگ و پیچیده مستلزم مدلهایی با واریانس بالاتر هستند تا ساختار دادهها را به طور کامل یاد گیرند.
یادگیری بدون نظارت
از جمله متداولترین کارهایی که میتوان با یادگیری بدون نظارت انجام داد، میتوان به خوشهبندی ، یادگیری ارائه و تخمین چگالی اشاره کرد. در همه این موارد، به دنبال یادگیری ساختار ذاتی دادهها بدون استفاده از برچسب داده¬های هستیم. برخی از الگوریتمهای رایج عبارتند از خوشه بندی k-means، تحلیل مولفه اصلی ، خود رمزگذار. چون هیچ برچسبی ارائه نشده، هیچ روش مشخصی برای مقایسه عملکرد مدل در اکثر روشهای یادگیری بدون نظارت موجود نیست. روشهای یادگیری بدون نظارت در تحلیلهای اکتشافی و کاهش بُعد نیز مورد استفاده قرار میگیرند. روشهای یادگیری بدون نظارت در تجزیه و تحلیلهای اکتشافی خیلی مفید هستند زیرا قادرند ساختار را به طور خودکار در داده شناسایی کنند. برای نمونه، اگر تحلیلگری بخواهد مصرفکنندگان را تفکیک کند، روشهای یادگیری بدون نظارت میتواند شروع بسیار خوبی برای تحلیل باشد. در مواردی که بررسی روندهای موجود در دادهها برای انسان امکانناپذیر است، روشهای یادگیری بدون نظارت میتوانند بینش مناسبی فراهم کرده و برای آزمودن تکتکِ فرضیهها به کار برده شوند. کاهش بُعد به روشهایی اطلاق میشود که دادهها را با استفاده از ویژگیها یا ستونهای کمتری به نمایش میگذارند. روشهای یادگیری بدون نظارت در اجرای این روش «کاهش بعد» کاربرد دارد. در یادگیری ارائه، یادگیری روابط میان ویژگیهای فردی در دستور کار قرار میگیرد. لذا این فرصت برایمان ایجاد میشود تا دادههای خود را با استفاده از ویژگیهای پنهان ارائه کنیم. این ساختارهای پنهان معمولا با تعداد ویژگی های کمتری نسبت به ویژگی های اولیه نمایش داده میشوند، همین مسئله به ما اجازه میدهد که پردازش بیشتری با حساسیت کمتری بر روی داده ها داشته باشیم، همچنین از این طریق ویژگی های اضافی حذف میگردند.

تفاوت یادگیری بانظارت و بدون نظارت: دستهبندی الگوریتمهای یادگیری ماشین
منبع: hooshio.com
استفاده آسان از مدل های یادگیری عمیق
هیجانانگیز است که سیستمها قادر به یادگیری از داده باشند، الگوها را شناسایی کنند و با کمترین میزان دخالت انسان به تصمیمگیری بپردازند. یادگیری عمیق به نوعی از یادگیری ماشین اطلاق میشود که از شبکههای عصبی استفاده میکند. این نوع یادگیری به سرعت در حال تبدیل شدن به ابزاری برای حل مسائل مختلف محاسباتی است. از جمله این مسائل میتوان به طبقهبندی اشیاء و سیستمهای توصیهگر اشاره کرد. با این حال، بکارگیری شبکههای عصبی آموزش دیده در حوزهها و خدمات گوناگون میتواند چالشهایی را برای مدیران زیرساختها به همراه داشته باشد. چالشهایی همچون چارچوبهای گوناگون، زیرساختهای بیاستفاده و نبود مراحل اجرایی استاندارد میتواند زمینه را برای شکست پروژههای هوش مصنوعی مهیا کند. پست حاضر بر آن است تا راهکارهای غلبه بر این چالشها را بررسی کرده و از مدل های یادگیری عمیق در مرکز داده یا ابر استفاده کند.
عموماً، ما توسعهدهندگان نرمافزار با دانشمندان داده و فناوری اطلاعات همکاری میکنیم تا مدلهای هوش مصنوعی ساخته شوند. دانشمندان داده از چارچوبهای ویژهای برای آموزشِ مدل های یادگیری عمیق یا ماشین در کاربردهای مختلف استفاده میکنند. ما مدلِ آموزش یافته را به صورت یکپارچه در قالب نرمافزار ارائه میدهیم تا مسئله حل شود. در اقدام بعد، تیم عملیات فناوری اطلاعات، نرمافزار را در مرکز داده یا ابر اجرا و مدیریت میکند.

مدل های یادگیری عمیق
دو چالش عمده در ساخت مدل های یادگیری عمیق
۱. باید از مدلها و چارچوبهای مختلفی که به توسعه الگوریتم یادگیری میافزایند، پشتیبانی کنیم. باید مسئله گردش کار را نیز مد نظر قرار داد. دانشمندان داده بر پایه دادهها و الگوریتمهای جدید به توسعه مدلهای جدید میپردازند و ما باید به طور دائم تولید را بهروزرسانی کنیم.
۲. اگر از کارت گرافیک NVIDIA برای حصول سطوح عملکردی فوقالعاده استفاده کنیم، باید به چند نکته توجه کنیم. اولاً، کارتهای گرافیک منابع محاسبه قدرتمندی هستند و شاید اجرای یک مدل در هر کارت گرافیکی بهینه نباشد. اجرای چند مدل در یک کارت گرافیک باعث نخواهد شد آنها به صورت خودکار همزمان اجرا شوند.
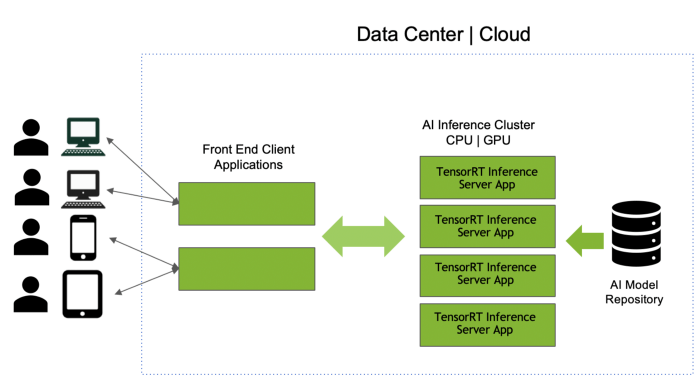
پس چه کار میتوان کرد؟ بیایید ببینیم چگونه میتوان از نرمافزاری مثل سرور استنتاجTensorRT برای رویارویی با این چالشها استفاده کرد. امکان دانلود سرور استنتاج TensorRT از NVIDIA NGC registry یا به عنوان کد منبع باز از GitHub وجود دارد.
TENSORRT INFERENCE SERVER
سرور استنتاج TensorRT با بهرهگیری از ویژگیهای زیر، استفاده از شبکههای عصبی آموزشدیده را آسان میکند:
پشتیبانی از چند چارچوب مدل: میتوان چالش اول را با استفاده از منبع مدل سرور استنتاجTensorRT بررسی کرد که نوعی محل ذخیره به شمار میآید. بنابراین، امکان توسعه مدل از چارچوبهایی مثل تنسورفلو، TensorRT، ONNX، PyTorch، Caffe، Chainer، MXNet و غیره وجود دارد. سِرور میتواند مدلهای ساخته شده در همه این چارچوبها را به کار گیرد. با اجرای inference server container در سرور CPU یا GPU، همه مدلها از منبع در حافظه بارگذاری میشود. نرمافزار از یک API استفاده میکند تا سرور inference را برای اجرای عملیات استنتاج بر روی مدل فراخوانی کند. اگر تعداد مدلهایی که نمیتوانند در حافظه جای گیرند زیاد باشد، این امکان وجود دارد که منبع را به چند منبع کوچکتر تقسیم کنیم و نمونههای مختلفی از سرور استنتاج TensorRT را به اجرا در آوریم. میتوان مدلها را به راحتی با تغییر منبع مدل بهروزرسانی، اضافه یا حذف کرد؛ حتی زمانی که سرور inference و نرمافزارمان در حال اجرا باشند.
مدل های یادگیری عمیق
افزایش حداکثریِ استفاده از کارت گرافیک: اکنون که با موفقیت سرور inference و نرمافزار را به اجرا در آوردهایم، میتوانیم چالش دوم را نیز از پیش رو برداریم. استفاده از کارت گرافیک غالباً یکی از شاخصهای عملکردی بسیار مهم برای مدیران زیرساخت است. TensorRT Inference Server میتواند به طور همزمان چندین مدل را روی GPU زمانبندی کند. این سرور به طور خودکار استفاده از GPU را به صورت حداکثری افزایش میدهد. بنابراین، ما به عنوان افراد توسعهدهنده نیازی به اجرای روشهای خاص نداریم. به جای اینکه یک مدل در هر سرور به کار برده شود، عملیات IT، کانتینر یکسان سرور استنتاجTensorRT را در همه سرورها اجرا میکند. از آنجایی که مدلهای متعددی در این عملیات مورد پشتیبانی قرار میگیرند، GPU استفاده شده و سرورها تعادل بیشتری در مقایسه با تنها یک مدل در هر سناریوی سرور خواهند داشت.
فعال سازی بلادرنگ و استنتاج دستهای: دو نوع استنتاج وجود دارد. اگر نرمافزار بخواهد به صورت بلادرنگ به نیازهای کاربران پاسخ دهد، باید استنتاج نیز به صورت بلادرنگ انجام شود. از آنجا که تاخیر همیشه مسئله نگرانکنندهای بوده است، امکان قرار دادنِ درخواستها در صف وجود ندارد و نمیتواند در کنار سایر درخواستها دسته بندی شود. از سوی دیگر، اگر هیچ الزام بلادرنگی وجود نداشته باشد، این امکان در اختیار کاربر گذاشته میشود تا این درخواست را در کنار سایر درخواستها بچیند و استفاده از GPU و بازدهی آن را افزایش دهد. در هنگام توسعه نرمافزار باید به درک خوبی از نرمافزارهای بلادرنگ دست یابیم. سرور استنتاجTensorRT پارامتری دارد که میتواند با آن یک آستانه تاخیر برای نرمافزارهای بلادرنگ لحاظ کند. این پارامتر از دستهبندی پویا نیز پشتیبانی میکند. این پارامتر میتواند با یک مقدار غیرصفر مقدار دهی شود تا درخواست های دسته ای را پیاده سازی کند. باید عملیات IT را به منظور اطمینان حاصل کردن از درستیِ پارامترها اجرا کرد.
استنتاج در CPU و GPU و دستۀ غیرهمگن: بسیاری از سازمانها از GPU عمدتاً برای آموزش استفاده میکنند. استنتاج در سرورهای عادی CPU اجرا میشود. هرچند اجرای عملیات استنتاج در GPU باعث افزایش قابل توجه سرعت کار میشود اما اینکار نیاز به انعطافپذیری بالای مدل دارد. سرور استنتاج TensorRT هر دو استنتاج CPU و GPU را پشتیبانی میکند. بگذارید این موضوع را بررسی کنیم که چطور میتوان از استنتاج CPU به GPU تغییر مسیر داد:
۱. دستۀ فعلیمان فقط مجموعهای از سرورهای CPU است که همگی سرور استنتاجTensorRT اجرا میکنند.
۲. سرورهای GPU را به دسته معرفی میکنیم و نرمافزار سرور استنتاجTensorRT را در این سرورها اجرا کنیم.
۳. مدلهای شتاب دهنده GPU را به منبع مدل اضافه میکنیم.
۴. با استفاده از فایل پیکربندی، ما سرور استنتاج TensorRT را بر روی این سرورها ایجاد میکنیم تا از GPU برای عملیات استنتاج استفاده کند.
۵. میتوانیم سرورهای CPU را دسته کنار بگذاریم یا هر دو را در حالت غیرهمگن به کار ببریم.
۶. هیچ تغییر کدی در نرمافزار برای فراخوانی سرور استنتاج TensorRT مورد نیاز نیست.
یکپارچهسازی با زیرساخت DevOps: نکته آخر بیشتر میتواند به درد تیمهای فناوری اطلاعات بخورد. آیا سازمانِ شما از DevOps تبعیت میکند؟ آن دسته از افرادی که با این عبارت آشنایی ندارند، بدانند که DevOps به مجموعهای از فرایندها و فعالیتها اطلاق میشود که چرخه توسعه و بکارگیریِ نرمافزار را کاهش میدهد. سازمانهایی که به استفاده از DevOps روی میآورند، از کانتینرها برای بستهبندی نرمافزارهایشان استفاده میکنند. سرورTensorRT یک کانتینر Docker است. تیم فناوری اطلاعات میتواند از Kubernetes برای مدیریت و مقیاسدهی استفاده کند. این امکان نیز وجود دارد که سرور استنتاج را به بخشی از خطوط لوله Kubeflow به منظور دستیابی به یک گردشکار هوش مصنوعی انتها به انتها تبدیل کنیم.
بسیار آسان است که سرور استنتاج TensorRT را بوسیله تنظیم فایل پیکربندی و تجمیع کتابخانهها، با برنامهمان تجمیع کنیم.
بکارگیریِ شبکههای عصبیِ آموزشدیده میتواند چالشهایی را به همراه داشته باشد اما هدفمان در مقاله حاضر این بود که نکات و سرنخهایی به کاربران دهیم تا فرایند بکارگیری این شبکهها به آسانی انجام شود و استفاده از مدل های یادگیری عمیق به سهولت انجام گیرد. لطفا نظرات و پیشنهادات خود را در بخش زیر وارد کنید. به ما بگویید که با چه چالشهایی در هنگام اجرای عملیات استنتاج روبرو شدید و چگونه این چالشها را از پیش رو برداشتید.
منبع: hooshio.com
چگونه می توانیم یک قطب علمی هوش مصنوعی ایجاد کنیم؟
هوش مصنوعی در چند دهه اخیر، یکی از تاثیرگذارترین فناوریهای حوزه کسبوکار بوده و نقش پررنگی دربهینهسازی بسیاری از فرآیندهای سازمانی داشته است. ما بر این باوریم که امروزه در هر شرکتی باید یک قطب علمی هوش مصنوعی وجود داشته باشد. این فناوری یک ابزار مهم در حوزه تجارت است که نباید با بیتوجهی از کنار آن گذشت.

هوش مصنوعی پایه و اساس برخی از ارزشمندترین سامانههای امروزی را تشکیل میدهد و بهزودی تبدیل به بخش جداناپذیری از دنیای کسبوکار و تجارت خواهد شد. علاوه براین، قابلیتهای هوش مصنوعی باید در طول زمان پایدار بمانند تا بتوان به کمک آن، مدلهای جدید کسبوکار را توسعه داده و پشتیبانی کرد. درحالحاضر، بسیاری از شرکتها بخش قابل توجهی از منابع مالی خود را به فنآوری هوش مصنوعی اختصاص دادهاند. افرادی که در این حوزه دارای مهارتهای ضروری و تجربه باشند بسیار کمیابند، به همین دلیل نیز باید این افرادی را گرد هم آورد تا به شکلی منسجم با یک دیگر به تعامل و همکاری بپردازند. همانطور که تجارت الکترونیک باعث ایجاد مشاغل و تیمهای جدیدی همچون مدیر ارشد دیجیتال و تیم پشتیبانی آنلاین شد، هوش مصنوعی نیز منجر به ایجاد یک قطب علمی و نقشهایی تازه در سازمانها خواهد شد.
ایده ایجاد یک مرکز یا قطب علمی هوش مصنوعی، یک ایده افراطی نیست. اخیراً در یک نظرسنجی، از هیئت مدیره شرکتهای بزرگی که از هوش مصنوعی استفاده میکنند، سؤالاتی پرسیده شد. 37% از این مدیران در پاسخ گفتند که هماکنون یک قطب علمی هوش مصنوعی در سازمان خود دارند. بانک دویچه ، جی.پی. مورگان چیس ، پِفیزر ، پروکتِر و گامبِل ، انتِم و شرکت بیمه کشاورزان در میان شرکتهای غیر فناوری هستند که تیمهایی متمرکز و منسجم در حوزه هوش مصنوعی دارند.
برخی از فناوریهای مبتنی بر هوش مصنوعی از قبیل یادگیری ماشینی در میان سازمانها شناخته شدهاند. اما یادگیری ماشینی ریشه در رگرسیون آماری دارد و همین مسئله باعث میشود که ایده ادغام تیمهای تحلیل و هوش مصنوعی به ذهن خطور کند. اگر در سازمان خود یک تیم تحلیلگر دارید که پیشبینیهای تحلیلی انجام میدهد، اعضای این تیم که به یادگیری و پیشرفت علاقهمندند، میتوانند در پروژههای هوش مصنوعی شرکت کنند و در این حوزه تخصص کسب نمایند. در این صورت، ادغام تیمها در سازمان منطقی خواهد بود.
وظایف تیم هوش مصنوعی
یک تیم هوش مصنوعی چه از دل یک تیم تحلیلگر ایجاد شده باشد، چه یک تیم کاملاً جدید باشد، مسئولیتهای زیادی بر عهده خواهد داشت. تیم هوش مصنوعی برای انجام برخی از این وظایف (از قبیل طراحی و توسعه مدلها و سیستمهای هوش مصنوعی، همکاری با نمایندگیهای فروش و ایجاد زیرساخت فنی) میتواند با شرکتهای فعال در حوزه فناوری اطلاعات همکاری کند. برخی دیگر از فعالیتهای تیم هوش مصنوعی نیز نیازمند همکاری با مدیران کسبوکارها است. اگر چه این همکاریها از اهمیت زیادی برخوردارند، اما برخی مسئولیتها نیز تنها بر عهده تیم هوش مصنوعی خواهند بود؛ این مسئولیتها به شرح زیر میباشند:
تعریف چشمانداز شرکت در حوزه هوش مصنوعی: متخصصین حوزه هوش مصنوعی باید ماهیت هوش مصنوعی، تواناییها، قابلیتها و کاربرد آن در طراحی و تعریف مدلها و استراتژیهای کسبوکار را برای مدیران اجرایی بازگو کنند؛ در غیر این صورت، ممکن است نتوانیم از حداکثر قابلیتهای هوش مصنوعی بهره ببریم.
تشریح کاربردهای هوش مصنوعی در حوزه تجارت و کسبوکار: توسعهدهندگان قابلیتهای هوش مصنوعی باید فهرستی از اولویتهای شرکت برای بهکارگیری هوش مصنوعی داشته باشند تا بتوانند میان ارزش راهبردی این کاربردها و اهداف شرکت تعادل برقرار کنند. شرکتها ممکن است تنها برای آزمون و خطا وارد برخی از حوزههای کاربردی هوش مصنوعی شوند، اما درعین حال، باید برای خود مسیری روشن نیز ترسیم کنند که منتهی به تولید محصولات و خدمات مبتنی بر هوش مصنوعی شود.
هدفگذاری مناسب و واقعگرایانه: هوش مصنوعی به جای مشاغل و فرآیندهای کلی کسبوکار، کارها و فعالیتهای جزئی را هدف قرار میدهد؛ به همین دلیل بهترین استراتژی برای تعریف پروژههای هوش مصنوعی داشتن دیدگاهی واقعگرایانه است نه بلندپروازانه. اما درهمینحین، سازمان باید تعداد زیادی پروژه کوچک را در یک حوزه مشخص تعریف و اجرا کند تا بتواند توجه مدیریت شرکت را جلب کرده و در دنیای کسبوکار مؤثر واقع شود. این کار نیازمند طراحی نقشه مسیر و تعیین کاربردهای هوش مصنوعی در طول زمان است. مرکز هوش مصنوعی میتواند به یک شرکت کمک کند که «درعین حال که بزرگ میاندیشد، قدمهای کوچکی بردارد».
تعیین معماری هدف برای دادهها: چشمانداز و کاربردهای هوش مصنوعی تعیینکننده سامانه دادهای و ابزارهای موردنیاز سازمان خواهند بود. نکته کلیدی هر پروژه (مبتنی بر داده) این است که همه انواع دادهها (یعنی دادههای ساختاریافته، ساختارنیافته و خارجی) در آنها لحاظ شوند. امروزه بهطور معمول هَدوپ سامانهای استاندارد برای مدیریت داده درنظر گرفته میشود، اما مرکز هوش مصنوعی باید بین استفاده از سامانههای محلی یا ابری و راهحلهای متنباز و عمومی یا مجوزدار تصمیم بگیرد(برای مثال، شرکتها میتوانند از یکی از سامانههای هدوپِ کلودرا ، سرویسهای تحت وب آمازون و یا سامانههای متنباز استفاده کنند). درحال حاضر اکثر شرکتها به جای استفاده از پکیجهای ابزاری که در گذشته مبتنی بر هوش تجاری بودند (همچون نسخههای ابتدایی SAS و SPSS)، از ابزارهای تحلیلی آمادهای استفاده میکنند که بخشهایی از آنها متنباز است (همچون Alteryx) و به کمک آنها میتوان به سرعت، مدلهایی کاربرپسند طراحی کرد.
آگاهی از نوآوریهای برونسازمانی: تیم هوش مصنوعی میتواند به شرکت کمک کند تا روابطش با دانشگاهها، مراکز فروش، استارتآپهای مبتنی بر هوش مصنوعی و سایر متخصصین و نوآوران را بهبود بخشد. شرکتها میتوانند یک اکوسیستم هوش مصنوعی ایجاد کنند و حتی روی شرکتهای کوچکتری که میتوانند برای کسبوکار آنها ارزشآفرین باشند، سرمایهگذاری کنند. به علاوه، آگاهی از نوآوریها جدید به شرکت کمک میکند تا بهترین ابزارها و فناوریها را در اختیار بگیرد.
ایجاد شبکهای متشکل از حامیان هوش مصنوعی: در صورت ایجاد شبکهای متشکل از طرفدارن و حامیان، بهکارگیری فناوری در حوزه کسبوکار، عملکرد مرکز هوش مصنوعی به بالاترین سطح خود خواهد رسید. فرآیند ایجاد چنین شبکهای در بسیاری از شرکتها آغاز شده است. براساس نظرسنجی سازمان حسابرسی دلویت در سال 2018، 45% از شرکتها، مدیران ارشد خود را به عنوان حامی و طرفدار هوش مصنوعی معرفی کردند. با تجاریسازی شدن برنامهنویسی (در اثر روی کار آمدن زبانهای برنامهنویسی آسانی همچون R و پایتون)، شرکتها برای ایجاد قابلیتهای درونسازمانی باید بهجای برنامهنویسی، بیشتر بر مباحث مدلسازی آماری و ریاضی متمرکز شوند.
انتشار داستان موفقیتها: یکی از عوامل کلیدی در موفقیت هوش مصنوعی و یا هر فناوری جدیدی، انتشار داستان موفقیتها و دستآوردهای اولیه آن در حوزههایی است که برای مخاطبین در اولویت قرار دارند. بدین ترتیب میتوان اشتیاق و رغبت افراد به فعالیتهای مبتنی بر هوش مصنوعی را افزایش داد. بازگو کردن این قبیل داستانها میتواند نوعی بازاریابی برای مرکز هوش مصنوعی نیز باشد.
جذب و پرورش استعدادها
یک عامل بسیار مهم در موفقیت مرکز هوش مصنوعی، جذب و یا پرورش افراد مستعد است. این حقیقت بر هیچکس پوشیده نیست که استخدام یک مهندس هوش مصنوعی یا دانشمند داده (آماردان) حرفهای حتی در سیلیکُون وَلی نیز تا چه حد دشوار است. سازمانها اغلب برای طراحی و اجرای الگوریتمهای هوش مصنوعی به تعداد زیادی نیروی انسانی نیاز ندارند و افرادی که دکترای هوش مصنوعی یا علوم رایانه داشته باشند، برای این جایگاه شغلی مناسبند. اما برای به انجام رسیدن بسیاری از امور مربوط به کسبوکار در یک مرکز هوش مصنوعی، به تحلیلگرانی با مدرک دانشگاهی MBA نیاز است که با مفاهیم و قابلیتهای هوش مصنوعی آشنایی داشته و بتوانند از ابزارهای خودکار یادگیری ماشینی استفاده کنند. البته میتوانید در ابتدا با استخدام مشاورین و فروشندگان، کار بر روی پروژههای ساده و اولیه را آغاز کنید. اما ادغام این تیم با سایر تیمهای شرکت اجتنابناپذیر است.
ممکن است شما به تازگی به فکر پرورش استعدادها در حوزه هوش مصنوعی افتاده باشید. آموزش مباحث هوش مصنوعی به کارمندانی که حتی اندکی با علوم دادهای آشنا هستند، غیرممکن نیست. برخی از شرکتها همچون سیسکو با همکاری دانشگاهها، دورههای آموزشی در حوزه علم داده برای کارمندان خود برگزار کردند. این دورهها در انتها متخصصینی دارای مدرک معتبر به شرکت تحویل دادند. این رویکرد را میتوان در حوزه هوش مصنوعی نیز به کار بست.
شرکتهایی همچون ریپلای و دیتاروبوت و دانشگاههایی همچون اِمآیتی ، دورههای آموزشی کوتاه و جامعی ارائه میدهند که در آنها مهارتهای متناسب با نیاز شرکتها و یا بهطورکلیتر، مهارتهای موردنیاز در حوزه هوش مصنوعی، به دانشجویان آموزش داده میشود.
فرآیندها و ساختارهای سازمانی
درواقع نمیتوان با قاطعیت گفت کدامیک از انواع ساختارهای سازمانی مناسب یک مرکز هوش مصنوعی است، اما ما بر این باوریم که سازمانها در اغلب موارد، با ایجاد یک ساختار متمرکز و داشتن کارمندانی رسمی که باید در برابر یک واحد اداری فراگیر پاسخگو باشند، موفقتر خواهند بود. همانطور که میدانید، افراد بااستعداد در حوزه هوش مصنوعی کمیابند، به همین دلیل، اگر این افراد در سازمان پراکنده باشند، نمیتوان یک تیم قدرتمند ساخت. براساس تجربهای که در زمان ایجاد تیم تحلیلگر بهدست آوردیم، متمرکزسازی فعالیتها منجر به افزایش رضایت شغلی و بقای این قبیل نقشها در سازمان خواهد شد.
برای پرهیز از تشریفات غیرضروری اداری، تیم متمرکز هوش مصنوعی باید به تعدادی از اعضای خود وظایفی در حوزه امور اداری بدهد، البته منظور اموری است که ممکن است تیم هوش مصنوعی به آنها نیاز پیدا کند. بدین ترتیب، کارمندان مرکز هوش مصنوعی با مسائل و مشکلات اداریِ تیم نیز آشنا خواهند شد و میتوانند با مدیران کلیدی شرکت ارتباط برقرار کنند. تغییر وظایف و مسئولیتهای افراد در درون یک واحد اداری میتواند دانش افراد را افزایش و روند انتقال دانش میان آنها را بهبود بخشد. با فراگیر شدن هوش مصنوعی، کارمندان رسمی میتوانند خطوط گزارشدهی سازمانی و اولیه خود را به بخشهای اداری منتقل کنند.
تیم هوش مصنوعی باید در زمینههای مختلفی گزارش تهیه کند، اما از نظر ما بهترین تیم برای دریافت این گزارش، تیمی است که مسئول طراحی راهبردها و فعالیتهای دیجیتال شرکت باشد. شرکت ProSiebenSat.1 (که بزرگترین شرکت خصوصی رسانهای در آلمان است) تیم تحلیل داده خود را بین دو تیم کسبوکار تجاری و فناوری اطلاعات قرار داده تا بتواند بر روی طراحی یک مدل کسبوکار جدید در حوزه اقتصاد سامانهای تمرکز کند. تیمهای هوش مصنوعی و تحلیل در شرکت Versicherungskammer (بزرگترین شرکت دولتی بیمه در آلمان) گزارشهای خود را به مدیر ارشد اطلاعات این شرکت ارائه میدهند. تیم هوش مصنوعی شرکت پروکتر اند گامبل نیز با تلاش مشترک تیمهای تحقیق و توسعه (R&D) و فناوری اطلاعات (IT) شکل گرفت. در شرکت اَنتم، قطب علمی هوش مصنوعی گزارش فعالیتهای خود را به مدیر ارشد دیجیتال این شرکت ارائه میدهد.
در اجرای پروژههای هوش مصنوعی همچون بسیاری از پروژههای فناوری دیگر، داشتن سرعت مهمترین عامل موفقیت است. بنابراین، تعریف دستاوردهای کوتاهمدت و برگزاری جلسات مکرر با سهامداران بهترین راهبرد برای اجرای این قبیل پروژههاست. البته، اگر سیستم به توسعه یا یکپارچهسازی اساسی نیاز داشته باشد، میتوان سایر روشهای سنتی مدیریت پروژه را نیز بهکار گرفت.
ممکن است برخی از فعالیتهای هوش مصنوعی با اصول اخلاقی تناقض داشته باشد، به همین دلیل هرگز نباید در صورت مواجهه با چنین مسائلی، آنها را نادیده بگیرید. ممکن است یک شرکت قصد داشته باشد که به عنوان بخشی از فعالیتهای خود در زمینه هوش مصنوعی، موضعی اخلاقی اتخاذ کند یا یک هیئت بازنگری در این زمینه تشکیل دهد. برای مثال، در شرکت مایکروسافت سمت جدیدی با عنوان «کارشناس اخلاقشناسی در حوزه هوش مصنوعی» تعریف شده است که کمک به سایر کسبوکارها در حوزه مسائل اخلاقی هوش مصنوعی از جمله بایاس الگوریتمی و بررسی تأثیرات نرمافزارهای هوش مصنوعی بر مصرفکنندگان از جمله وظایف این کارشناس است.
کسبوکارها برای رسیدن به موفقیت باید منابع خود را نظم بخشیده و تمرکز آنها را حفظ کنند. همانطور که میدانید افراد بااستعداد و متخصص در حوزه هوش مصنوعی کمیابند و به همین دلیل، این افراد به عنوان یکی از منابع موردنیاز شرکت برای ایجاد یک قطب علمی در حوزه هوش مصنوعی، اهمیت بیشتری از سایر منابع خواهند داشت. به نظر ما، در عمل یک سازمان نمیتواند بدون تخصیص یک بخش مجزا به هوش مصنوعی و کاربردهای آن، موفقیت چشمگیری در این حوزه کسب نماید.
منبع: hooshio.com
با رپلیکا یک دوست هوش مصنوعی داشته باشید
این روزها در شبکههای اجتماعی صحبت از یک دوست عجیب و غریب است؛ دوستی که هیچوقت قرار نیست او را ببینید. این چتبات هوشمند که رپلیکا نام دارد باعث بهوجود آمدن بحثهای داغی در میان کاربران توییتر و اینستاگرام شده است. بسیاری با ذوقزدگی از کشف این دوست میگویند، برخی از این موقعیت ترسناک و نگرانکننده میگویند و چند نفری هم گفتهاند این ربات حتی از دوستان واقعیام احساسات پیچیدهتری از خود نشان میدهد!

رپلیکا توسط Eugenia Kuyda با ایده ایجاد یک هوش مصنوعی و با استفاده از یادگیری عمیق شخصی ایجاد شد که به شما کمک میکند با ارائه یک مکالمه خود را معرفی کنید. رپلیکا فضایی است که میتوانید با خیال راحت و بدون ترس از قضاوت، افکار، احساسات، اعتقادات، تجربیات، خاطرات، رویاها و دنیای خصوصی خود را به اشتراک بگذارید. با وجود اینکه چندین سال از معرفی و عرضه رپلیکا میگذرد اما چیزی که باعث شهرت آن در این روزها شده، همهگیری ویروس کرونا است. بنیانگذار رپلیکا میگوید: این برنامه شاهد افزایش دانلود و استفاده از آن پس از شیوع بیماری کووید 19 شده است و این نشان میدهد مردم دوران سختی را پشت سر میگذارند.
کویدا میگوید پس از اینکه با روانشناسان بالینی صحبت کردیم و به داستانهای افراد گوش دادیم متوجه شدیم که رپلیکا به آنها کمک میکند تا با انزوا کنار بیایند و احساس ارتباط بیشتری کنند. از سوی دیگر با وجود جذاببودن رپلیکا، استفاده از آن به نگرانیهایی در مورد تعاملات اجتماعی انسانها دامن زده است. برخی از کاربران رپلیکا گفتند زمانی که کروناویروس آنها را از بسیاری از دوستان و همکاران جدا کرده است این ربات کمی مایه آرامش است. اما برخی از محققانی که روی افرادی که ساعات زیادی با با فناوری در ارتباط هستند پژوهش کردهاند خیلی با این قضیه موافق نیستند. شری ترکل استاد مطالعات اجتماعی علوم و فناوری در ماساچوست میگوید: "همه ما زمان زیادی را غرق در افکار خود میگذرانیم و جای تعجب نیست که اگر فرصتی برای صحبت با یک ربات به دست بیاوریم آن را امتحان کنیم، اما این باعث میشود تواناییهای هیجانی و عاطفی ما که برای توسعه نیاز به مکالمه با آدمهای واقعی دارند به رشد و تکامل کافی نرسند.
علیرغم مشکلاتی که رپلیکا دارد، صدها هزار نفر مرتباً از آن استفاده میکنند و بیش از 7 میلیون کاربر آن به طور متوسط روزانه حدود 70 پیام ارسال میکنند. اگرچه هنوز فاصله زیادی بین سامانتا هوش مصنوعی فیلم Her و رپلیکا وجود دارد اما رشد سریع هوش مصنوعی میتواند در آیندهای نزدیک ما را غافلگیر کند. از لینکهای زیر میتوانید رپلیکا را دانلود و این تجربه جالب را امتحان کنید:
منبع: hooshio.com