بیشک در عصری که پیش رو داریم، هوش مصنوعی
به یک نیروی درحال رشد در کسبوکارها تبدیل شده است؛ تا جایی که برترین
شرکت های هوش مصنوعی امروز، رهبران این فناوری در حال ظهور در تمام دنیا
هستند!
برترین شرکت های هوش مصنوعی که غالباً از رایانش ابری
و محاسبات لبهای در فرایندهای خود بهره میگیرند، به واسطه امتیازات آن،
فناوریهای بیشماری را با هم ترکیب میکنند تا انتظارات مشتریان خود را
در خانه، محل کار و جامعه بیشتر برآورده کنند. یادگیری ماشینی اصلیترین
نیروی هدایتگر این جریان است، اما شرکتهای برجسته هوش مصنوعی امروزه در
حال گسترش دامنه فناوری خود در دیگر جنبههای فناورانه و عملیاتی هستند: از
تجزیهوتحلیل پیشبینی شده تا هوش تجاری تا ابزار انبار داده تا یادگیری عمیق، چندین نقطه ضعف و گلوگاه صنعتی و شخصی را کاهش میدهند.
تمام
صنایع در حال تاثیرپذیری از جریان تحولات فناوری هوش مصنوعی هستند و این
تکنولوژی نوظهور باعث دگرگونی در همه جنبهها شده است. شرکتهای مبتنی بر
اتوماسیون فرایند روباتیک یا RPA، پلتفرمهای خود را کاملاً تغییر
دادهاند و با هوش مصنوعی همگام شدهاند. هوش مصنوعی در بخش خدمات مشتریان
و فرایندهای داخلی کسبوکارها در حال تغییر روشهای گذشته است.
مراکز
تحقیقاتی و دانشگاهی پژوهشهای خود در حوزه هوش مصنوعی را روزبهروز
گستردهتر میکنند و همچنین فرصتهای شغلی هوش مصنوعی در بسیاری از صنایع
به سرعت درحال رشد است. برترین شرکت های هوش مصنوعی سرمایهگذاری
گستردهای را از شرکتهای سرمایهگذار خطرپذیر و شرکتهای عظیم مانند
مایکروسافت و گوگل جذب میکنند و همین موضوع احتمال رشد بیشتر آنها در
آینده را پیشبینی میکند.
شرکت
Accenture که به عنوان یک غول در حوزه مشاور فناوری در حال فعالیت است، در
این زمینه استدلال میکند: هوش مصنوعی این توانایی را دارد که نرخ سودآوری
را به طور متوسط ۳۸٪ افزایش دهد و میتواند منجر به افزایش رشد عظیم
اقتصادی ۱۴ تریلیون دلاری ارزش افزوده ناخالص (GVA) تا سال ۲۰۳۵ شود.
به
ویژه در طول همهگیری بیماری COVID-19، حوزههایی مانند مراقبتهای
بهداشتی علاقه به فعالیت و سرمایهگذاری در زمینه هوش مصنوعی را به طور
فرایندهای اعلام داشتهاند، با این امید که تجربیات بیمار را در زمینه
پزشکی از راه دور، تصویربرداری دیجیتال و انواع دیگر زمینهها گردآوری کنند
و به بیماران دسترسی بیشتری به منابع پزشکی مورد نیاز خود دهند.
حتی
در طی همهگیری بیماری کووید ۱۹ که اکثر صنایع کل هزینههای خود را برای
زنده ماندن کاهش دادند، بسیاری از برترین شرکت های هوش مصنوعی در سال ۲۰۲۰
سرمایهگذاریهای خود در این حوزه را افزایش دادند.
برترین شرکتهای هوش مصنوعی و رهبران ابر!
ارائهدهندگان
خدمات هایتکنولوژی با ارائه راهکارهای مبتنی بر هوش مصنوعی و یادگیری
ماشین از طریق سیستمعاملهای ابری محبوب خود، بازار را رهبری میکنند و به
دیگر شرکتها امکان میدهند هوش مصنوعی را بدون هزینه توسعه داخلی، در
برنامهها و سیستمهای خود ادغام کنند. این جریان، نهتنها به سود بیشتر
غولهای فناوری میانجامد، که حتی به روند توسعه شرکتهای درحال رشد نیز
سرعت میبخشد.
آمازون
غول
تجارت «آمازون» هم در حوزه مشتریمداری هوش مصنوعی و هم در برنامههای
کاربردی مربوط به شرکتها و فرایندهای آنها سرمایهگذاری کرده است.
وبسرویس آمازون یا (AWS)، به عنوان یکی از رهبران برجسته در محاسبات
ابری شناخته میشود که محصولات و خدمات هوش مصنوعی مربوط به پشتیبانی
مشتریان را ارائه میدهد و بسیاری از خدمات هوش مصنوعی پیشرفته خود را بر
پایه خدمات هوش مصنوعی موجود در محصولات مصرفی توسعه داده است.
الکسا،
دستیار زبان هوش مصنوعی شرکت آمازون که در سری بلندگوهای echo ادغام شده،
حالا دیگر در سراسر جهان شناخته شده است. آمازون اکو از طریق سرور صدای
هوشمند الکسا، هوش مصنوعی را به خانههای ما آورده است. از سوی دیگر،
وبسرویسهای آمازون (AWS)، مجموعهای از برنامههای یادگیری ماشین و
خدمات هوش مصنوعی توسعه داده شده برای کسبوکارها هستند که هنوز
ماموریتهای زیادی برای انجام دارند! از میان وبسرویسهای آمازون، خدمات
هوش مصنوعی اصلی شرکت شامل این محصولات میشود: هوش مصنوعی Lex که یک نسخه
تجاری الکسا است؛ هوش مصنوعی Polly که متن را به گفتار تبدیل میکند؛ و
هوش مصنوعی Rekognition که یک سرویس تشخیص تصویر است. وبسرویس آمازون
(AWS) در حال حاضر بیش از ۱۰،۰۰۰ مشتری دارد، از جمله زیمنس، Netflix،
Tinder، NFL و ناسا.
ابر گوگل
شاید
بزرگترین و مهمترین شرکت هوش مصنوعی در این لیست، بارزترین و
پرآوازهترین آنها نیز باشد. گوگل، یکی از پیشروترین شرکتهای هوش مصنوعی
در جهان، در سالهای اخیر، گوگل استارتاپهای هوش مصنوعی متعددی را خریداری
کرده است و این نشان میدهد مدیران و توسعهدهندگان گوگل واقعاً به
پیشرفتها و قابلیتهای هوش مصنوعی اعتقاد دارند. ابر گوگل علاوه بر
استفاده از هوش مصنوعی برای بهبود خدمات خود، چندین سرویس هوش مصنوعی و
یادگیری ماشین را نیز به کسبوکارها و شرکتها میفروشد. پلتفرم ابر گوگل
نرمافزار پیشرو در صنعت TensorFlow را که اکنون برای همه رایگان است و
همچنین تراشه AI Tensor در زمینه یادگیری ماشین را نیز در مجموعه پروژههای
موفق و رو به پیشرفت خود دارد.
گوگل
حقیقتا در زمینه توسعه هوش مصنوعی و تجزیهوتحلیل دادهها پیشرو است و
برای ارتقای قابلیتهای هوش مصنوعی سرمایهگذاریهای بزرگی انجام داده
است. مهمترین خرید ابر گوگل، معامله ۴۰۰ میلیون دلاری DeepMind بوده است.
شرکت IBM
شرکت
چندملیتی IBM از دهه ۱۹۵۰ در زمینه هوش مصنوعی فعال است. این شرکت در تولد
فناوری هوش مصنوعی نقش اساسی داشته و تا امروز نیز به مسئولیت خود در
حمایت و توسعه هوش مصنوعی کاملا متعهد بوده است. شرکت IBM با استفاده از
هوش مصنوعی واتسون، یک پلتفرم یادگیری ماشین ایجاد کرده است که میتواند
هوش مصنوعی را در فرایندهای تجاری ادغام کند؛ مانند ساخت یک چتبات برای
پشتیبانی مشتریان. خریداران محصولات IBM و مشتریان اصلی این شرکت عبارتند
از: Big Four Auditor، KPMG و Bradesco که یکی از بزرگترین بانکهای برزیل
است.
تلاشهای
IBM در سالهای اخیر متمرکز بر واتسون بوده که یک سرویس شناختی مبتنی بر
هوش مصنوعی است. واتسون شامل نرمافزار هوش مصنوعی به عنوان یک سرویس، و
سیستمهای مقیاسبندی طراحی شده برای ارائه تجزیهوتحلیل مبتنی بر ابر و
خدمات هوش مصنوعی است. این پروژه طی چندین سال و با خرید چندین استارت آپ
هوش مصنوعی سودآور همراه بوده است. هوش مصنوعی واتسون از یک پلتفرم ابر
قدرتمند بهرهمند است.
مایکروسافت
مایکروسافت
نیز مانند آمازون، هم از جنبه خدمات مصرفکنندگان و هم در حوزه کسبوکار،
ارتباطی تنگاتنگ با هوش مصنوعی دارد. کورتانا، دستیار دیجیتال هوش مصنوعی
مایکروسافت، با الکسا، سیری و دستیار گوگل در رقابت مستقیم است. فیچرهای
هوش مصنوعی، بخش بزرگی از خدمات Azure Cloud مایکروسافت است که به برخی از
بزرگترین نامهای تجاری، سرویسهای چتبات و خدمات یادگیری ماشین ارائه
میدهد. مایکروسافت فقط در سال ۲۰۱۸ موفق شد پنج شرکت هوش مصنوعی را
خریداری کند.
مایکروسافت
ترکیبی از پروژههای هوش مصنوعی مرتبط با مشتریان و کسبوکارهای فناوری
اطلاعات را ارائه میدهد. محصولاتی که از این شرکت در گروه مربوط به
مصرفکنندگان جای میگیرد، عبارتند از: کورتانا، دستیار دیجیتال همراه با
ویندوز و غیر از ویندوز فون و چتبات Zo که مانند نوجوان صحبت میکند.
مایکروسافت در سرویس ابر Azure خود، خدمات هوش مصنوعی مانند سرویسهای
رباتی، یادگیری ماشین و خدمات شناختی را به فروش میرساند.
هوش مصنوعی همه جا هست!
از
گوگل و آمازون گرفته تا IBM و مایکروسافت، هر شرکت بزرگ فناوری در حال
اختصاص منابع مالی و سرمایهگذاری برای دستیابی به موفقیت در هوش مصنوعی
است. دستیاران شخصی مانند سیری و الکسا هوش مصنوعی را به بخشی از زندگی
روزمره ما تبدیل کردهاند. در همین حال، دستیابی به موفقیتهای انقلابی
همچون به دست گرفتن بازار هوش مصنوعی جهان و تبدیل شدن به یکی از برترین
شرکت های هوش مصنوعی ممکن است یک امر عادی نباشد، اما مطمئناً قابل دسترس
است.
رد
پای فنآوریهای هوش مصنوعی در تمامی حوزههای کسبوکار، از خردهفروشی
گرفته تا مهندسی هوا و فضا، به چشم میخورد. هنرمندان با تکیه بر تجارب
ذهنی و حسیشان به خلق آثار هنری میپردازند و هیچ الگوریتمی یارای رقابت
کردن با آنها را ندارد. با این حال، کاربرد هوش مصنوعی در موسیقی،
آهنگسازی و توسعه پلتفرمهای پخش موسیقی مورد استفاده زیادی دارد. برای
آشنایی بیشتر با برنامههای موسیقی مجهز به AIتا پایان این نوشتار با ما
همراه باشید.
کاربرد هوش مصنوعی در موسیقی و آهنگسازی
طبق
گزارش مؤسسه مککینزی تا سال ۲۰۳۰، ۷۰ درصد از شرکتها حداقل از یکی از
فنآوریهای AI استفاده میکنند. صنعت موسیقی نیز از این قاعده مستثنی
نیست. با ظهور تیکتاک و افزایش تعداد یوتیوبرها، که موسیقی لازمه
هنرآفرینیشان است، اهمیت وجود ابزارهای تولید موسیقی مجهز به AI بیش از
پیش آشکار میشود.
مثلا
Amper را در نظر بگیرید! Amper ابزاری است که با استفاده از فنآوری هوش
مصنوعی برای سازندگان بازی، رسانهها و دیگر فنآوریهای تعاملی موسیقی
تولید میکند. این ابزار برای ساخت یک قطعه موسیقی جدید از نمونه کتابخانه
و دیتاستهایش استفاده میکند. Amper تا پیش از روی کارآمدن Shutterstock
محبوبترین ابزار تولید موسیقی در بازار شناخته میشد. ShutterStock یکی از
بزرگترین تولیدکنندگان محتوا برای سازندگان است و در نهایت اواخر سال
۲۰۲۰ توانست گوی سبقت را از Amper برباید.
برجستهترین
کاربرد هوش مصنوعی در موسیقی AIVA است. AIVA یک پلتفرم هوش مصنوعی است که
بر تولید موسیقی کلاسیک تمرکز دارد و بهداشتن مشتریانی همچون Nvidia، TED،
Vodafone افتخار میکند و قطعات موسیقی با حق امتیاز نامحدود
(Royalty-free) و سفارشی برای آنان تولید میکند. در ساخت این پلتفرم از
الگوریتمهای DL استفاده شده که بر روی تعداد زیادی موسیقی ارکستر آموزش
دیدهاند. یکی دیگر از مزایای این پلتفرم رابط کاربری فوقالعاده آن است.
یا
Loudly، این کسبوکار نوپا در برلین واقع شده و در زمینه تولید موسیقی
فعالیت دارد؛ در وبسایت رسمی این شرکت، شعار“Designed by creators, for
creators” به چشم میخورد. سیستم این پلتفرم میتواند قطعات موسیقی را
بازنویسی کنید و با استفاده از الگوریتمهای یادگیری عمیق
GAN قطعات موسیقی سفارشی تولید کند. علاوه بر این، Loudly دارای نمونه
حافظه (برای ذخیره موسیقی)، برنامه آهنگسازی و یک پلتفرم اجتماعی است که
سازندگان موسیقی میتوانند در آن با هم مشارکت داشته باشند.
برای
قطعات موسیقی که هوش مصنوعی تولید میکند، مسئله قوانین حق نشر
(Copyright) مطرح میشود. مسئله این است که هوش مصنوعی موسیقی را تولید
کرده اما برای آموزش آن از دادههای موسیقیایی هنرمندان حقیقی استفاده شده
است، در چنین شرایطی حق امتیاز تولید موسیقی به چه کسی تعلق دارد؟ علاوه بر
این، بسیاری از حوزههای قضایی، از جمله ایالات متحده، اسپانیا و آلمان
کماکان بر این باروند که فقط قطعات موسیقی که انسانها تولید میکنند،
مشمول قانون حق نشر (copyright) میشوند.
هوش مصنوعی و پخش موسیقی
پخشکنندههای
(player)موسیقی نیز از آسیبهای ناشی از شیوع ویروس کرونا در امان نبوده
اند. با این حال، ارزش بازار پخشکنندههای موسیقی در سال ۲۰۲۰ به ۶/۲۱
میلیارد دلار آمریکا رسید و رشد ۴/۷ درصدی را تجربه کرد. به گفته فدراسیون
بینالمللی صنعت آواشناسی (IFPI) صنعت ضبط موسیقی در سال ۲۰۱۴ و پس از یک
دهه رکود، دوباره رونق گرفت. در سال ۲۰۲۰، سرویسهای پخش موسیقی ۱/۶۲ درصد
از مجموع درآمد حاصل از ضبط موسیقی را به خود اختصاص دادند و به همین دلیل
نمیتوان نقش آنها در احیای این صنعت را نایده گرفت.
صنعت
پخش موسیقی در سراسر جهان روند صعودی دارد و از این لحاظ آمریکای لاتین و
آسیا پویاترین بازارها را دارند ( ارزش بازارهای پخش موسیقی در این کشور به
ترتیب ۲/۳۰ درصد و ۹/۲۹ درصد رشد داشته است). ارزش سرویسهای پخش موسیقی
در بازارهای آفریقا و خاورمیانه نیز در حال رشد است و بازارهای اروپا و
آمریکای شمالی را نیز در دست دارد.
هوش مصنوعی، به ویژه یادگیری ماشین
و یادگیری عمیق، به همراه سیستمهای توصیهگر خود زیربنای تمامی این
سرویسها را تشکیل میدهد و تجربه فوقالعادهای برای شنوندگان فراهم
میآورد. برای کسب اطلاعات بیشتر مقاله سیستمهای توصیهگر مبتنی بر
یادگیری عمیق را مطالعه کنید.
کاربرد
هوش مصنوعی در موسیقی چگونه میتواند علاقه شنوندگان را به سرویسهای پخش
موسیقی جلب کند؟ برای یافتن پاسخ این سؤال بهتر است نگاهی به بزرگترین
سهامداران این بازار بیندازیم.
در
نیمه دوم سال ۲۰۲۰، ۳۴ درصد از کاربران سراسر جهان از Spotify و ۲۱ درصد
از آنها از Apple Music برای گوش دادن به موسیقی استفاده میکردند. چه
چیزی Spotify را خاص کرده است؟ دو کلمه جادویی: هوش مصنوعی!
به لحاظ فنی و تخصصی، پشته Spotify از سه لایه تشکیل میشود و هر کدام از آنها به علوم داده و یادگیری ماشین مجهز هستند:
داده
اولین لایه را تشکیل میدهد و تمامی دادههای مربوط به کاربران، از جمله
دادههای جمعیت شناختی، عادتهای گوش دادن به موسیقی و سایر دادهها رفتاری
را در برمیگیرد. هرچه میزان دادهها بیشتر باشد، سیستم آهنگهای بهتری را
به کاربر پیشنهاد میکند. در زمان نگارش این مقاله، روزانه ۰۰۰/۶۰ آهنگ به
Spotify اضافه میشود.
مدلهای مشترک لایه میانی را تشکیل میدهند
و اطلاعات مربوط به علایق کاربر (برای مثال، خوانندگان و آهنگهای مورد
علاقه کاربر)، تعبیهی تشابهات ( این تعبیه شباهتهایی که میان خوانندگان،
فهرست پخش (playlist) و قطعات موسیقی وجود دارد را مشخص میکند) را در بر
میگیرد و آیتمها را خوشهبندی میکند.
ویژگیها لایه فوقانی را
تشکیل میدهند. در این لایه مدلهای یادگیری ماشین با استفاده از دادههای
به دستآمده از دو لایه اول، آهنگهایی که احتمال دارد مورد پسند کاربر
قرار گیرند را به وی پیشنهاد میدهد.
Spotify
در صفحه اصلیاش، تجربهای شخصیسازی شده و بافتآگاه برای کاربران به
ارمغان میآورد؛ این صفحه برای ارائه چنین تجربهای، تمامی عوامل دخیل از
جمله دستگاه مورد استفاده (موبایل، کامیپوتر شخصی و …) ، موسیقی در حال
پخش، روندهای کنونی و روزِ هفته و ساعات روز و غیره را در نظر میگیرد.
چنین قابلتی در نتیجه استفاده از سیستم درختان رگرسیون جمعی بیزی (BART)
محقق میشود. BART یک مدل پیشبینی کننده انعطافپذیر و یک رویکرد یادگیری
ماشین برای حل مسائل مربوط به پیشبینی و طبقه بندی است.
تحلیل، متسرینگ و آموزش موسیقی به کمک هوش مصنوعی
توانایی
فنآوریهای AI فقط به آهنگسازی و سرویسهای پخش موسیقی محدود نمیشود.
درواقع کاربرد هوش مصنوعی در موسیقی کاربردهای بیشتری دارد. علیرغم
جنجالهایی که در مورد سیطرهی هوش مصنوعی در موسیقی وجود دارد، این
فنآوری به کاهش میزان کپی و پخش غیرقانونی موسیقی، پردازش صدا، مسترینگو
آموزش موسیقی کمک میکند.
برای
مثال، شرکتBMAT، که در بارسلونا واقع شده است به شرکتهای پخشکننده،
ناشران و شرکتهای ضبط موسیقی کمک میکند قطعات موسیقیشان که در
پلتفرمهای مختلف پخش میشوند را ردیابی کنند. این شرکت با استفاده از
فنآوریهای هوش مصنوعی دادههایی با حجم بسیار زیاد را پردازش میکند. این
شرکت برای تشخیص شباهتهای موجود میان اصوات، از فنآوری اثر انگشت صوتی
به عنوان نسخه فشردهای از قطعه موسیقی استفاده میکند. الگوریتمهای
یادگیری ماشین شباهتهایی را که میان نتهای موسیقی و حتی موسیقی پس زمینه
وجود دارد ردیابی میکنند.
علاوه بر این، فناوری هوش مصنوعی
به مسترینگ موسیقی که فرایندی هزینهبر برای تولیدکنندگان است، کمک
میکند. برای مثال، LANDR، پلتفرمی نوین است که به کمک آهنگسازان آمده و با
استفاده از یادگیری ماشین، قطعات موسیقی را اصلاح میکند. این پلتفرم بر
روی یک پایگاه فریمیوم (freemium) اجرا میشود و خدمات متنوعی ارائه
میدهد. موتور مسترینگ این پلتفرم مجهز به هوش مصنوعی است و بر روی
دادههای مربوط به قطعات موسیقی مسترشده آموزش دیده و الگوریتمهای آن
قطعات موسیقی را بر اساس سَبک دستهبندی میکنند.
علاوه
بر این، برنامههایی مجهز به هوش مصنوعی برای آموزش آلات موسیقی تولیده
شده است. برنامههایی همچون Yousicion و Jamstick ابزارهایی برای یادگیری
آلات موسیقی هستند و بازخوردهایی در مورد روند پیشرفتتان به شما میدهند.
سخن پایانی
تا
سال ۲۰۳۰، ۷۰ درصد از شرکتها به استفاده از فنآوریهای هوش مصنوعی روی
میآورند و استفاده از هوش مصنوعی در موسیقی یعنی در این صنعت هم تغییراتی
ایجاد خواهد شد. البته جای نگرانی نیست! هوش مصنوعی هنوز نمیتواند جایگزین
هنرمندان شود و همانند آنها تجارب حسی و ذهنی خود را به شکل قطعهای
موسیقی عرضه کند.
با این
حال، فنآوریهای هوش مصنوعی میتوانند قطعات موسیقی با حق انحصاری
نامحدود، پلتفرمهای مسترینگ موسیقی، برنامههای آموزشی (که روند پیشرفت
هنرآموزان را به اطلاع آنها میرساند) تولید کنند و علاوه به حفاظت از
قانون کپیرایت کمک میکند. در ضمن، توسعه پلتفرمهای پخش موسیقی همواره در
سراسر جهان ادامه خواهد یافت. بخش بزرگی از درآمد صنعت موسیقی از طریق این
پلتفرمها به دست میآید. آهنگسازان نیز برای آنکه آهنگهایشان در
فهرستهای موسیقی (playlist) پلتفرمهای پخش قرار بگیرد، به استفاده از
الگوریتمها روی خواهند آورد.
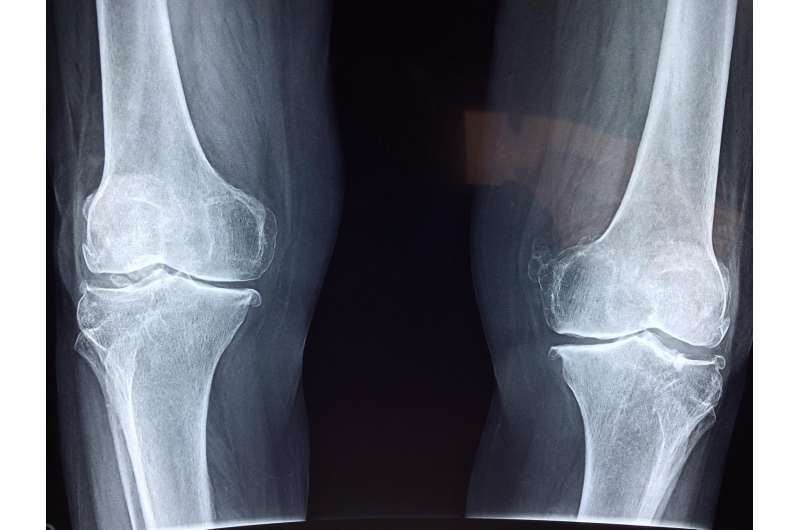
آرتروز
زانو یک بیماری جهانی است. تقریبا نیمی از افراد بالای ۷۵ سال با یکی از
انواع آرتروز زانو درگیر هستند و این بیماری به عنوان یکی از اصلیترین
دلایل معلولیت در سراسر جهان شناخته شده است. بدتر اینکه با توجه به عدم
وجود درمانی برای این بیماری، رسیدن به راهحل مناسب برای درمان آن نیازمند
شناسایی دقیق و مرحلهبندی این بیماری است.
محققان دانشکده گزشکی دانشگاه بوستون با استفاده از یک رویکرد مبتنی بر هوش مصنوعی و یادگیری عمیق توانستند گامی موثر در جهت تعیین شدت آرتروز زانو بردارند و نام آن را «طول استخوان زیرغضروفی» گذاشتهاند.
دستگاههای
تصویربرداری مخصوص آرتروز زانو که بتوانند عملکردی قابلقبول داشته باشند،
زیاد نیستند. درحالحاضر از ابزارهای تصویربرداری پزشکی مانند تصویربرداری
تشدید مغناطیسی یا اشعه ایکس برای بررسی مفاصل زانو استفاده میشود.
ویجایا
کولاچالاما، دستیار دکترای دانشگاه بوستون، در اینباره میگوید: «مطالعات
ما منجر به شناسایی روش تصویربرداری جدیدی شده که توانایی تبدیل شدن به
نشانگر زیستی آتروز زانو را دارد.»
محققان
برای تعریف روش جدید از هزاران اسکن MRI استفاده کردند تا بتوانند درجه
مسطح شدن غضروف و استخوان و رابطه آن با تنگی فضای رادیوگرافی مفصل، درد
همزمان و ناتوانی و همچنین جابجایی جزئی یا کلی زانو در آینده را به ماشین
آموزش دهند. آنها سپس از تغییرات نسبی در روش طول استخوان زیرغضروفی، نسبت
شانس را برای هریک از این نتایج تخمین زدند و دریافتند که مقادیر طول
استخوان زیرغضروفی در زانوهایی که دچار باریکی فضای مفصل شدهاند و
زانوهایی که این مشکل را ندارند، متفاوت است. آنها همچنین دریافتند که
تغییرات بیشتر طول استخوان زیرغضروفی در ابتدا با درد و ناتوانی بیشتر
همراه است.
طبق ادعای
محققان، این مطالعه پیامدهای بالینی مهمی دارد. کولاچالاما در ادامه
میگوید: «مطالعه ما طول استخوان زیرغضروفی را به عنوان اندازهگیری بالقوه
مفیدی برای مورفولوژی استخوان در مفصل زانو شناسایی کرده و نشان داده که
این موضوع متفاوت از درجه بیماری است. طول استخوان زیرغضروفی همچنین این
پتانسیل را دارد که در آینده درجه آرتروز زانو را هم بسنجد.»
قدم
بعدی برای محققان بررسی این موضوع است که آیا طول استخوان زیرغضروفی
میتواند برای تشخیص بهموقع بیماری مورد استفاده قرار گیرد یا خیر. اگر
این شرایط فراهم شود میتواند تاثیر چشمگیری بر پروسه مدیریت مراقبت از
بیمار داشته باشد.
مباحث
یادگیری عمیق و شبکههای عصبی میتوانند گیجکننده باشند. اما باید توجه
داشته باشید که برای استخدام یادگیری عمیق در مصاحبههای کاری علوم داده،
عمدهی سؤالات از چند مبحث خاص مطرح میشوند. بعد از بررسی صدها نمونه از
این مصاحبهها، به ۱۰ مفهوم از یادگیری عمیق رسیدم که اغلب موردتوجه مصاحبهگران قرار میگیرد.
در این نوشتار، این ۱۰ مفهوم را با هم مرور میکنیم:
توابع فعالسازی
در صورتی که شناختی از شبکه های عصبی و ساختار آنها ندارید پیشنهاد میکنم ابتدا این مقاله را مطالعه کنید تا مشکلی برای استخدام یادگیری عمیق از این بابت نداشته باشید.
بعد
از آشنایی مختصر با نورونها/گرهها، درمییابید تابع فعالسازی مثل کلیدی
است که تعیین میکند یک نورون خاص باید فعال شود یا خیر.
توابع
فعالساز انواع مختلفی دارند، اما از محبوبترین آنها میتوان به تابع
یکسوساز خطی یا ReLU اشاره کرد. این تابع از توابع سیگموئید و تانژانت
هذلولوی شناختهشدهتر است، زیرا گرادیان کاهشی را با سرعت بیشتری اجرا
میکند. با توجه به تصویر بالا، مشاهده میکنید که وقتی x (یا z) خیلی بزرگ
باشد، شیب به شدت کاهش مییابد و در نتیجه سرعت کاهش گرادیان به میزان
چشمگیری آهسته میشود. اما این نکته برای تابع ReLU صدق نمیکند.
تابع هزینه
تابع هزینه یک شبکهی عصبی مانند توابع هزینهای است که در سایر مدلهای یادگیری ماشین
به کار میروند و برای استخدام یادگیری عمیق آشنایی با آنها ضروری است.
تابع هزینه معیاری برای ارزیابی عملکرد مدل، از طریق سنجش شباهت مقادیر
پیشبینیشده با مقادیر واقعی است. تابع هزینه با کیفیت مدل رابطهی عکس
دارد؛ یعنی هر چه مدل بهتر باشد، تابع هزینه پایینتر خواهد بود و بالعکس.
تابع هزینه را میتوان بهینهسازی کرد.وزنها و پارامترهای بهینهی مدل، با حداقل ساختن تابع هزینه قابل دسترسی هستند.
از
توابع هزینهی متداول میتوان به تابع درجه دوم، تابع آنتروپی متقاطع،
تابع هزینه نمایی، فاصله هلینگر و واگرایی کولبک-لیبلر اشاره کرد.
پسانتشار
موردی
که برای استخدام یادگیری عمیق باید بدانید این است که پسانتشار ارتباط
نزدیکی با تابع هزینه دارد. پسانتشار الگوریتمی است که برای محاسبهی
گرادیان تابع هزینه به کار میرود. این الگوریتم با توجه به سرعت و کارآیی
بالایی که در مقایسه با سایر رویکردها دارد، از محبوبیت و کاربرد بالایی
برخوردار شده است.
نام
پسانتشار برگرفته از این واقعیت است که محاسبهی گرادیان از آخرین لایهی
وزنها آغاز شده و به سوی گرادیانهای اولین لایه، یعنی به سمت عقب، حرکت
میکند. بنابراین خطای لایهی k وابسته به لایهی بعدی یعنی k+1 است.
نحوهی کار الگوریتم پسانتشار را میتوان در این گامها خلاصه کرد:
انتشار رو به جلو را برای هر جفت ورودی-خروجی محاسبه میکند؛
انتشار رو به عقب هر جفت را محاسبه میکند؛
گرادیانها را ترکیب میکند؛
وزنها را بر اساس نرخ یادگیری و گرادیان کلی، به روزرسانی میکند.
این مقاله به خوبی مبحث پسانتشار را پوشش داده و برای مبحث استخدام یادگیری عمیق مناسب است.
شبکههای عصبی پیچشی
شبکهی
عصبی پیچشی (CNN) نوعی شبکهی عصبی است که به ویژگیهای مختلف ورودی (که
اغلب یک تصویر و یا بخشی از یک متن میباشد.) مقادیر اهمیت اختصاص داده و
سپس یک خروجی تولید میکند. آنچه باعث مزیت CNNها نسبت به شبکههای عصبی
پیشخور میشود این است که وابستگیهای فضایی (پیکسلی) سراسر تصویر، و در
نتیجه ترکیب تصویر را بهتر درک میکند.
CNNها
در واقع یک عملیات ریاضیاتی به نام کانولوشن اجرا میکنند. طبق تعریف
ویکیپدیا، کانولوشن یک عملیات ریاضیاتی است که روی دو تابع انجام میشود و
خروجی آن، تابع سومی است که نشان میدهد شکل یکی از آن توابع چطور توسط
دیگری تغییر میکند. پس CNN به جای ضربهای ماتریسی معمولی، حداقل در یکی
از لایههای خود، از عملیات کانولوشن استفاده میکند.
شبکههای عصبی بازگشتی
اگر
مشتاق استخدام یادگیری عمیق هستید باید بدانید شبکههای عصبی
بازگشتی (RNN) نوع دیگری از شبکههای عصبی هستند که به خاطر قابلیت پردازش
دادههایی با اندازههای گوناگون، روی دادههای توالی عملکرد بسیار خوبی از
خود نشان میدهند. RNNها علاوه بر ورودیهای فعلی، ورودیهای قبلی را هم
درنظر میگیرند؛ بنابراین یک ورودی خاص میتواند بر اساس ورودیهای قبلی،
خروجیهای متفاوتی تولید کند.
از
نظر فنی، RNNها گروهی از شبکههای عصبی هستند که اتصالات بین گرههایشان،
علاوه بر یک توالی زمانی، یک گراف جهتدار ایجاد میکند و بدین ترتیب آنها
را قادر میسازد از حافظهی داخلی خود برای پردازش توالیهایی با طول
متغیر استفاده کنند.
به بیان خلاصه، RNNها نوعی از شبکههای عصبی هستند که اساساً روی دادههای توالی یا سریهای زمانی به کار میروند.
شبکههای حافظهی کوتاهمدت بلند (LSTM)
شبکههای LSTM نوعی از شبکه های عصبی بازگشتی
هستند که برای جبران یکی از نقاط ضعف RNNها یعنی حافظهی کوتاهمدت، ساخته
شدهاند و برای استخدام یادگیری عمیق باید با آن آشنا باشید.
به
بیان دقیقتر، اگر یک توالی طولانی داشته باشیم (برای مثال رشتهای با
بیشتر از ۵-۱۰ گام)، RNNها اطلاعات مربوط به گامهای اول را فراموش خواهند
کرد. به عنوان مثال، اگر یک پارگراف را به RNN تغذیه کنیم، احتمال نادیده
گرفته شدن اطلاعات ابتدای پارگراف وجود دارد.
LSTMها برای حل این مشکل به وجود آمدند.
در این مطلب میتوانید اطلاعات بیشتری در مورد LSTMها به دست آورید.
تعریف وزن
هدف از تعریف وزن اطمینان حاصل کردن از این است که شبکهی عصبی به یک راهکار بیهوده همگرایی نخواهد داشت.
اگر
مقدار تعریفشده برای همهی وزنها یکی باشد (برای مثال همه ۰ باشند)،
همهی واحدها سیگنالی دقیقاً یکسان دریافت میکنند؛ در نتیجه، لایهها طوری
رفتار میکنند که فقط یک سلول واحد وجود دارد.
بنابراین،
باید به صورت تصادفی مقادیر نزدیک صفر، اما نه خود صفر، را به وزنها
اختصاص دهیم. الگوریتم بهینهسازی تصادفی که برای آموزش مدل به کار میرود
از این قاعده استثناست.
مقایسه گرادیان کاهشی تصادفی با گرادیان کاهشی دستهای
افراد
مایل به استخدام یادگیری عمیق باید بدانند که گرادیان کاهشی دستهای و
گرادیان کاهشی تصادفی دو روش متفاوت برای محاسبهی گرادیان هستند.
گرادیان
کاهشی دستهای، گرادیان را بر اساس همهی دیتاست محاسبه میکند. این روش
در دیتاستهای بزرگ، سرعت پایینی خواهد داشت، اما برای هموارسازی یا واگرا
شدن منیفلد خطا بهتر است.
در
روش گرادیان کاهشی تصادفی، گرادیان در هر بازهی زمانی، بر اساس یک
نمونهی آموزشی واحد محاسبه میشود. به همین خاطر، این روش از نظر محاسباتی
سریعتر و کمهزینهتر است. با این حال، در این روش، بعد از رسیدن به
کمینهی سراسری، جستجو در اطراف همچنان ادامه میباید. نتیجهی این روش
قابلقبول است، اما بهینه نیست.
هایپرپارامترها
هایپرپارامترها
متغیرهایی هستند که ساختار شبکه را تنظیم میکنند و بر نحوهی آموزش آن
نظارت دارند. از جمله هایپرپارامترهای متداول میتوان به این موارد اشاره
کرد:
پارامترهای معماری مدل همچون تعداد لایهها، تعداد واحدهای نهان، و …؛
نرخ یادگیری (آلفا)؛
تعریف وزنهای شبکه؛
تعداد دورهها (دوره به معنی یک چرخهی کامل در دیتاست آموزشی است)
اندازهی بستهداده
نرخ یادگیری
نرخ
یادگیری یکی از هایپرپارامترهای شبکههای عصبی است که بر اساس خطای برآورد
شده در هربار به روزرسانی وزنها، میزان انطباق مدل را تعیین میکند.
اگر
نرخ یادگیری خیلی پایین باشد، سرعت آموزش مدل آهسته خواهد بود؛ زیرا در هر
تکرار، وزنهای مدل به حداقل میزان ممکن به روزرسانی خواهند شد. به همین
دلیل، قبل از رسیدن به کمینه، باید بهروزرسانیهای زیادی انجام شود.
اگر نرخ یادگیری خیلی بالا باشد، توابع زیان
رفتاری واگرا خواهند داشت. زیرا در به روزرسانی وزنها، تغییراتی چشمگیر
رخ میدهد. این رفتار ممکن است آنقدر شدید باشد که تابع هیچگاه همگرا
نشود.
کتابخانه Matplotlib پرکاربردترین ابزار پایتون در حوزه مصورسازی داده ها
است. این کتابخانه در محیطهای مختلف از جمله سرورهای کاربردی، ابزارهای
رابط کاربری گرافیکی، Jupyter notebook، iPython و iPython shell پشتیبانی
میشود.
معماری کتابخانه Matplotlib
کتابخانه
Matplotlib دارای ۳ لایه است که عبارتند از: لایه backend ، لایه artist
و لایه scripting. لایه سمت سرور سه کلاس رابط دارد: ۱. figure canvas که
فضایی که نمودار در آن رسم خواهد شد را تعریف میکند، ۲. renderer که مسئول
رسم نمودار در figure canvas است و ۳. event که با ورودیهای کاربر مثل
کلیکها سروکار دارد. لایهartist برای رسم نمودار روی صفحه از renderer
استفاده میکند. بنابراین، هر چیزی که در نمودار رسمشده توسط کتابخانه
Matplotlib مشاهده میکنید، در حقیقت، مصداقی از یک لایهartist است. یعنی
هر عنوان، برچسب، علامت و حتی خود نمودار یک لایهartist مجزا هستند. لایه
scripting یک رابط سبکتر است که برای استفاده روزانه مناسب میباشد. در
این مقاله، همه مثالها با استفاده از لایه scripting به شما نشان داده
میشوند و همچنین از محیط Jupyter notebook استفاده خواهم کرد.
اگر
هدفتان از خواندن این مقاله یادگیری کار با کتابخانهMatplotlib است،
پیشنهاد میکنم که حتماً خودتان کدها را اجرا کنید تا طرزکار آن را ببینید.
آمادهسازی دادهها
معمولاً
در همه پروژهها پیش از به تصویر کشیدن دادهها یا شروع تحلیل، فرآیند
آمادهسازی دادهها صورت میگیرد. زیرا دادهها هیچوقت در قالب و شکلی که
ما میخواهیم، نیستند. دیتاستی که در این مقاله آموزشی از آن استفاده
خواهیم کرد حاوی اطلاعاتی در خصوص مهاجرت به کانادا است. ابتدا باید
پکیجهای ضروری و دیتاست را وارد محیط کاری خود کنیم.
من ۲۰ سطر اول و ۲ سطر آخر دیتاست را رد میکنم، چون این سطرها حاوی متن هستند، نه دادههایی که ما نیاز داریم. این دیتاست،
بسیار بزرگ است و به همین دلیل، نمیتوانم از صفحه حاوی دادهها عکس بگیرم
و برای شما نمایش دهم. در زیر میتوانید نام ستونهای دیتاست را ملاحظه
فرمایید:
در این مقاله مربوط
به کتابخانه Matplotlib قرار نیست همه این ستونها را استفاده کنیم.
بنابراین، باید ستونهای بلااستفاده را حذف کنیم تا دیتاست کوچکتر و کار
با آن راحتتر شود.
به
نام ستونها دقت کنید، ستون OdName حاوی نام کشورها، AreaName نام قارهای
که کشور مذکور در آن قرار دارد و RegName نیز نام منطقهای که کشور مربوطه
در آن واقع شده، میباشند. اما من میخواهم نام ستونها را تغییر دهم تا
گویاتر و قابلفهم باشند.
به
این ترتیب، نام ستونهای دیتاست به Country به معنی کشور، Continent به
معنی قاره، Region به معنی منطقه و DevName که بیانگر توسعهیافته یا
درحالتوسعه بودن کشور است، تغییر پیدا کردند. ستونهایی که نام آنها
نشاندهنده یک سال خاص است، حاوی شمار مهاجرانی که هستند که در آن سال وارد
کانادا شدهاند. حالا میخواهم یک ستون جدید به نام total اضافه کنم که به
ما بگوید چه تعداد مهاجر بین سال ۱۹۸۰ تا ۲۰۱۳ به کانادا آمدهاند.
df['Total'] = df.sum(axis=۱)
همانطور که مشاهده میکنید، یک ستون جدید به نام Total به انتهای دیتاست افزوده شده است.
حالا باید بررسی کنیم و ببینیم آیا سلول خالی یا سلولی حاوی مقدار null در ستونها وجود دارد؟
df.isnull().sum()
خروجی
این خط از کد تعداد مقادیر در همه ستونها را صفر نشان میدهد. من دوست
دارم همیشه ستون شاخص به جای یک سری عدد بیمعنی، ستونی باشد که مقادیر آن
معنادارند. بنابراین، ستون را به عنوان شاخص تعیین میکنم.
این
دیتاست از همان ابتدا تمیز و مرتب بود، بنابراین، عملیات پاکسازی دادهها
را در همینجا به پایان میرسانیم. البته اگر عملیات دیگری نیاز باشد، در
طی مسیر آن را انجام خواهیم داد.
df = df.set_index('Country')
خروجی
این خط از کد تعداد مقادیر در همه ستونها را صفر نشان میدهد. من دوست
دارم همیشه ستون شاخص به جای یک سری عدد بیمعنی، ستونی باشد که مقادیر آن
معنادارند. بنابراین، ستون را به عنوان شاخص تعیین میکنم.
این
دیتاست از همان ابتدا تمیز و مرتب بود، بنابراین، عملیات پاکسازی دادهها
را در همینجا به پایان میرسانیم. البته اگر عملیات دیگری نیاز باشد، در
طی مسیر آن را انجام خواهیم داد.
df = df.set_index('Country')
تمرینهای رسم نمودار در کتابخانه Matplotlib
در
این مقاله، رسم انواع نمودارها از جمله نمودار خطی، نمودار ناحیهای،
نمودار دایرهای، نمودار پراکنش، نمودار میلهای و هیستوگرام را تمرین
خواهیم کرد.
%matplotlib inline
import matplotlib.pyplot as plt
import matplotlib as mpl
اگر
از همان ابتدا سبک نمودار خود را انتخاب کنید، دیگر لازم نخواهد بود روی
جنبههای هنری آن زمان زیادی بگذارید. در زیر لیست گزینههای موجود را
مشاهده میفرمایید:
plt.style.available
#Output:
mpl.style.use(['ggplot'])
'classic',
'dark_background',
'fast',
'fivethirtyeight',
'ggplot',
'grayscale',
'seaborn-bright',
'seaborn-colorblind',
'seaborn-dark-palette',
'seaborn-dark',
'seaborn-darkgrid',
'seaborn-deep',
'seaborn-muted',
'seaborn-notebook',
'seaborn-paper',
'seaborn-pastel',
'seaborn-poster',
'seaborn-talk',
'seaborn-ticks',
'seaborn-white',
'seaborn-whitegrid',
'seaborn',
'Solarize_Light2',
'tableau-colorblind10',
'_classic_test']
من
در اینجا گزینه ggplot را برای نمودارم انتخاب میکنم. شما میتوانید
گزینههای دیگر را نیز امتحان کرده و سبک موردعلاقه خود را برگزینید.
نمودار خطی
به
نظر من به تصویر کشیدن تمایل کشورهای مختلف به مهاجرت به کانادا جالب
خواهد بود. به این منظور، ابتدا یک لیست از سالهایی که در دیتاست داریم
(یعنی۱۹۸۰ تا ۲۰۱۴) ایجاد میکنم.
years = list(map(int, range(۱۹۸۰, ۲۰۱۴)))
برای
این نمودار کشور سوئیس را انتخاب کردم و میخواهم دادههای مربوط به آن را
روی نمودار نمایش دهم. پس باید دادههای مهاجرت مردم سوئیس به کانادا را
در هر سال تهیه کنم.
df.loc['Switzerland', years]
در
تصویر بالا بخشی از دادههای مربوطه را مشاهده میکنید. حال زمان رسم
نمودار است. کار بسیار آسانی است. تنها کافی است تابع plot را فراخوانی
کنید، دادههایی که اماده کردهاید را به آن بدهید و در آخر نیز عنوان و
برچسبهای محور x و y را تعیین کنید.
df.loc['Switzerland', years].plot()
plt.title('Immigration from Switzerland')
plt.ylabel('Number of immigrants')
plt.xlabel('Years')
plt.show()
حال
اگر بخواهیم روند مهاجرت چند کشور به کانادا را طی این سالها مشاهده و با
هم مقایسه کنیم، باز هم کار سختی نخواهد بود. تنها کافیست در لیست دادهها
به جای یک کشور، نام کشورهای مدنظر را همراه با سال بیاوریم. در اینجا من
میخواهم سه کشور هند، پاکستان و بنگلادش را با هم مقایسه کنم.
فرمت
دادهها در اینجا با مثال قبلی متفاوت است. اگر تابع plot را روی همین
دیتافریم اعمال کنیم، روی محور xها تعداد مهاجران هر کشور و روی محور yها،
سال را خواهیم داشت. پس باید فرمت دیتاست را تغییر دهیم:
ind_pak_ban.T
در
این تصویر تنها بخشی از دیتاست را مشاهده میکنید، اما میتوانید ببینید
که فرمت آن چگونه تغییر کرده است. حال با فراخوانی تابع plot، سال روی محور
xها و شمار مهاجران هر کشور روی محور yها رسم خواهد شد.
در این مثال لازم نبود نام نمودار را ذکر کنیم، زیرا پیشفرض این تابع، نمودار خطی است.
ind_pak_ban.T.plot()
نمودار دایرهای
در
این مثال میخواهم شمار مهاجران هر قاره را روی نمودار دایرهای به تصویر
بکشم. ما دادهها را برای هر کشور داریم، پس اگر کشورها را براساس قارهای
که در آن واقع شدهاند گروهبندی کنیم و تعداد مهاجران هر گروه را به دست
آوریم، در واقع شمار مهاجران هر قاره را خواهیم داشت.
cont = df.groupby('Continent', axis=۰).sum()
بسیار
خب، به این ترتیب دیتاستی داریم که شمار مهاجران هر قاره را به ما نشان
میدهد. این دیتاست بسیار بزرگ است و در این صفحه جای نمیگیرد، اما شما
میتوانید این دیتاست را فراخوانی و چاپ کنید تا ببینید دادهها در آن به
چه صورت هستند. حالا بیایید نمودار آن را رسم کنیم.
cont['Total'].plot(kind='pie', figsize=(۷,۷),
autopct='%۱.۱f%%',
shadow=True)
#plt.title('Immigration By Continenets')
plt.axis('equal')
plt.show()
اگر
به این کد دقت کنید، میبینید که تابع ما دارای پارامتری به نام «kind»
است. غیر از نمودار خطی، باید نوع سایر نمودارها را با این پارامتر تعیین
کنید. همچنین پارامتر جدیدی به نام «figsize» در تابع تعریف کردهام که
ابعاد نمودار را تعیین میکند.
این
نمودار دایرهای واضح و قابلفهم است، اما با اندکی تلاش میتوان آن را
بهتر و زیباتر کرد. به این منظور میخواهم رنگها و زاویه شروع نمودار را
خودم تعیین کنم.
در این مثال ابتدا نمودار جعبهای برای شمار مهاجران چینی رسم میکنیم.
china = df.loc[['China'], years].T
این از دادههای موردنیازمان؛ حالا برویم سراغ رسم نمودار جعبهای:
china.plot(kind='box', figsize=(۸, ۶))
plt.title('Box plot of Chinese Immigratns')
plt.ylabel('Number of Immigrnts')
plt.show()
اگر به دنبال نکات و تکنیکهای بیشتری در خصوص نمودارهای جعبهای میگردید، میتوانید به این لینک مراجعه فرمایید.
امکان
رسم چندین نمودار جعبهای در یک نمودار هم وجود دارد. در اینجا با
استفاده از دیتافریم قبلی یعنی «ind_pak_ban»، نمودار جعبهای هر سه کشور
هند، پاکستان و بنگلادش را روی یک نمودار رسم میکنم.
ind_pak_ban.T.plot(kind='box', figsize=(۸, ۷))
plt.title('Box plots of India, Pakistan and Bangladesh Immigrants')
plt.ylabel('Number of Immigrants')
نمودار پراکنش
رسم
یک نمودار پراکنش بهترین راه برای شناسایی رابطه میان متغیرهاست. نمودار
پراکنش را رسم کنید تا روند مهاجرت به کانادا طی سالهای ۱۹۸۰ تا ۲۰۱۳ را
مشاهده کنید.
برای رسم این
نمودار یک دیتافریم جدید ایجاد میکنم که حاوی تعداد کل مهاجرانی است که در
هر سال به کانادا مهاجرت کردهاند و متغیر years در آن به عنوان شاخص
درنظر گرفته شده است.
ما باید نوع متغیر years را به عدد صحیح یا int تبدیل کنیم. در ادامه قصد دارم اندکی دیتاست را دستکاری کنم تا درک آن آسانتر شود.
totalPerYear.index = map(int, totalPerYear.index)
totalPerYear.reset_index(inplace=True)
totalPerYear.head()
در نمودار پراکنش باید محور xها و yها را مشخص کنیم.
totalPerYear.plot(kind='scatter', x = 'year', y='total', figsize=(۱۰, ۶), color='darkred')
plt.title('Total Immigration from 1980 - 2013')
plt.xlabel('Year')
plt.ylabel('Number of Immigrants')
plt.show()
به نظر میرسد بین دو متغیر سال و تعداد مهاجران یک رابطه خطی وجود دارد و روند مهاجرت از سال ۱۹۸۰ تا ۲۰۱۳ روندی صعودی داشته است.
نمودار ناحیهای
نمودار
ناحیهای در حقیقت سطح زیر منحنی خطی را نمایش میدهد. برای رسم این
نمودار میخوام از دیتافریمی استفاده کنم که حاوی دادههای مربوط به ۴ کشور
هند، چین، پاکستان و فرانسه است.
top = df.loc[['India', 'China', 'Pakistan', 'France'], years]
top = top.T
دیتاست ما آماده است، حالا نوبت رسم نمودار است.
colors = ['black', 'green', 'blue', 'red']
top.plot(kind='area', stacked=False,
figsize=(۲۰, ۱۰), colors=colors)
plt.title('Immigration trend from Europe')
plt.ylabel('Number of Immigrants')
plt.xlabel('Years')
plt.show()
در کتابخانه Matplotlib اگر میخواهید نمودار هر کشور به صورت جداگانه رسم شود، یادتان باشد که مقدار پارامتر «stacked» را حتماً برابر False قرار دهید، در غیر این صورت نمودار شما به شکل زیر خواهد شد:
وقتی مقداری برای stacked تعیین نشود، ناحیه متغیرها به صورت مجزا نمایش داده نمیشود، بلکه روی متغیر قبلی رسم میشود.
هیستوگرام
نمودار هیستوگرام توزیع یک متغیر را نشان میدهد. به مثال زیر توجه کنید:
df[۲۰۰۵].plot(kind='hist', figsize=(۸,۵))
plt.title('Histogram of Immigration from 195 Countries in 2010')
# add a title to the histogram
plt.ylabel('Number of Countries')
# add y-label
plt.xlabel('Number of Immigrants')
# add x-label
plt.show()
روی
این نمودار هیستوگرام ۲۰۰۵ داده را به تصویر کشیدهام. از این نمودار
پیداست که کانادا از اکثر کشورها بین ۰ تا ۵۰۰۰ مهاجر داشته است. و تنها
تعداد محدودی کشور بودهاند که ۲۰۰۰۰ یا ۴۰۰۰۰ هزار مهاجر به کانادا
داشتهاند.
حالا بیایید با استفاده از دیتافریم top که برای نمودار پراکنش تعریف کرده بودیم، توزیع مهاجران هر کشور را نیز رسم کنیم.
top.plot.hist()
plt.title('Histogram of Immigration from Some Populous Countries')
plt.ylabel('Number of Years')
plt.xlabel('Number of Immigrants')
plt.show()
در
نمودار هیستوگرام قبلی دیدیم که کشورهای کمی بودند که ۲۰۰۰۰ یا ۴۰۰۰۰ هزار
مهاجر به کانادا داشتند. بهنظر میرسد که چین و هند در میان این کشورها
قرار دارند. در این نمودار، حاشیه میان «ستونها» واضح نیست. پس بیایید
نمودار بهتری رسم کنیم.
تعیین تعداد ستونها و مشخص کردن حاشیه ستونها در کتابخانه Matplotlib
در
این نمودار ۱۵ ستون رسم خواهم کرد. همچنین، یک پارامتر جدید به نام alpha
به مدل اضافه میکنم که شفافیت رنگها را تعیین میکند. در نمودارهایی مثل
این نمودار که ستونها روی هم قرار میگیرند، با تغییر میزان شفافیت
میتوان شکل همه توزیعها را مشاهده کرد.
من
رنگ ستونها را دقیق مشخص نکردم، به همین دلیل، رنگها در این نمودار با
نمودار قبلی متفاوت است. اما در این نمودار به لطف کاهش شفافیت رنگها،
میتوانید هر توزیع را به وضوح ببینید.
همانطور که در نمودار ناحیهای دیدید، با تعریف مقدار True پارامتر stacked میتوان از روی هم قرار گرفتن نمودارها جلوگیری کرد.
top.plot(kind='hist',
figsize=(۱۲, ۶),
bins=۱۵,
xticks=bin_edges,
color=colors,
stacked=True,
)
plt.title('Histogram of Immigration from Some Populous Countries')
plt.ylabel('Number of Years')
plt.xlabel('Number of Immigrants')
plt.show()
نمودار میلهای
برای رسم نمودار میلهای، از دادهها کشور فرانسه استفاده میکنم و تعداد مهاجران فرانسوی هر سال را روی نمودار میآورم.
france = df.loc['France', years]
france.plot(kind='bar', figsize = (۱۰, ۶))
plt.xlabel('Year')
plt.ylabel('Number of immigrants')
plt.title('Immigrants From France')
plt.show()
میتوانید
اطلاعات بیشتری نیز به نمودار اضافه کنید. در این نمودار از سال ۱۹۹۷ به
بعد و برای یک دهه کامل، شاهد روند صعودی هستیم که ذکر کردن آن خالی از لطف
نخواهد بود. این کار را میتوان به کمک تابع annotate انجام داد.
گاهی
اوقات، اگر میلهها بهصورت افقی قرار بگیرند، نمودار قابلفهمتر خواهد
شد. همچنین، نوشتن اعداد روی میلهها نیز به بهبود نمودار کمک خواهد کرد.
پس بیایید این دو مورد را نیز روی نمودار اعمال کنیم.