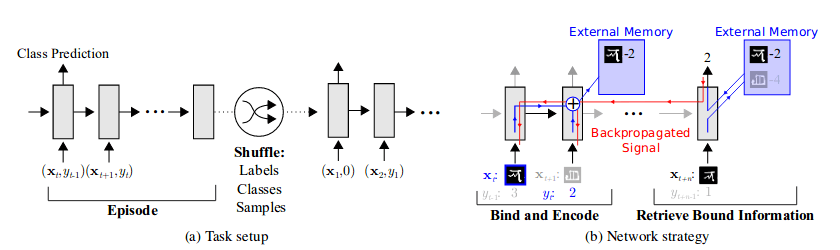
حدود یک سال پیش، شرکت مایکروسافت با انتشار خبری اعلام کرد که خواهان سرمایهگذاری یک میلیاردی در OpenAI است. هدف از همکاری OpenAI با مایکروسافت، توسعه فناوریهای جدید برای پلتفرم ابری «Azure»در هوش مصنوعی عمومی مایکروسافت و گسترش قابلیتهای هوش مصنوعی بزرگمقیاس عنوان شد.
تحقق این هدف به بکارگیری هوش مصنوعی عمومی بستگی دارد. OpenAI نیز به نوبه خود توافق کرد تا بخشی از مالکیت فکریاش را در اختیار مایکروسافت بگذارد. به این ترتیب، مایکروسافت میتواند اقدام به تجاریسازی و فروش آن به شرکایش کرده و مدلهای هوش مصنوعی را در Azure آموزش داده و به اجرا دربیاورد. در همین راستا، OpenAI در تلاش بوده تا سختافزارهای رایانش نسل بعدی را توسعه دهد.در جریان کنفرانس توسعهدهندگان بیلد مایکروسافت در سال ۲۰۲۰، نخستین ثمرۀ همکاریِ میان این دو در قالب یک ابررایانه جدید اعلام شد. بنا به اعلام مایکروسافت، این ابررایانه با همکاری OpenAI در Azure ساخته شده است. شرکت مایکروسافت مدعی شده که این ابررایانه در مقایسه با TOP 500 پنجمین ماشین قدرتمند جهان به شمار میآید؛ گفتنی است که پروژه TOP 500 جزئیات پانصد ابررایانه برتر جهان را بررسی میکند. بر اساس جدیدترین رتبهبندی، ابررایانه «OpenAI» یک رتبه پایینتر از Tianhe-2A (متعلق به مرکز ملی ابررایانه چین) و یک رتبه بالاتر از Frontera (متعلق به مرکز رایانه پیشرفته تگزاس) قرار دارد. این رتبهبندی نشان میدهد که ابررایانه «OpenAI» قادر است بین ۳۸.۷ تا ۱۰۰.۷ کوادریلیون عملیات در هر ثانیه انجام دهد.
«OpenAI» از مدتها پیش اعلام کرده قدرت رایانش خارقالعادهای برای تحقق اهداف هوش مصنوعی عمومی نیاز است. این پیشرفت به هوش مصنوعی نیز در یادگیری همه فعالیتهای انسان کمک شایانی خواهد کرد. برخی افراد از قبیل «یوشوآ بنجیو» موسس Mila و «یان لِکان» دانشمند هوش مصنوعی بر این باورند که هوش مصنوعی عمومی نمیتواند وجود داشته باشد؛ اما بنیانگذاران و حامیان «OpenAI» که از جمله سرشناسترینِ آنها میتوان به گرِگ بروکمن، ایلیا ساتسکور، ایلان ماسک، راید هافمن، رئیس سابق Y Combinator به نام سَم آلتمن اشاره کرد، معتقد هستند که رایانههای قدرتمند میتوانند در کنار یادگیری تقویتی و سایر روشها به پیشرفتهای کمنظیری در حوزه هوش مصنوعی دست یابند.
مزایای مدلهای بزرگ
ماشین «OpenAI» حاوی بیش از ۲۸۵.۰۰۰ پردازنده مرکزی، ۱۰.۰۰۰ کارت گرافیکی و قابلیت اتصال ۴۰۰ گیگابیت بر ثانیه اتصال میباشد. این ماشین برای آموزشِ مدلهای بزرگ هوش مصنوعی طراحی شده است؛ مدلهایی که با بررسی میلیاردها صفحه متن از کتابها، کتابچههای راهنما، دروس تاریخ، دستورالعملهای منابع انسانی و سایر منابعی که در دسترس عموم قرار دارند، اقدام به یادگیری میکند. از جمله این منابع میتوان به مدل پردازش زبان طبیعیNVIDIA اشاره کرد که ۸.۳ میلیارد پارامتر را در دل خود جای داده است؛ یا حتی متغیرهای قابل تنظیمی که درون مدل تعبیه شدهاند. مقادیرِ این متغیرها در انجام پیشبینی مورد استفاده قرار میگیرند. جزئیات منابع دیگر به صورت زیر خلاصه شده است:
- Turing NLG شرکت مایکروسافت (دارای ۱۷ میلیارد پارامتر) که پیشرفتهترین نتایج را در چند شاخص معیار زبانی به دست میآورد؛
- چارچوب ربات گفتگوی Blender متعلق به فیسبوک (با ۹.۴ میلیارد پارامتر)
- و مدل GPT-2 متعلق به «OpenAI» (با بیش از ۱.۵ میلیارد پارامتر) که قادر است متونی در سطح انسان ایجاد کند.
سَم آلتمن، مدیر عامل «OpenAI» اظهار داشت: «هر چه اطلاعات بیشتری در خصوص نیازها و محدودیتهای مختلف اجزای سازنده ابررایانهها به دست میآوریم، این پرسش برجستهتر میشود: سیستم رویایی مد نظرمان چه شکل و شمایل و چه ویژگیهایی خواهد داشت؟ مایکروسافت توانست جامه عمل به این هدف بپوشاند. اکنون شاهد این هستیم که سیستمهای بزرگمقیاس جزء بسیار مهمی در آموزشِ مدلهای قدرتمند هستند.»
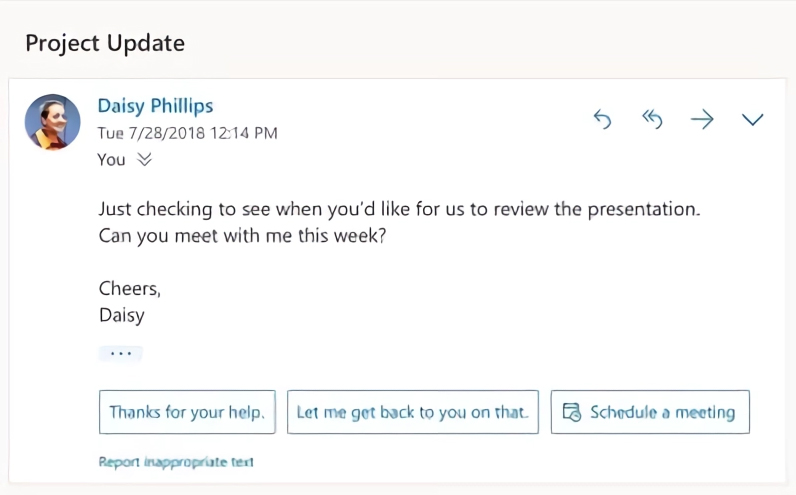
ابزار پاسخگویی هوشمند Outlook از مدلهای یادگیری عمیقی استفاده میکند که در یادگیری ماشین Azure آموزش دیدهاند.
یافتهها حاکی از آن است که این مدلهای بزرگ عملکرد بسیار خوبی از خود بر جای میگذارند زیرا قادر به درک نکات ظریف زبان، دستور زبان، دانش، مفاهیم و بافت هستند. افزون بر این، سیستمهای مذکور میتوانند گفتار را خلاصه کنند، اسناد حقوقی پیچیده را تجزیه و تحلیل نمایند و از GitHub کدنویسی را آغاز کنند. مایکروسافت از مدلهای تورینگِ خود برای تقویت درک زبان در Bing، نرمافزار آفیس، Dynamics و سایر محصولات بهرهوریاش استفاده کرده است. مدلها توانستند در Bing نقش تقویتی مهمی در کپشنسازی و پاسخگویی به پرسشها ایفا کنند. این مدلها در نرمافزار آفیس هم نقش قابل توجهی در توسعۀ هر چه بیشتر ابزارهای Smart Lookup (جستجوی هوشمند) و Key Insights داشتند. Outlook از این مدلها برای پاسخهای پیشنهادی استفاده میکند. این مدلها در Dynamics 365 Sales Insights نیز به کمک فروشندگان شتافتهاند تا تمهیدات مناسبی را با توجه به تعاملات پیشین با مشتریان در نظر بگیرند.
از دیدگاه فنی، مدلهای بزرگ عملکرد بهتری نسبت به مدلهای پیشین خود دارند و از قابلیت خود نظارتی بهره میبرند؛ یعنی قادرند با بررسی روابط میان بخشهای مختلف داده، برچسب ایجاد کنند. به باور محققان، این کار ما را یک گام به تحقق هوش مصنوعی در سطح انسان نزدیکتر میکند. این اقدام بر خلاف الگوریتمهای یادگیری با نظارت است؛ تنظیم این الگوریتمها در اموری که به صنایع، شرکتها و موضوعات خاصی اختصاص دارد، کار را دشوارتر میکند. «کِوین اسکات» مسئول فنی شرکت مایکروسافت بیان کرد: «نکته هیجانانگیزِ مدلهای یاد شده این است که کاربردهای گوناگونی در بخشهای مختلف دارند. این مدلها قادرند صدها فعالیت مهم در حوزه پردازش زبان طبیعی و بینایی رایانه انجام دهند. در صورتی که این قلمروهای مختلف با یکدیگر ادغام شوند، شاهد کاربردهای جدیدی خواهیم بود که پیشتر تصور نمیشد.»
بکارگیری هوش مصنوعی در مقیاس بزرگ
مدلهایی که در خانواده تورینگ جای میگیرند، فاصله زیادی با هوش مصنوعی عمومی دارند؛ مایکروسافت اعلام کرده که در حال استفاده از یک ابررایانه برای بررسی آن دسته از مدلهای بزرگی است که قادرند به صورت تعمیم یافته از متون، تصاویر و دادههای ویدئویی یاد بگیرند. OpenAI نیز همین رویه را در پیش گرفته است. همانطور که مجله MIT Technology Review در ابتدای سال جاری اعلام کرد، یکی از تیمهای فعال در OpenAI به نام Foresight در حال انجام آزمایشهایی برای بررسی ارتقای قابلیتهای هوش مصنوعی است. تیم Foresight با حجم عظیمی از داده اقدام به آموزش الگوریتمها میکند. بر اساس همین منبع خبری، OpenAI در حال توسعه سیستمی با استفاده از منابع محاسباتی عظیم است که از تصاویر، متون و سایر دادههای برای کار آموزش کمک میگیرد. مدیران ارشد شرکت بر این باورند که این مسیر سرانجام میتواند به هوش مصنوعی عمومی ختم شود. بروکمن و آلتمن اعتقاد دارند که هوش مصنوعی عمومی قادر به ارائه عملکردی درخشان در بسیاری از حوزهها خواهد بود. این فناوری خواهد توانست آن دسته از پیوندهای پیچیدهای را مورد شناسایی قرار دهد که کارشناسان انسان در بررسی آنها عاجز ماندهاند. افزون بر این، محققان اظهار داشتند که اگر هوش مصنوعی عمومی با همکاری نزدیک محققان رشتههای مرتبطی نظیر علوم اجتماعی به کار برده شود، زمینه برای رفع چالشهای بزرگ در بهداشت و درمان، تغییرات آب و هوا و آموزش و پرورش فراهم خواهد آمد.
این موضوع کماکان در هالهای از ابهام قرار دارد که آیا این ابررایانه جدید توان کافی برای رسیدن به سطح هوش مصنوعی عمومی را دارد یا خیر. بروکمن سال گذشته در مصاحبه با روزنامه «Financial Times» خاطرنشان کرد: «انتظار داریم کل سرمایه یک میلیاردیِ مایکروسافت را تا سال ۲۰۲۵ برای ساخت سیستمی هزینه کنیم که قابلیت اجرای یک مدل هوش مصنوعی به اندازه مغز انسان را داشته باشد.» در سال ۲۰۱۸، محققان OpenAI با انتشار مطالب تحلیلی اعلام کردند که میزان محاسباتِ بکار رفته در بزرگترین موارد آموزش هوش مصنوعی بیش از ۳۰۰.۰۰۰ برابر افزایش یافته است؛ یعنی هر ۳.۵ ماه دو برابر گردیده است. پس میبینیم که سطح عملکرد فراتر از پیشبینی قانون مورمیباشد. چندی پیش، IBM جزئیات مربوط به رایانه عصبیرا منتشر کرد؛ این رایانه از صدها تراشه برای آموزش هوش مصنوعی استفاده میکند. NVIDIA نیز به نوبه خود خبر از انتظار سرور ۵ پِتافلاپی بر پایه کارت گرافیکی A100 Tensor Core خود تحت عنوان A100 داد.
شواهد و قرائن حاکی از آن است که بهبود کارآیی شاید توان جبران نیازهای فزایندۀ محاسبات را داشته باشد. بر اساس یکی از نظرسنجیهای اخیر OpenAI، میزان محاسبات لازم برای آموزش مدلهای هوش مصنوعی از سال ۲۰۱۲ هر ۱۶ ماه یک بار تا دو برابر کاهش یافته است. اما این موضوع کماکان جای بحث و بررسی دارد که محاسبه تا چه اندازه در مقایسه با روشهای الگوریتمی جدید موجب ارتقای سطح عملکرد میشود. البته نباید این موضوع را فراموش کرد که OpenAI با منابع اندکی که در اختیار دارد، به بازده هوش مصنوعی بالایی در بازیها و حوزهای تحت عنوان media synthesis دست یافته است. در پلتفرم ابری گوگل، سیستم OpenAI Five توانست بازیکنان حرفهای Dota 2 را با کارت گرافیکی ۲۵۶ Nvidia Tesla P100 و ۱۲۸.۰۰۰ هسته پردازنده شکست دهد؛ کاری که عملاً به ۱۸۰ سال بازی نیاز داشت. شرکت گوگل به تازگی سیستمی را با ۶۴ کارت گرافیکی Nvidia V100 و ۳۲ هسته پردازنده آموزش داد تا مکعب روبیک را با دست رباتیک حل کند. البته باید به این نکته اشاره کرد که میزان موفقیت نسبتاً پایینی داشت. افزون بر این، مدل Jukebox متعلق به OpenAI اقدام به شبیهسازی با ۸۹۶ کارت گرافیکی V100 نمود تا در هر سبکی تولید موسیقی کند.
فرصتهای جدید در بازار
در حال حاضر مشخص نیست که این ابررایانه گامی کوچک یا جهشی بزرگ در هوش مصنوعی عمومی است، اما ابزارهای نرمافزاریِ استفاده شده در طراحی آن میتواند فرصتهای بازار جدیدی را برای مایکروسافت فراهم کند. مایکروسافت به واسطه طرح جدیدش در هوش مصنوعی منابع را در دسترس قرار میدهد تا مدلهای بزرگی را در شبکههای هوش مصنوعی Azure آموزش دهد. در همین راستا، دادههای آموزشی به پشتههایی تقسیم میشوند از آنها برای آموزش چندین مدل در خوشهها استفاده میشود. از جمله این منابع میتوان به نسخه جدید DeepSpeed (یک کتابخانه هوش مصنوعی برای چارچوب یادگیری ماشین PyTorch فیسبوک) اشاره کرد که مدلها را با زیرساخت یکسان تا ۱۰ برابر سریعتر آموزش میدهد. آموزش توزیع شدهدر ONYX در صورتی که با DeepSpeed استفاده شود، این قابلیت را در اختیار مدلها قرار میدهد تا سطح عملکرد تا ۱۷ برابر ارتقاء پیدا کند. «کِوین اسکات» مسئول فنی شرکت مایکروسافت در پایان خاطرنشان کرد: «ما با توسعه زیرساختهای پیشرفته برای آموزش مدلهای بزرگ هوش مصنوعی قصد داریم Azure را ارتقاء دهیم. ساخت رایانههای بهتر، سیستمهای توزیع شدۀ بهتر، شبکههای بهتر و دیتاسنترهای بهتر در دستور کار ما قرار دارد. این اقدامات به ارتقای سطح عملکرد و انعطافپذیریِ ابر Azure کمک کرده و منجر به صرفهجویی در هزینهها خواهد شد.»
منبع: hooshio.com