همیشه همه دادهها کامل و خالی از عیب و نقص نیستند. اگر دیتاست کاملاً متوازنی در اختیار داشته باشید، آدم بسیار خوششانسی هستید در غیر این صورت مدیریت دیتاست های نامتوازن اهمیت بسیاری پیدا میکند. اکثر مواقع، دادهها تا حدی نامتوازن هستند. این مورد زمانی اتفاق میافتد که هر کدام از دستهها تعداد نمونههای متفاوتی داشته باشند.
چرا ما بیشتر تمایل داریم تا دادههای متوازن داشته باشیم؟
پیش از آنکه زمان زیادی برای انجام پروژههای طولانی یادگیری عمیق اختصاص دهید، باید بدانید که هدف از انجام این کار چیست. کسب این دانش باید آنقدر با اهمیت باشد و بیارزد که ارزش وقت گذاشتن را داشته باشد. روشهای متوازنکردن دستههای دیتاست تنها زمانی ضروری هستند که دستههای اقلیت را مورد توجه قرار دهیم. برای نمونه، فرض کنید میخواهیم بدانیم که آیا خرید مسکن با توجه به شرایط فعلی بازار، خصوصیات مسکن و توان مالیمان منطقی است یا خیر. اگر مدل، عدم خرید خانه را به ما توصیه کند، فرق چندانی نخواهد کرد. در این مورد، اگر در خرید مسکن موفق شویم، گام مهمی برداشتهایم چرا که سرمایهگذاری عظیمی به شمار میآید. اگر در خرید مسکن دلخواهمان موفق نشویم، این فرصت را داریم که دنبال موارد دیگر باشیم. در صورتی که به اشتباه روی چنین دارایی بزرگی سرمایهگذاری کنیم، یقیناً باید منتظر پیامدهای کارمان بمانیم.
در این مثال، نیاز داریم که دسته “خرید” که در اقلیت هستند بسیار بسیار دقیق تعیین شده باشند، اما برای دسته «عدم خرید» این مورد اهمیت چندانی ندارد (چون به اندازه کافی داده در این دسته وجود دارد). از آنجا که «خرید» در دادههای ما نادر است، مدلمان در یادگیری دستۀ «عدم خرید» سوگیری خواهد داشت زیرا بیشترین داده را دارد و احتمال میرود عملکرد ضعیفی در دسته «خرید» بر جای بگذارد. به همین منظور، لازم است دادههای خود را متوازن کنیم. اگر دستههای اقلیت را مورد بیتوجهی قرار دهیم، چه اتفاقی رخ میدهد؟ برای مثال، فرض کنید در حال دستهبندی تصاویر هستیم و توزیع دسته به شکل زیر در آمده است:
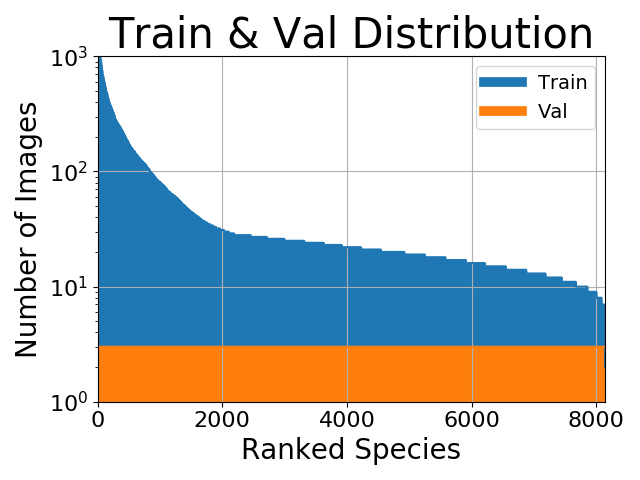
دیتاست های نامتوازن
در نگاه اول، به نظر میرسد که متوازنکردن دادهها میتواند نقش سودمندی داشته باشد. اما شاید علاقه چندانی به آن دستههای اقلیت نداشته باشیم. یا شاید هدف اصلیمان این است که بالاترین درصد دقت را رقم بزنیم. در این صورت، متوازن کردن دادهها منطقی نیست زیرا دستههایی که نمونههای آموزشی بیشتری داشته باشند، میزان دقت را بالا خواهند برد. در ثانی، توابع آنتروپی متقاطع در شرایطی بهترین عملکردشان را دارند که بالاترین درصد دقت را به دست آورند؛ حتی زمانی که دیتاست های نامتوازن باشد. روی هم رفته، دستههای اقلیتمان نقش قابل توجهی در تحقق هدف اصلیمان ندارد؛ بنابراین، متوازن کردن ضرورت چندانی ندارد. با توجه به همه مطالبی که تا به اینجا ذکر شد، اگر با موردی مواجه شویم که نیاز باشد دادههایمان را متوازن کنیم، میتوانیم از دو روش برای تحقق هدفمان استفاده کنیم.
روش «متوازن کردن وزن »
روش «متوازن کردن وزن» با تغییر وزنهای هر نمونه آموزشی سعی در متوازن کردنِ دادهها دارد. در حالت عادی، هر نمونه و دسته در تابع زیان وزن یکسانی خواهد داشت. اما اگر برخی دستهها یا نمونههای آموزشی اهمیت بیشتری داشته باشند، وزن بیشتری خواهند داشت. بگذارید یک بار دیگر به مثال فوق در رابطه با خرید مسکن اشاره کنیم. به دلیل اینکه دقتِ دستۀ «خرید» برایمان اهمیت دارد، انتظار میرود نمونههای آموزشیِ آن دسته تاثیر بسزایی بر تابع زیان داشته باشند.
با ضرب زیان هر نمونه به ضریبی معین (بسته به دستهها)، میتوان به دستهها وزن داد. میتوان در Keras اقدام به چنین کاری کرد:
۱ ۲ ۳ ۴ | import keras class_weight = {"buy": ۰.۷۵, "don't buy": ۰.۲۵} model.fit(X_train, https://hooshio.com/%da%۸۶%da%af%d9%۸۸%d9%۸۶%d9%۸۷-%d8%af%db%۸c%d8%aa%d8%a7%d8%b3%d8%aa-%d9%۸۷%d8%a7%db%۸c-%d9%۸۶%d8%a7%d9%۸۵%d8%aa%d9%۸۸%d8%a7%d8%b2%d9%۸۶-%d8%b1%d8%a7-%d8%af%d8%b1-%db%۸c%d8%a7%d8%af%da%af%db%۸c%d8%b1/Y_train, epochs=۱۰, batch_size=۳۲, class_weight=class_weight) |
در کد بالا در متغیری که تحت عنوان class_weight تعریف کردیم ، دستۀ «خرید» باید ۷۵ درصد از وزنِ تابع زیان را داشته باشد چرا که اهمیت بیشتری دارد. دستۀ «عدم خرید» نیز باید ۲۵ درصد باقیمانده را به خود اختصاص دهد. البته امکان دستکاری و تغییر این مقادیر برای ایجاد مناسبترین شرایط وجود دارد. اگر یکی از دستههایمان نمونههای بیشتری از دیگری داشته باشد، میتوانیم از این روش متوازنسازی استفاده کنیم. به جای اینکه زمان و منابع خود را به جمعآوری بیشتر دستههای اقلیت اختصاص دهیم، میتوانیم شرایطی را رقم بزنیم که طی آن، روش متوازنسازی وزن همه دستهها را وادار کند به میزان یکسان در تابع زیان نقش داشته باشند.
یکی دیگر از روشها برای متوازن کردن وزن نمونههای آموزشی، «زیان کانونی» نام دارد. بیایید جزئیات کار را با هم بررسی کنیم: ما در دیتاستمان چند نمونه آموزشی داریم که دستهبندی راحتتری در مقایسه با بقیه دارند. در طی فرایند آموزش، این نمونهها با ۹۹ درصد دقت دستهبندی خواهند شد، اما شاید نمونههای دیگر عملکرد بسیار ضعیفی داشته باشند. مشکل این است که آن دسته از نمونههای آموزشی که به راحتی دستهبندی شدهاند، کماکان در تابع زیان به ایفای نقش میپردازند. اگر دادههای چالشبرانگیز بسیاری وجود دارد که در صورت دستهبندی درست میتوانند دقت کار را تا حد زیادی بالا ببرند، چرا باید وزن برابری به آنها بدهیم؟
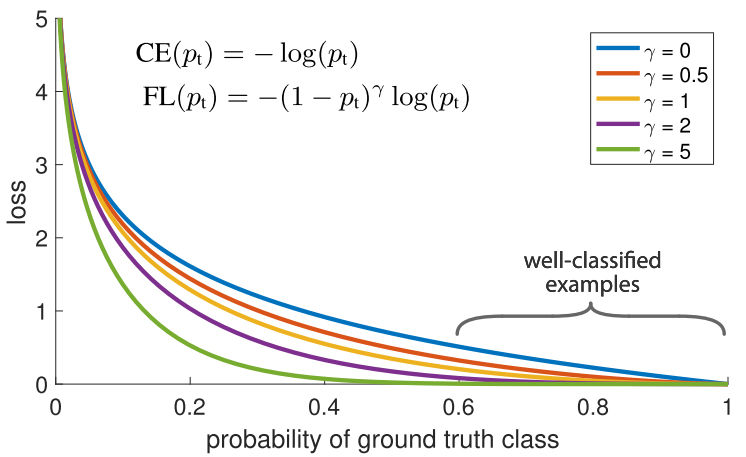
«زیان کانونی» دقیقاً برای حل چنین مسئلهای در نظر گرفته شده است. زیان کانونی به جای اینکه وزن برابری به همه نمونههای آموزشی دهد، وزن نمونههای دستهبندی شده با دقت بالا (داده هایی که دسته بندی شان به راحتی برای شبکه امکان پذیر است) را کاهش میدهد. پس دادههایی که دستهبندی آنها به سختی انجام میشود، مورد تاکید قرار میگیرند. در عمل، وقتی با عدم توازن دادهها روبرو هستیم، دسته اکثریتمان به سرعت دستهبندی میشود زیرا دادههای زیادی برای آن داریم. بنابراین، برای اینکه مطمئن شویم دقت بالایی در دسته اقلیت حاصل میآید، میتوانیم از تابع زیان استفاده کنیم تا وزن بیشتری به نمونه دستههای اقلیت داده شود. تابع زیان میتواند به راحتی در Keras به اجرا درآید.
۱ ۲ ۳ ۴ ۵ ۶ ۷ ۸ ۹ ۱۰ ۱۱ ۱۲ | import keras from keras import backend as K import tensorflow as tf # Define our custom loss function def focal_loss(y_true, y_pred): gamma = ۲.۰, alpha = ۰.۲۵https://hooshio.com/%da%۸۶%da%af%d9%۸۸%d9%۸۶%d9%۸۷-%d8%af%db%۸c%d8%aa%d8%a7%d8%b3%d8%aa-%d9%۸۷%d8%a7%db%۸c-%d9%۸۶%d8%a7%d9%۸۵%d8%aa%d9%۸۸%d8%a7%d8%b2%d9%۸۶-%d8%b1%d8%a7-%d8%af%d8%b1-%db%۸c%d8%a7%d8%af%da%af%db%۸c%d8%b1/ pt_1 = tf.where(tf.equal(y_true, ۱), y_pred, tf.ones_like(y_pred)) pt_0 = tf.where(tf.equal(y_true, ۰), y_pred, tf.zeros_like(y_pred)) return -K.sum(alpha * K.pow(۱. - pt_1, gamma) * K.log(pt_1))-K.sum((۱-alpha) * K.pow( pt_0, gamma) * K.log(۱. - pt_0)) # Compile our model adam = Adam(lr=۰.۰۰۰۱) model.compile(loss=[focal_loss], metrics=["accuracy"], optimizer=adam) |
روشهای نمونهگیری OVER-SAMPLING و UNDER-SAMPLING
انتخاب وزن دسته مناسب از جمله کارهای پیچیده است. فرایند «فراوانی معکوس» همیشه جوابگو نیست. زیان کانونی میتواند مفید واقع شود، اما حتی این راهکار نیز باعث خواهد شد همه نمونههایی که به خوبی دستهبندی شدهاند، با کاهش وزن روبرو شوند. از این رو، یکی دیگر از روشهای برقراری توازن در دادهها، انجام مستقیمِ آن از طریق نمونهگیری است. به تصویر زیر توجه داشته باشید.
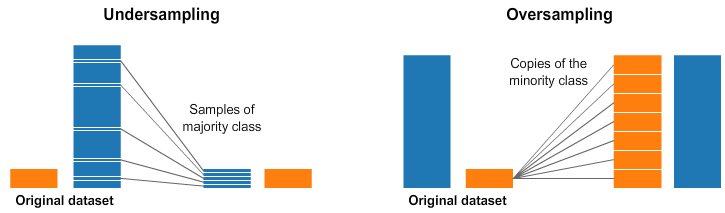
Under and and Over Sampling
در سمت چپ و راست تصویر فوق، دسته آبی نمونههای بیشتری نسبت به دسته نارنجی دارد. در این مورد، دو گزینه پیشپردازش وجود دارد که میتواند به آموزش مدلهای یادگیری ماشین کمک کند. روش Under-sampling بدین معناست که تنها بخشی از دادهها را از دسته اکثریت انتخاب میکنیم. این گزینش باید برای حفظ توزیع احتمال دسته انجام شود. چقدر راحت! نمونههای کمتر باعث میشود دیتاست متوازن گردد. روش Oversampling هم به این معناست که نسخههایی از دسته اقلیت ایجاد خواهد شد. هدف از این کار، ایجاد تساویِ تعداد نمونه دستههای اقلیت با اکثریت است. ما موفق شدیم دیتاست های نامتوازن را بدون کسب دادههای بیشتر متوازن کنیم!
منبع: hooshio.com
