اینکه شما با انواع دیتاست یا همان مجموعهداده ها آشنا شوید بسیار مهم است. پایه علمی قوی در مسیر تبدیل شدن به یک دانشمند داده یا مهندس یادگیری ماشینی بسیار مهم است و در صورتی که مفاهیم داده و انواع دیتاست و مجموعه داده را بهخوبی بدانید هیچچیز نمیتواند راه شما را سد کند.
همه انواع دیتاست ها ۳ مشخصه کلی دارند که عبارتند از: ابعاد، پراکندگیو وضوح. ابتدا باید بدانیم هر یک از این خصوصیات چه معنا و مفهومی دارند.
منظور از ابعاد دیتاست چیست؟
تعداد ابعاد یک دیتاست درواقع، تعداد صفات هر یک از اشیای آن دیتاست است.
اگر یک دیتاست صفات زیادی داشته باشد(که به آن دیتاست ابعاد بالا گفته میشود)، تجزیه و تحلیل آن سخت خواهد بود. به این مشکل نفرین ابعادگفته میشود.
برای اینکه بدانیم نفرین ابعاد دقیقاً چیست و چه مفهومی دارد، ابتدا باید دو مشخصه دیگر دادهها را بشناسیم.
منظور از پراکندگی در یک دیتاست چیست؟
در برخی از دیتاستها، بهویژه دیتاستهایی که ویژگیهای نامتقارن دارند، مقدار اغلب صفات یک شیء صفر است و در اکثر موارد، تنها کمتر از ۱% از آنها مقداری غیر صفر دارند. اینگونه دادهها، دادههای پراکنده نامیده میشوند. همچنین میتوان گفت که این دیتاست دارای پراکندگی است.
منظور از وضوح دیتاست چیست؟
شناسایی الگوهای موجود در دادهها به میزان وضوح آنها بستگی دارد. اگر وضوح دادهها بیش از حد زیاد باشد، ممکن است الگوها قابل مشاهده نباشند و یا در میان نویزها گم شوند. از طرف دیگر، اگر وضوح داده خیلی کم باشد، ممکن است الگو کاملاً از بین برود. برای مثال، تغییرات فشار اتمسفر در مقیاس ساعتی، حرکت طوفانها و سایر وقایع آبوهوایی را نشان میدهد. اما این قبیل پدیدهها در مقیاس ماهیانه قابل تشخیص نیستند.
حال به موضوع نفرین ابعاد بازمیگردیم. نفرین ابعاد بیانگر این است که با افزایش تعداد ابعاد(تعداد صفات برای انواع دیتاست ) دادهها، اجرای بسیاری از روشهای تجزیه و تحلیل بر روی آنها سخت خواهد شد. بهخصوص اینکه با افزایش تعداد ابعاد، پراکندگی دادهها نیز در آن محیط بیشتر و بیشتر میشود. مواجهه با این مسئله در زمان ردهبندی باعث میشود که داده کافی برای طراحی مدلی که همه اشیاء ممکن را بهدرستی و با اطمینان کافی در یک کلاس خاص قرار دهد، در دسترس نباشد و در زمان خوشهبندی نیز معناداری مفاهیم چگالی و فاصله میان نقاط، که برای خوشهبندی حیاتی هستند، را کاهش میدهد.
سرانجام، به موضوع انواع دیتاست میرسیم. در این قسمت دیتاستها را در سه گروه مختلف دستهبندی میکنیم که عبارتند از: دادههای ثبتی، دادههای نموداری و دادههای ترتیبی. درادامه به توضیح و بررسی انواع دیتاست ها میپردازیم.
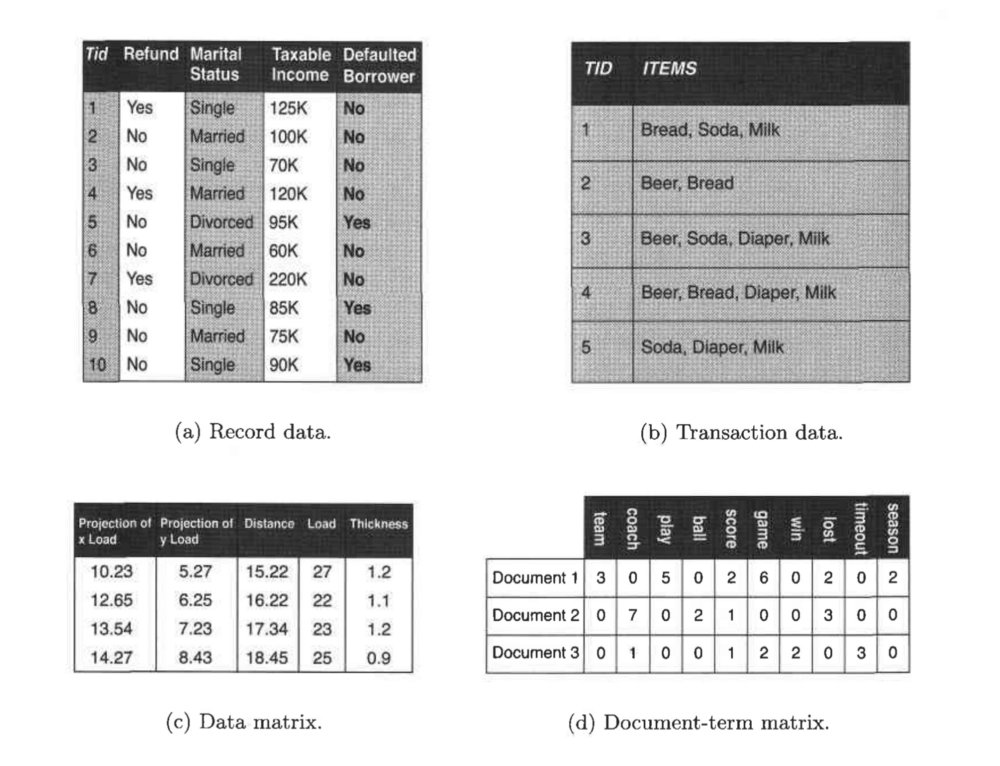
دادههای ثبتی
در زمان دادهکاوی اغلب فرض میشود که دادهها مجموعهای از رکوردها هستند (شیء داده).
در سادهترین گونه دادههای ثبتی هیچ رابطه روشنی میان رکوردها یا فیلد دادهها وجود ندارد و همه رکوردها (شیءها) مجموعه صفات یکسانی دارند. دادههای ثبتی معمولاً در فایلهای مسطح یا پایگاههای دادههای رابطهای ذخیره میشوند.
دادههای ثبتی انواع مختلفی دارند که هر یک از آنها ویژگیهای ذاتی مخصوص به خود را دارد.
دادههای تراکنشی یا سبد بازار: در این نوع از دادههای رکوردی، هر رکورد حاوی مجموعهای از آیتمهاست. برای مثال، خرید از یک سوپرمارکت یا خواربار فروشی را درنظر بگیرید. در این حالت رکورد مربوط به هر یک از مشتریان حاوی مجموعهای از اقلام خریداریشده در یک مراجعه مشخص است. این نوع از دادهها، دادههای سبد بازار نام گرفتهاند. داده تراکنشی نیز دستههای حاوی مجموعه اقلام هستند، اما این دستهها را میتوان مجموعهای از رکوردها درنظر گرفت که فیلدهای آن دارای صفات نامتقارن هستند. این صفات اغلب دودویی هستند و به ما میگویند که آیا یک قلم جنس مشخص خریداری شده است یا خیر.
ماتریس دادهها: اگر همه شیء دادههای موجود در یک دسته از دادهها دارای یک مجموعه صفات عددی ثابت و یکسان باشند، در یک فضای چندبعدی میتوان این شیء دادهها را به عنوان نقاط (بردار) در نظر گرفت. هر بعد در این فضای چندبعدی، نمایانگر یک صفت متمایز برای توصیف شیء است. مجموعه این نوع از شیء دادهها را میتوان یک ماتریس n×m درنظر گرفت که هر ستون مربوط به یک صفت و هر سطر مربوط به یک شیء است. با استفاده از اعمال ماتریسی استاندارد میتوان باعث تغییرشکل دادهها شد و آنها را دستکاری کرد. به همین دلیل، دادههای ماتریسی اغلب شکل استاندارد دادههای آماری درنظر گرفته میشوند.
ماتریس دادههای پراکنده: ماتریس دادههای پراکنده (که گاه ماتریس دادههای اسنادی نیز نامیده میشود) نوعی از خاصی از ماتریس دادههاست که عناصر آن از یک نوع و نامتقارن هستند و در این میان، تنها عناصر غیر صفر اهمیت دارند.
دادههای نموداری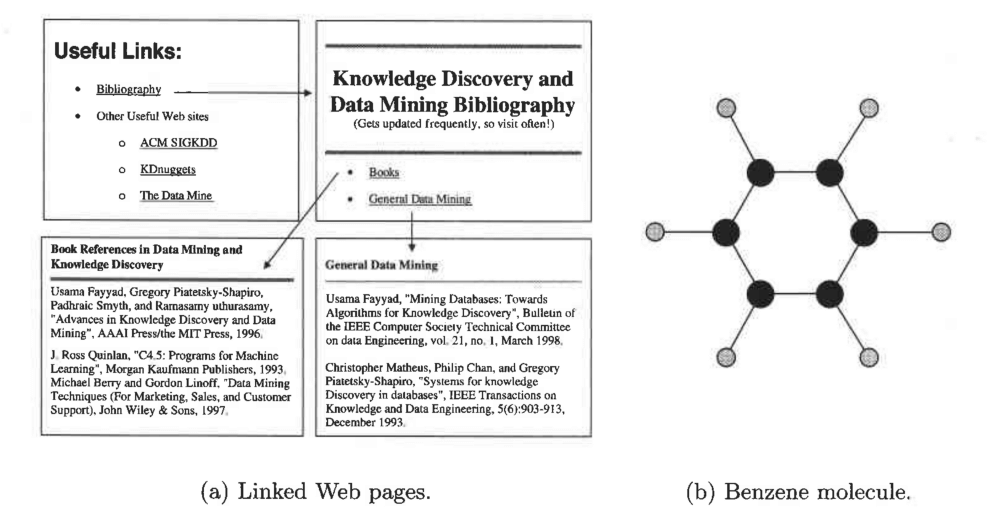
این دادهها را میتوان به چند دسته کوچکتر تقسیم کرد:
دادههایی که بین اشیای آنها ارتباط وجود دارد: شیء دادهها روی نمودار به شکل نقطه رسم میشوند و روابط میان اشیاء نیز به واسطه اتصالاتی که میان اشیاء رسم شده، نمایش داده خواهند شد و ویژگیهایی از قبیل جهت و وزن را برای اشیاء تعریف میکنند. برای مثال صفحات وبی را درنظر بگیرید که علاوهبر متن حاوی لینکهایی به سایر صفحات هستند. موتورهای جستوجوی وب برای آنکه بتوانند مطالبی که افراد در آنها جستوجو میکنند را پردازش کنند، باید این صفحات وب را جمعآوری و پردازش کرده و محتویات درون آنها را استخراج کنند.
دادههایی که اشیاء آنها نمودار هستند: وقتی اشیاء ساختاریافته باشند، یعنی هر شیء تعدادی شیء دیگر به عنوان زیرمجموعه داشته باشد که بین آنها رابطه وجود دارد، این اشیاء اغلب در قالب نمودار به نمایش درمیآیند. برای مثال، ساختار ترکیبات شیمیایی را میتوان در نموداری نشان داد که هر نقطه آن نمایانگر یک اتم و اتصالات بین این نقاط نمایانگر پیوندهای شیمیایی باشند.
دادههای ترتیبی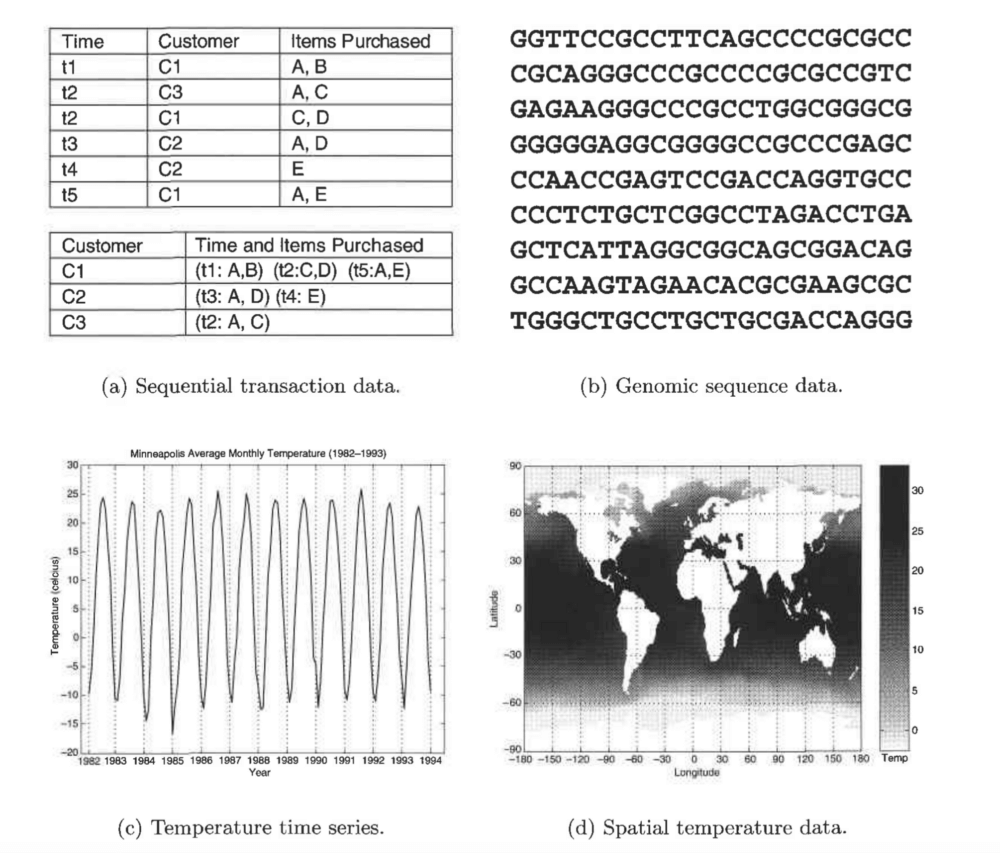
در برخی از انواع دادهها، رابطه صفات دادهها با یکدیگر دارای ترتیب زمانی یا فضایی است. همانطور که در تصویر بالا مشاهده میکنید، این قبیل دادهها را میتوان در ۴ دسته مجزا بررسی کرد:
دادههای متوالی: این دادهها که گاه با نام دادههای موقتی نیز از آنها یاد میشود را میتوان دادههای ثبتی تعمیمیافته دانست که هر رکورد آن یک زمان مشخص دارد. برای مثال، دیتاست مربوط به تراکنشهای یک خردهفروشی را درنظر بگیرید که علاوهبر خود تراکنشها زمان انجام تراکنش نیز در آن ذخیره شده است.
دادههای رشتهای: دادههای رشتهای به دیتاستی گفته میشود که حاوی رشتهای از دادههای مجزا (برای مثال، رشتهای از کلمات یا حروف) است. این دادهها شباهت زیادی به دادههای متوالی دارند، اما تفاوت آنها در این است که دادههای رشتهای بهجای زمان، یک جایگاه مشخص در رشته ترتیبی مربوطه دارند. برای مثال، اطلاعات ژنتیکی گیاهان و جانوران را میتوان در قالب دادههای رشتهای و بهصورت رشتهای از نوکلئوتیدها (که هر یک به عنوان یک ژن درنظر گرفته میشوند) ذخیره کرد.
دادههای سری زمانی: دادههای سری زمانی نوع خاصی از دادههای متوالی هستند که در آنها هر رکورد یک سری زمانی است؛ برای مثال، در هر رکورد میتوان نتایج ارزیابی یک مسئله درطول زمان را ذخیره کرد. برای ارائه یک مثال دیگر از دادههای سری زمانی میتوان یکی از انواع دیتاست های مالی را درنظر گرفت که هر یک از اشیاء آن یک سری زمانی از قیمت روزانه چندین سهم متفاوت باشد.
دادههای فضایی: در این نوع دادهها، برخی از اشیاء علاوهبر سایر صفاتشان، صفات فضایی همچون مکان یا ناحیه نیز دارند. برای مثال، دادههای آبوهوایی (بارش، دما یا فشار) را درنظر بگیرید که از موقعیتهای جغرافیایی مختلف جمعآوری شدهاند.
خب تا اینجا انواع دیتاست ها در حوزه علوم داده، دادهکاوی و یادگیری ماشینی برای شما توضیح داده شد. اگر مقالهای با موضوعی خاص مد نظر دارید برای ما در بخش نظرات وارد کنید تا در اسرع وقت برای شما در هوشیو منتشر شود.
منبع: hooshio.com


























