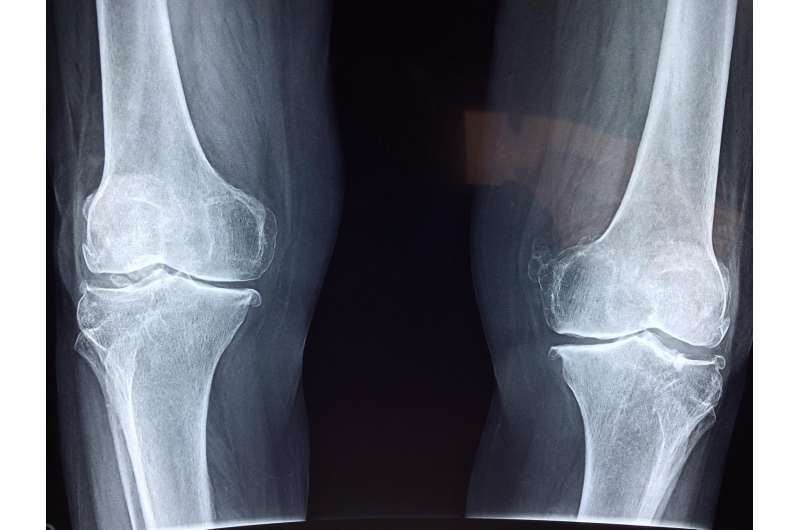
آرتروز
زانو یک بیماری جهانی است. تقریبا نیمی از افراد بالای ۷۵ سال با یکی از
انواع آرتروز زانو درگیر هستند و این بیماری به عنوان یکی از اصلیترین
دلایل معلولیت در سراسر جهان شناخته شده است. بدتر اینکه با توجه به عدم
وجود درمانی برای این بیماری، رسیدن به راهحل مناسب برای درمان آن نیازمند
شناسایی دقیق و مرحلهبندی این بیماری است.
محققان دانشکده گزشکی دانشگاه بوستون با استفاده از یک رویکرد مبتنی بر هوش مصنوعی و یادگیری عمیق توانستند گامی موثر در جهت تعیین شدت آرتروز زانو بردارند و نام آن را «طول استخوان زیرغضروفی» گذاشتهاند.
دستگاههای
تصویربرداری مخصوص آرتروز زانو که بتوانند عملکردی قابلقبول داشته باشند،
زیاد نیستند. درحالحاضر از ابزارهای تصویربرداری پزشکی مانند تصویربرداری
تشدید مغناطیسی یا اشعه ایکس برای بررسی مفاصل زانو استفاده میشود.
ویجایا
کولاچالاما، دستیار دکترای دانشگاه بوستون، در اینباره میگوید: «مطالعات
ما منجر به شناسایی روش تصویربرداری جدیدی شده که توانایی تبدیل شدن به
نشانگر زیستی آتروز زانو را دارد.»
محققان
برای تعریف روش جدید از هزاران اسکن MRI استفاده کردند تا بتوانند درجه
مسطح شدن غضروف و استخوان و رابطه آن با تنگی فضای رادیوگرافی مفصل، درد
همزمان و ناتوانی و همچنین جابجایی جزئی یا کلی زانو در آینده را به ماشین
آموزش دهند. آنها سپس از تغییرات نسبی در روش طول استخوان زیرغضروفی، نسبت
شانس را برای هریک از این نتایج تخمین زدند و دریافتند که مقادیر طول
استخوان زیرغضروفی در زانوهایی که دچار باریکی فضای مفصل شدهاند و
زانوهایی که این مشکل را ندارند، متفاوت است. آنها همچنین دریافتند که
تغییرات بیشتر طول استخوان زیرغضروفی در ابتدا با درد و ناتوانی بیشتر
همراه است.
طبق ادعای
محققان، این مطالعه پیامدهای بالینی مهمی دارد. کولاچالاما در ادامه
میگوید: «مطالعه ما طول استخوان زیرغضروفی را به عنوان اندازهگیری بالقوه
مفیدی برای مورفولوژی استخوان در مفصل زانو شناسایی کرده و نشان داده که
این موضوع متفاوت از درجه بیماری است. طول استخوان زیرغضروفی همچنین این
پتانسیل را دارد که در آینده درجه آرتروز زانو را هم بسنجد.»
قدم
بعدی برای محققان بررسی این موضوع است که آیا طول استخوان زیرغضروفی
میتواند برای تشخیص بهموقع بیماری مورد استفاده قرار گیرد یا خیر. اگر
این شرایط فراهم شود میتواند تاثیر چشمگیری بر پروسه مدیریت مراقبت از
بیمار داشته باشد.
مباحث
یادگیری عمیق و شبکههای عصبی میتوانند گیجکننده باشند. اما باید توجه
داشته باشید که برای استخدام یادگیری عمیق در مصاحبههای کاری علوم داده،
عمدهی سؤالات از چند مبحث خاص مطرح میشوند. بعد از بررسی صدها نمونه از
این مصاحبهها، به ۱۰ مفهوم از یادگیری عمیق رسیدم که اغلب موردتوجه مصاحبهگران قرار میگیرد.
در این نوشتار، این ۱۰ مفهوم را با هم مرور میکنیم:
توابع فعالسازی
در صورتی که شناختی از شبکه های عصبی و ساختار آنها ندارید پیشنهاد میکنم ابتدا این مقاله را مطالعه کنید تا مشکلی برای استخدام یادگیری عمیق از این بابت نداشته باشید.
بعد
از آشنایی مختصر با نورونها/گرهها، درمییابید تابع فعالسازی مثل کلیدی
است که تعیین میکند یک نورون خاص باید فعال شود یا خیر.
توابع
فعالساز انواع مختلفی دارند، اما از محبوبترین آنها میتوان به تابع
یکسوساز خطی یا ReLU اشاره کرد. این تابع از توابع سیگموئید و تانژانت
هذلولوی شناختهشدهتر است، زیرا گرادیان کاهشی را با سرعت بیشتری اجرا
میکند. با توجه به تصویر بالا، مشاهده میکنید که وقتی x (یا z) خیلی بزرگ
باشد، شیب به شدت کاهش مییابد و در نتیجه سرعت کاهش گرادیان به میزان
چشمگیری آهسته میشود. اما این نکته برای تابع ReLU صدق نمیکند.
تابع هزینه
تابع هزینه یک شبکهی عصبی مانند توابع هزینهای است که در سایر مدلهای یادگیری ماشین
به کار میروند و برای استخدام یادگیری عمیق آشنایی با آنها ضروری است.
تابع هزینه معیاری برای ارزیابی عملکرد مدل، از طریق سنجش شباهت مقادیر
پیشبینیشده با مقادیر واقعی است. تابع هزینه با کیفیت مدل رابطهی عکس
دارد؛ یعنی هر چه مدل بهتر باشد، تابع هزینه پایینتر خواهد بود و بالعکس.
تابع هزینه را میتوان بهینهسازی کرد.وزنها و پارامترهای بهینهی مدل، با حداقل ساختن تابع هزینه قابل دسترسی هستند.
از
توابع هزینهی متداول میتوان به تابع درجه دوم، تابع آنتروپی متقاطع،
تابع هزینه نمایی، فاصله هلینگر و واگرایی کولبک-لیبلر اشاره کرد.
پسانتشار
موردی
که برای استخدام یادگیری عمیق باید بدانید این است که پسانتشار ارتباط
نزدیکی با تابع هزینه دارد. پسانتشار الگوریتمی است که برای محاسبهی
گرادیان تابع هزینه به کار میرود. این الگوریتم با توجه به سرعت و کارآیی
بالایی که در مقایسه با سایر رویکردها دارد، از محبوبیت و کاربرد بالایی
برخوردار شده است.
نام
پسانتشار برگرفته از این واقعیت است که محاسبهی گرادیان از آخرین لایهی
وزنها آغاز شده و به سوی گرادیانهای اولین لایه، یعنی به سمت عقب، حرکت
میکند. بنابراین خطای لایهی k وابسته به لایهی بعدی یعنی k+1 است.
نحوهی کار الگوریتم پسانتشار را میتوان در این گامها خلاصه کرد:
انتشار رو به جلو را برای هر جفت ورودی-خروجی محاسبه میکند؛
انتشار رو به عقب هر جفت را محاسبه میکند؛
گرادیانها را ترکیب میکند؛
وزنها را بر اساس نرخ یادگیری و گرادیان کلی، به روزرسانی میکند.
این مقاله به خوبی مبحث پسانتشار را پوشش داده و برای مبحث استخدام یادگیری عمیق مناسب است.
شبکههای عصبی پیچشی
شبکهی
عصبی پیچشی (CNN) نوعی شبکهی عصبی است که به ویژگیهای مختلف ورودی (که
اغلب یک تصویر و یا بخشی از یک متن میباشد.) مقادیر اهمیت اختصاص داده و
سپس یک خروجی تولید میکند. آنچه باعث مزیت CNNها نسبت به شبکههای عصبی
پیشخور میشود این است که وابستگیهای فضایی (پیکسلی) سراسر تصویر، و در
نتیجه ترکیب تصویر را بهتر درک میکند.
CNNها
در واقع یک عملیات ریاضیاتی به نام کانولوشن اجرا میکنند. طبق تعریف
ویکیپدیا، کانولوشن یک عملیات ریاضیاتی است که روی دو تابع انجام میشود و
خروجی آن، تابع سومی است که نشان میدهد شکل یکی از آن توابع چطور توسط
دیگری تغییر میکند. پس CNN به جای ضربهای ماتریسی معمولی، حداقل در یکی
از لایههای خود، از عملیات کانولوشن استفاده میکند.
شبکههای عصبی بازگشتی
اگر
مشتاق استخدام یادگیری عمیق هستید باید بدانید شبکههای عصبی
بازگشتی (RNN) نوع دیگری از شبکههای عصبی هستند که به خاطر قابلیت پردازش
دادههایی با اندازههای گوناگون، روی دادههای توالی عملکرد بسیار خوبی از
خود نشان میدهند. RNNها علاوه بر ورودیهای فعلی، ورودیهای قبلی را هم
درنظر میگیرند؛ بنابراین یک ورودی خاص میتواند بر اساس ورودیهای قبلی،
خروجیهای متفاوتی تولید کند.
از
نظر فنی، RNNها گروهی از شبکههای عصبی هستند که اتصالات بین گرههایشان،
علاوه بر یک توالی زمانی، یک گراف جهتدار ایجاد میکند و بدین ترتیب آنها
را قادر میسازد از حافظهی داخلی خود برای پردازش توالیهایی با طول
متغیر استفاده کنند.
به بیان خلاصه، RNNها نوعی از شبکههای عصبی هستند که اساساً روی دادههای توالی یا سریهای زمانی به کار میروند.
شبکههای حافظهی کوتاهمدت بلند (LSTM)
شبکههای LSTM نوعی از شبکه های عصبی بازگشتی
هستند که برای جبران یکی از نقاط ضعف RNNها یعنی حافظهی کوتاهمدت، ساخته
شدهاند و برای استخدام یادگیری عمیق باید با آن آشنا باشید.
به
بیان دقیقتر، اگر یک توالی طولانی داشته باشیم (برای مثال رشتهای با
بیشتر از ۵-۱۰ گام)، RNNها اطلاعات مربوط به گامهای اول را فراموش خواهند
کرد. به عنوان مثال، اگر یک پارگراف را به RNN تغذیه کنیم، احتمال نادیده
گرفته شدن اطلاعات ابتدای پارگراف وجود دارد.
LSTMها برای حل این مشکل به وجود آمدند.
در این مطلب میتوانید اطلاعات بیشتری در مورد LSTMها به دست آورید.
تعریف وزن
هدف از تعریف وزن اطمینان حاصل کردن از این است که شبکهی عصبی به یک راهکار بیهوده همگرایی نخواهد داشت.
اگر
مقدار تعریفشده برای همهی وزنها یکی باشد (برای مثال همه ۰ باشند)،
همهی واحدها سیگنالی دقیقاً یکسان دریافت میکنند؛ در نتیجه، لایهها طوری
رفتار میکنند که فقط یک سلول واحد وجود دارد.
بنابراین،
باید به صورت تصادفی مقادیر نزدیک صفر، اما نه خود صفر، را به وزنها
اختصاص دهیم. الگوریتم بهینهسازی تصادفی که برای آموزش مدل به کار میرود
از این قاعده استثناست.
مقایسه گرادیان کاهشی تصادفی با گرادیان کاهشی دستهای
افراد
مایل به استخدام یادگیری عمیق باید بدانند که گرادیان کاهشی دستهای و
گرادیان کاهشی تصادفی دو روش متفاوت برای محاسبهی گرادیان هستند.
گرادیان
کاهشی دستهای، گرادیان را بر اساس همهی دیتاست محاسبه میکند. این روش
در دیتاستهای بزرگ، سرعت پایینی خواهد داشت، اما برای هموارسازی یا واگرا
شدن منیفلد خطا بهتر است.
در
روش گرادیان کاهشی تصادفی، گرادیان در هر بازهی زمانی، بر اساس یک
نمونهی آموزشی واحد محاسبه میشود. به همین خاطر، این روش از نظر محاسباتی
سریعتر و کمهزینهتر است. با این حال، در این روش، بعد از رسیدن به
کمینهی سراسری، جستجو در اطراف همچنان ادامه میباید. نتیجهی این روش
قابلقبول است، اما بهینه نیست.
هایپرپارامترها
هایپرپارامترها
متغیرهایی هستند که ساختار شبکه را تنظیم میکنند و بر نحوهی آموزش آن
نظارت دارند. از جمله هایپرپارامترهای متداول میتوان به این موارد اشاره
کرد:
پارامترهای معماری مدل همچون تعداد لایهها، تعداد واحدهای نهان، و …؛
نرخ یادگیری (آلفا)؛
تعریف وزنهای شبکه؛
تعداد دورهها (دوره به معنی یک چرخهی کامل در دیتاست آموزشی است)
اندازهی بستهداده
نرخ یادگیری
نرخ
یادگیری یکی از هایپرپارامترهای شبکههای عصبی است که بر اساس خطای برآورد
شده در هربار به روزرسانی وزنها، میزان انطباق مدل را تعیین میکند.
اگر
نرخ یادگیری خیلی پایین باشد، سرعت آموزش مدل آهسته خواهد بود؛ زیرا در هر
تکرار، وزنهای مدل به حداقل میزان ممکن به روزرسانی خواهند شد. به همین
دلیل، قبل از رسیدن به کمینه، باید بهروزرسانیهای زیادی انجام شود.
اگر نرخ یادگیری خیلی بالا باشد، توابع زیان
رفتاری واگرا خواهند داشت. زیرا در به روزرسانی وزنها، تغییراتی چشمگیر
رخ میدهد. این رفتار ممکن است آنقدر شدید باشد که تابع هیچگاه همگرا
نشود.
در کنار فراگرفتن مهارتهای فنی، آشنایی با روند کاری یا گردش کار تیمهای مختلف هوش مصنوعی برای طیف مختلف علاقهمندان به هوش مصنوعی ضروری است. در این مقاله با استفاده از مثالهایی سعی میکنیم گردش کار در تیمهای یادگیری ماشین و دادهکاوی را توضیح دهیم. در تهیه این مطلب از دوره هوش مصنوعی برای همهاندرو ان جی استفاده شده است.
اگر
اندکی با هوش مصنوعی آشنا باشید حتماً نام اندرو ان جی را شنیدهاید. ان
جی در شرکتهای بزرگی مثل گوگل، بایدو و چند شرکت دیگر تیمهای هوش مصنوعی و
یادگیری ماشین را رهبری کرده است. بنابراین توضیحاتی که او درباره گردش
کار در تیمهای مختلف هوش مصنوعی میدهد میتواند برای بسیاری از شرکتها و
علاقهمندان این حوزه مفید باشد.
گردش کار در تیمهای یادگیری ماشین
الگوریتمهای
یادگیری ماشین میتوانند نحوه رسیدن از ورودی به خروجی یا از A تا B را
بیاموزند. اما این فرایند چگونه در یک پروژه یادگیری ماشین طی میشود؟
برای
درک بهتر مسئله بگذارید از همان ابتدا بحث را با یک مثال پیش ببریم. فرض
کنید میخواهیم محصولی را با استفاده از یادگیری ماشین تولید کنیم. مثلاً
محصول تولیدی ما مربوط به فناوری تشخیص گفتار است.
محصولاتی مثل الکسای آمازون، گوگل هوم، سیری اپل مثالهایی از این فناوری هستند.
مراحل اساسی در یک پروژه ماشین لرنینگ
به نظر شما در تولید الکسا چه فرایندی طی شده است؟
-جمعآوری داده
اولین مرحله در پروژههای هوش مصنوعی و یادگیری ماشین جمعآوری داده است.
مثلاً
درمورد الکسا شما باید صداها و لهجههای مختلفی را جمعآوری کنید که در آن
بگویند «الکسا». همچنین نیاز دارید افراد دیگری باشند که واژه های دیگری
را بگویند مانند «سلام» یا خیلی از واژههای دیگر.
-آموزش مدل
حال
که مقدار زیادی داده صوتی جمع کردید که در آن افراد الکسا را صدا میزنند
یا از کلمات دیگر استفاده میکنند نوبت به آموزش دادن مدل میرسد. این
مرحله بدین معناست که ما از الگوریتمهای یادگیری ماشین استفاده میکنیم تا
ماشین فرایند رسیدن از ورودی به خروجی را بیاموزد.
در اینجا ورودی ما فایل صوتی است که کسی میگوید الکسا و خروجی ما این است که سیستم میآموزد بگوید الکسا.
وقتی
که تیم هوش مصنوعی فرایند یادگیری را شروع میکنند، طبیعی است که تلاشهای
اولیه کیفیت لازم را نداشته باشد. بنابراین تیم باید چند بار این مسیر را
طی کند تا به نتیجه مطلوب برسد.
جاسازی و بهکارگیری مدل
در
این بخش مدلی که طراحی کردهایم را درون یک اسپیکر هوشمند واقعی قرار
میدهیم. و بهصورت آزمایشی به تعدادی از کاربران میدهیم. معمولاً اتفاقی
که در این مرحله میافتد این است که با استفاده ای که این کاربران از مدل
میکنند دادههای جدیدی وارد مدل میشود و عملکرد سیستم بهبود مییابد.
برای
مثال فرض کنید شما یک سیستم بازشناسی گفتار دارید که با دادههای صوتی
انگلیسی با لهجه آمریکایی آموزش دادهاید. حال این محصول را در اختیار
تعداد محدودی از کاربران با لهجه انگلیسی بریتانیایی هم قرار میدهید. چه
اتفاقی میافتد؟ احتمالا سیستمتان با لهجه بریتانیایی خیلی خوب کار
نمیکند. اما شما این دادهها را جمع میکنید و مدل را بهروزرسانی
میکنید.
نکتهای که باید در
نظر داشت این است که این مراحل خطی نیستند و بارها و بارها در طول تولید
محصول به مراحل مختلف بازمیگردیم و با دانستههای جدید بهبود میبخشیمشان.
این
مراحل اصلی تقریباً در بقیه پروژههای یادگیری ماشین نیز تکرار میشود.
برای مثال بگذارید نگاهی بیندازیم به مراحل اصلی استفاده از یادگیری ماشین
در تولید ماشینهای خودران.
برای
استفاده از یادگیری ماشین در خودروهای خودران مانند مثال قبل باید ابتدا
به این سوال پاسخ دهیم که ورودی و خروجی ما چه خواهد بود؟ در اینجا ورودی
ما تصاویر خودروهاست و خروجی ما سیستمی است که میتواند خودروها را در
موقعیتهای مختلف تشخیص دهد. در اینجا نیز دوباره اولین قدم جمعآوری
دادههاست.
ما به تصاویر متعددی نیاز داریم که در آن انواع خودروها را در موقعیتهای مختلف نشان دهد.
پس
از آن نوبت به آموزش مدل میرسد. در این مرحله سیستمی که ساختهایم باید
بتواند با استفاده از الگوریتمهای یادگیری ماشین خودروها را تشخیص دهد. و
در آخر نوبت به جایگذاری و استفاده از این فناوری میرسد. این محصول را
بهصورت آزمایشی در اختیار کاربران قرار میدهیم و از طریق دادههای جدیدی
که این خودروها حین استفاده جمع میکنند دوباره وارد چرخه گردش کاری
یادگیری ماشین میشویم.
گردش کار در پروژههای دادهکاوی
برخلاف پروژه یادگیری ماشین، برونداد پروژه در علوم داده
مجموعهای از بینشهای عملیاتی است. بینشهایی که ممکن است باعث شود ما
عملکردهایمان را تغییر دهیم. با توجه به این هدف متفاوت، گردش کار در
پروژههای دادهکاوی هم از پروژههای یادگیری ماشین متفاوت است.
همانند
یادگیری ماشین بگذارید در اینجا هم بحث را با مثالی پیش ببریم. فرض کنیم
که شما فروشگاه اینترنتی دارید که کارش فروختن ماگ است. خریداران برای
خریدن ماگ از شما مراحلی را طی میکنند. ابتدا وارد سایت شما میشوند و
نگاهی به محصولاتتان میاندازند، بعد احتمالاً محصولی را انتخاب میکنند،
به صفحه محصول موردنظر میروند و آن را در سبد خرید خود قرار میدهند و سپس
پرداخت را انجام میدهند و فرایند تمام میشود. علم داده در این فرایند چه
کمکی میتواند به شما بکند؟
گامهای اساسی در یک پروژه علم داده
- جمعآوری داده
همانطور
که پیش از این گفتیم جمعآوری داده نقطه شروع اغلب پروژههای هوش مصنوعی
است. در همین مثال فروشگاه، ما میتوانیم مجموعهدادهای بسازیم از نام
کاربری، IPهای وارد شده، زمان ورود، میزان خرید و مواردی از این دست
- تحلیل دادهها
در این مرحله تیم دادهکاوی ایدهها و تحلیلهای زیادی را از دادهها بیرون میکشند.
برای
مثال با در نظر گرفتن IPهای که وارد سایت شده میتوان فهمید برخی از
کاربران که از کشورهای دیگر وارد سایت شدهاند تا صفحه خرید محصول رفتهاند
اما بهخاطر هزینههای زیاد خرید محصول از خارج از کشور از خرید منصرف
شدهاند. یا مثلاً ازطریق تحلیل داده ها
الگویی به دست میآید که نشان میدهد در روزهای تعطیل خریدها افزایش یا
کاهش داشته است. کشف نقاط اوج و نزول خرید میتواند در سیاستهای تبلیغاتی
شرکت هم اثرگذار باشد و تبلیغات اثرگذارتر پیش برود و از صرف هزینههای
بیهوده پیشگیری میشود.
یک
گروه تحلیل داده خوب ایدههای زیادی دارد و همه ایدهها را بهصورت مستمر
بررسی میکند. بنابراین در این مرحله ما با فرایندهای تکراری و بررسیهای
چندباره یک ایده مواجهیم.
- پیشنهاد فرضیهها/ اقدامات
در مرحله آخر تیم تحلیل داده از دل بررسی و آزمون ایدههای زیادی که دارد به چند فرضیه و اقدامات موثر در راستای آن فرضیهها میرسد.
با
بهکارگیری استراتژیها و بینشهای جدیدی که از دل تحلیل دادهها درآمده
دوباره دادههای جدیدی تولید میشود. تیم دادهکاوی دوباره این دادهها را
تحلیل میکند و همان مراحل قبلی را طی میکند. اینجاست که چرخه گردش کاری
یک تیم تحلیل داده شکل میگیرد.
برای اینکه درک بهتری از این چرخه داشته باشید، یک مثال دیگر میزنیم.
فرض
کنیم میخواهیم با استفاده از علم داده پیشنهادهایی برای بهبود کار خط
تولید یک کارخانه ارائه دهیم. بگذارید با همان مثال قبلیمان، یعنی ماگ،
پیش برویم. قدم اول در تولید ماگ ترکیب خاک و دیگر مواد اولیه با هم است.
مرحله دوم به شکل ماگ درآوردن این مواد اولیه است. در مرحله دوم حاصل کار
مراحل قبلی رنگآمیزی میشود و لعاب داده میشود. حال ماگهای ساخته شده به
حرارت نیاز دارند، بنابراین آنها را در کوره میگذاریم تا حرارت لازم را
ببینند. مرحله آخر فرایند تولید ماگ هم تشخیص ماگهای سالم و غیر سالم و
بدون کیفیت است.
بالا بردن
بهرهوری در خط تولید همواره از دغدغههای اصلی کارخانههای تولیدی بوده
است. در اینجا هم تلاش برای به حداقل رساندن ماگهای معیوب و ناقص میتواند
مسئله مهمی برای کارفرما باشد.
حال
اگر به مراحل انجام پروژه دادهکاوی بازگردیم، مرحله اول جمعآوری داده
است. در این مثال میتوان اطلاعات بسیار زیادی جمعآوری کرد. از درصد
استفاده از مواد اولیه صرفشده برای هر دسته ماگ تا مدت زمان ماندن در
کوره، دمای کوره تا میزان محصولات نامرغوب در هر دسته از ماگهای تولید
شده.
در اینجا هم تیم
دادهکاوی دادهها را بارها و بارها تحلیل میکند و به هم ربط میدهد و
ایدههای زیادی از دادهها بیرون میکشد. تیم پس از غربال کردن ایدهها و
تحلیلهایش به تعداد اندکی ایده و راهنمای عمل مشخص میرسد.
این
راهنمای عمل و استراتژی جدید در خط تولید به کار گرفته میشود، دادههای
جدید تولید میشود و این دادهها دوباره نیاز به تحلیل دارد و این چرخه
ادامه پیدا میکند.
جمعبندی
بسته
به اینکه پروژهها در چه حوزهای از هوش مصنوعی تعریف شوند، گردش کاری
آنها نیز متفاوت خواهد بود. در این مطلب با استفاده از مثالهای مختلف
گردش کار در پروژههای یادگیری ماشین و دادهکاوی را بررسی کردیم. لازمه هر
نوع فعالیت در بازار هوش مصنوعی، چه در بخش سرمایهگذاری و چه بهعنوان
نیروی متخصص، آشنایی با روندی است که در هر پروژه هوش مصنوعی طی میشود.
دنیا همگام با پیشرفت فناوریهای یادگیری ماشین (ML) و هوش مصنوعی
(AI)، در حال تغییر و تحول است و به همین دلیل نیاز به مهندس یادگیری
ماشین و هوش مصنوعی محسوستر شده است. ML و AI در بسیاری از دستگاهها، از
سیستمهای آندروید گوشیهای همراه و سایر دستگاههای الکترونیک گرفته تا
خودروهای خودران، نقش مهمی ایفا کردهاند. اهمیت این نقش به صورت روزافزون
در حال افزایش است، به طوری که برآورد میشود طی دو سال آینده، هوش مصنوعی
بیش از ۲ میلیون فرصت شغلی ایجاد کند.
بر
اساس گزارشات شرکت Market & Markets، انتظار میرود ارزش بازار
یادگیری ماشینی که در سال ۲۰۱۶ معادل ۱ میلیاد دلار بود، در سال ۲۰۲۲ به ۹
میلیارد دلار برسد؛ این ارقام حاکی از یک CAGR (نرخ رشد مرکب سالانه) ۴۴
درصدی هستند. طبق پیشبینیها، بازار هوش مصنوعی نیز تا قبل از سال ۲۰۲۵ به
یک صنعت ۱۹۰ میلیارد دلاری تبدیل خواهد شد. این روند رو به رشد باعث شده
تقاضای مشاغل مهندس یادگیری ماشین و هوش مصنوعی به میزان چشمگیری افزایش
یابد.
در این نوشتار، علاوه بر فرصتهای شغلی ML و AI، مهارتهای لازم و برنامههای اعطاکننده گواهینامههای مربوطه را نیز معرفی میکنیم.
فرصتهای شغلی هوش مصنوعی
با
افزایش کاربرد ML و AI، مشاغل موجود در این حوزهها دقیقتر و تخصصیتر
میشوند. در این قسمت، برخی از این مشاغل و میانگین درآمد سالانهی آنها
را معرفی میکنیم:
مهندس هوش مصنوعی:
مهندسان هوش مصنوعی موظف به حل مسئله، ساخت مدلهای هوش مصنوعی و آزمایش و
پیادهسازی آنها هستند. علاوه بر این، باید قادر به مدیریت زیرساختهای
هوش مصنوعی نیز باشند. مهندسان AI به کمک الگوریتمهای یادگیری ماشینی و
شناختی که از شبکه های عصبی دارند، مدلهای هوش مصنوعی بهتری میسازند.
میانگین درآمد سالانه: ۱۱۶۵۴۰ دلار
مهندس یادگیری ماشین:
این متخصصان مسئول ساخت و نگهداری نرمافزارهای خودرانی هستند که به
کاربردهای یادگیری ماشینی کمک میکنند. از آنجایی که مهندس یادگیری ماشین
با حجم زیادی داده سر و کار دارند، باید تسلط کافی بر مباحث مدیریت داده ها داشته باشند.
میانگین درآمد سالانه: ۱۲۱۱۰۶ دلار
توسعهدهنده هوش تجاری (BI):
توسعهدهندههای BI باید دادههایی پیچیده را طراحی، مدلسازی، تحلیل و
نگهداری کنند. این افراد با ترکیب هوش تجاری و هوش مصنوعی، به رشد درآمد
شرکتها کمک میکنند.
میانگین درآمد سالانه: ۹۰۴۳۰ دلار
متخصص رباتیک:
وظیفهی این متخصصان، ارتقای کارآمد مسائلی است که توسط رباتها انجام
میشود. صنایع عمده تمایل دارند دستگاههای خود را برنامهنویسی کرده یا
دستگاههای مکانیکی/ رباتهایی بسازند که دستورات مختلف انسانها را اجرا
میکنند؛ این صنایع، فرصتهای شغلی فراوانی برای این دسته از متخصصان فراهم
میآورند.
میانگین درآمد سالانه: ۸۳۲۴۱ دلار
با
پیشرفت فناوری، فرصتهای شغلی حوزههای یادگیری ماشینی و هوش مصنوعی نیز
توسعه خواهند یافت. برای به دست آوردن این مشاغل، باید بر مهارتهای خاصی
تسلط داشت.
مهارتهای ضروری برای مشاغل یادگیری ماشینی و هوش مصنوعی
عرصهی
هوش مصنوعی و یادگیری ماشینی فرصتهای شغلی بسیار زیادی در بردارند.
متقاضیان این مشاغل باید از جنبههای گوناگون این حوزهها، از برنامهنویسی
و مباحث اجرایی ساده گرفته تا پژوهشهای پیشرفته، درکی جامع داشته باشند.
تسلط بر مهارتهای لازم، چه فنی و چه غیرفنی، به آیندهی شغلی متقاضیان کمک
میکند.
مهارتهای فنی
زبانهای برنامهنویسی
برای
همگام ماندن با آخرین فناوریها، آشنایی با زبانهای برنامهنویسی ضروری
است. زبانهای برنامهنویسی فراوان هستند و رتبهبندی آنها از نظر کیفیت
کار آسانی نیست. از برجستهترین زبانهای برنامهنویسی که در هوش مصنوعی به
کار میروند میتوان به این موارد اشاره کرد:
Lisp
Java
C ++
Python
R
پایتون
محبوبترین زبان برنامهنویسی در یادگیری ماشینی به شمار میرود. این زبان
به پلتفرم وابسته نیست و به آسانی در کنار سایر زبانهای برنامهنویسی به
کار میرود.
جبر خطی/ حسابان/ آمار/ احتمال
آمار به فرآیند تجزیه و تحلیل دیتاست
اشاره دارد که به منظور تعیین خواص ریاضی منحصر به فرد آن دادهها انجام
میشود. یادگیری ماشینی از عملیاتهای آماری شروع شده و سپس فراتر میرود.
میانگین، میانه، نما، واریانس، و انحراف معیار شاخصهایی هستند که برای
توصیف دیتاست به کار میروند. تسلط بر مبحث احتمالات به درک بهتر مدلهای
مختلف هوش مصنوعی و یادگیری ماشینی کمک میکند.
ریاضیات کاربردی، چارچوبها و الگوریتمها
آشنایی
با مبانی نظری الگوریتمها و نحوهی کارکرد آنها از اهمیت بالایی
برخوردار است. افراد باید با مباحثی از قبیل گرادیان کاهشی، (ضرایب)
لاگرانژی، بهینهسازی محدب، معادلات دیفرانسیل جزئی، برنامهنویسی درجهی
دوم، و جمعزنی آشنایی داشته باشند. علاوه بر این، برای ساخت مدلهای هوش
مصنوعی با استفاده از دادههای بدون ساختار، باید بر الگوریتمهای یادگیری عمیق
و نحوهی پیادهسازی آنها با استفاده از یک چارچوب مشخص تسلط داشت. چند
نمونه از چارچوبهایی که در هوش مصنوعی به کار میروند عبارتاند از:
TensorFlow، PyTorch، Theano، و Caffe.
کتابخانهها و ابزارهای پردازش زبان طبیعی (NLP)
هدف اصلی پردازش زبان طبیعی یا
NLP، ترکیب علوم کامپیوتر، مهندسی اطلاعات، زبانشناسی، هوش مصنوعی و
برنامهنویسی سیستمها به منظور پردازش و تحلیل دیتاستهای بزرگ است. مهندس
یادگیری ماشین و هوش مصنوعی باید بتواند مسائل گسترده و جامع NLP، از
قبیل پردازش زبان، صوت و ویدئو، را اجرا کند؛ در این راستا، استفاده از
کتابخانهها و ابزارهای متعدد NLP از این دست ضروری است:
NTLK
Gensim
Word2vec
TextBlob
CoreNLP
تجزیه و تحلیل عواطف
PyNLPI
شبکههای عصبی
شبکهی
عصبی، سیستمی (سختافزاری یا نرمافزاری) است که مانند مغز انسان عمل
میکند. شبکههای عصبی مصنوعی بر اساس نحوهی کارکرد مغز انسانها طراحی
شدهاند. البته این شبکهها تنها شیوهی درک انسانها را تقلید نمیکنند،
بلکه در مسائلی به کار میروند که بسیار فراتر از قابلیتهای انسانی است.
شبکههای عصبی را میتوان در زمینههای کاری و تجاری گوناگونی به کار برد.
مهندسان هوش مصنوعی باید بتوانند مسائل پیچیدهای از نوع تشخیص الگو،
شناسایی چهره، تشخیص دستخط و … را حل کنند.
اگر
کسی بخواهد دانش خوبی از این مباحث به دست آورده و مهارتهای خود را
ارتقاء دهد، گذراندن دورههای هوش مصنوعی و دریافت گواهینامههای مربوطه به
او کمک خواهند کرد شغلی مناسب با درآمدی قابلقبول، به عنوان یک مهندس
یادگیری ماشین و هوش مصنوعی، به دست آورد.
مهارتهای غیرفنی
تکرار ایدهها (الگوسازی سریع)
برای
رسیدن به بهترین ایدهی ممکن، تکرار ایدهها فرآیندی ضروری است. تکرار
ایدهها در همهی جنبههای یادگیری ماشینی (از انتخاب مدل مناسب گرفته تا
کار روی پروژههایی همچون آزمایشات A/B، کتابخانههای NLP و غیره) قابل
اجراست. متقاضیان، به خصوص زمانی که با مدلهای سه بُعدی سروکار دارند،
باید بتوانند با استفاده از تکنیکهای گوناگون و به کمک طراحیهای
کامپیوتری سه بُعدی، مدلهای واقعگرایانهای متشکل از اجزاء یا مجموعههای
مستحکم بسازند.
دانش از حوزهی تخصصی
موفقترین
پروژههای هوش مصنوعی آنهایی هستند که به شکل مناسب و کارآمد، نقاط ضعف
اصلی را درگیر میکنند. به همین دلیل، داشتن درکی جامع از حوزهی تخصصی
مربوطه و راههای کسب منفعت از آن اهمیت بالایی دارد.
تفکر خلاق و بحرانی
گذراندن
دورههای آموزشی هوش مصنوعی و کسب گواهینامههای مربوطه به افرادی که
میخواهند با این مباحث آشنا شده و مهارتهای خود را ارتقاء دهند، کمک
میکند. این دورهها، آغاز مسیر دستیابی به مشاغل هوش مصنوعی با درآمدی
قابلقبول هستند.
برترین برنامههای اعطاکننده گواهینامه در حوزهی هوش مصنوعی
متقاضیان
مشاغل حوزههای هوش مصنوعی یا یادگیری ماشینی میتوانند با شرکت در
دورههای آموزشی اعطاکننده گواهی که در مؤسسات آموزشی مختلف برگزار
میشوند، مهارتهای خود را اثبات کنند. تقاضای شغلی برای افرادی که این
گواهینامهها را در دست دارند نسبت به گذشته افزایش یافته است؛ زیرا خیلی
از سازمانها این گواهیها را سنگ محکی برای ارزیابی متقاضیان شغلی
میدانند. در این قسمت، چند مورد از برترین دورههای آموزشی را معرفی
میکنیم که گواهینامههایی مهم و محبوب صادر میکنند:
«هوش مصنوعی برای همه» از Coursera
Coursera
یک پلتفرم آموزشی جهانی است که تعداد زیادی دورهی آموزشی با گواهیهای
معتبر ارائه میدهد. این سامانه با بیش از ۲۰۰ دانشگاه و سازمان برتر
همکاری دارد تا بتواند آموزشهای آنلاینی انعطافپذیر، مقرون به صرفه،
مرتبط با شغل در دسترس همگان قرار دهد. یکی از این دورههای آموزشی «هوش
مصنوعی برای همه» نام دارد. این دوره به اصطلاحات و واژهشناسی هوش مصنوعی
(همچون شبکههای عصبی، یادگیری ماشینی، یادگیری عمیقی و علوم داده)
میپردازد. با شرکت در این دورهی آموزشی، درک بهتری از راهبردهای گوناگون
هوش مصنوعی به دست خواهید آورد، درکی که به توسعهی پروژههای یادگیری
ماشینی و علوم داده کمک میکند.
«مهندس هوش مصنوعی (AIE™)» از ARTiBA
هیأت
هوش مصنوعی آمریکا (ARTiBA) با ارائهی گواهینامهی مهندسی هوش مصنوعی
(AIE™)، به متقاضیان کمک میکند مسیر شغلی خود در هوش مصنوعی را ارتقاء
دهند. گواهینامهی AIE™ که بر اساس چارچوب شناختهشده و بینالمللی AMDEX™
طراحی شده است، دانش لازم برای فعالیت به عنوان یک متخصص موضوعی (SME) را
در اختیار متقاضیان قرار میدهد.
در این دورهی آموزشی، متقاضیان مفاهیم گوناگون از قبیل یادگیری ماشینی، یادگیری با نظارت
و غیرنظارت شده، پردازش زبان طبیعی، محاسبات شناختی، یادگیری تقویتی و
یادگیری عمیق را میآموزند. شرکتکنندگان در این دوره میتوانند سرعت آموزش
را مطابق با نیاز خود تغییر دهند؛ امکان حضور در آزمون، ۴۵ روز پس از
ثبتنام وجود دارد.
«دورهی آموزش حرفهای هوش مصنوعی» از مایکروسافت
مایکروسافت
یک دورهی آموزشی هوش مصنوعی برگزار میکند که در انتهای آن گواهینامهای
معتبر نیز به شرکتکنندگان تعلق میگیرد. این دوره یک برنامهی آموزشی جامع
از مباحث مربوطه را در برمیگیرد. شرکتکنندگان با مباحث گوناگون همچون
مقدمات یادگیری ماشینی، زبان و ارتباطات، بینایی کامپیوتری، و همچنین
پایتون که زبان ضروری برای برنامهنویسی است، آشنا خواهند شد. شرکتکنندگان
آزادی عمل دارند و میتوانند بین مباحث بینایی کامپیوتری و تجزیه و تحلیل
تصویر و یا سیستمهای تشخیص گفتار و پردازش زبان طبیعی یکی را انتخاب کنند؛
در این حوزهها افراد میآموزند بر اساس دادهها، راهکارهایی هوشمند ارائه
دهند.
«مهندسی هوش مصنوعی» از simplilearn
Simplilearn
با همکاری IBM، یک دورهی آموزشی مهندسی هوش مصنوعی برگزار میکند. هدف از
این دورهی آموزشی، غنیسازی مهارتهای شرکتکنندگان و تربیت متخصص هوش مصنوعی
است. شرکتکنندگان با استفاده از قابلیتهای متنوع IBM همچون هکاتونها،
کلاسهای ارشد، جلسات زنده، آزمایشگاههای کاربردی، جلسات پرسش آزاد و
پروژههای گوناگون، میتوانند بر مفاهیم علوم داده به زبان پایتون، یادگیری
ماشینی، یادگیری عمیق و NLP تسلط یابند. علاوه بر این، امکان دسترسی به
حساب کاربردی IBM Cloud Lite و دریافت گواهینامهی ارشد هوش مصنوعی
Simplilearn (که در بین صنایع شناختهشده و پذیرفتهشده است) برای همهی
شرکتکنندگان وجود دارد.
جمعبندی
اگر
به دنبال فعالیت در حوزهی هوش مصنوعی هستید، باید مهارتها و
گواهینامههای لازم را در دست داشته باشید. با دریافت گواهینامههای لازم،
شانس خود را برای به دست آوردن شغلی بهتر در سازمانی خوشنام، افزایش
میدهید.
ایده یادگیری ماشین
مدتها پیش معرفی شده است. سیل عظیم دادهها و منابع محاسباتی گسترده به
ظهور یادگیری ماشین کمک اساسی کردهاند. امروزه، یادگیری ماشین به موضوع
داغ روز تبدیل شده است. حتی مهندسان نرمافزار به یک دلیل عمده در صدد
مطالعه یادگیری ماشین هستند: یادگیری ماشین تماماً با برنامهنویسی
دادهمحور سر و کار دارد و میتواند در اکثر موارد جایگزین برنامهنویسی
سنتی شود. با توجه به افزایش روزافزون محبوبیت یادگیری ماشین، افراد بسیاری
برای یادگیری آن ابراز علاقه کردهاند. اما هیچ کس به دنبال حقایق یادگیری
ماشین نیست. بنابراین، مقاله حاضر در نظر دارد با ارائه واقعیتها درباره
یادگیری ماشین راه درست را به علاقمندان نشان دهد. امیدواریم مطالب این
مقاله به شما در انتخاب این مسیر یادگیری درست کمک کند و بتوانید به شغل
رویاییتان در یادگیری ماشین دست یابید.
واقعیت ۱: دانشمندان داده و مهندسان یادگیری ماشین ۶۰ الی ۷۰ درصد زمانشان را صرف رفع مسائل کیفیت داده میکنند.
نکته
جالب درباره یادگیری ماشین این است که دادههای دنیای واقعی در وضعیت
نابسامانی به سر میبرند و مثل دیتاستهای پیشپردازش شده نیستند که از
Kaggle یا هر پلتفرم دیگری قابل دانلود باشند. دیتاستهای دنیای واقعی با
یکدیگر فرق دارند و با مسائل کیفی خاصی همراهاند. رفع این مسائل به دانش
خاص آن حوزه نیاز دارد. از جمله کارهایی که در رفع مسائل کیفی داده انجام
میگیرد، میتوان به مدیریت مقادیر گمشده، شناسایی دادهپرت، رمزگذاری
متغیرهای رستهای و غیره اشاره کرد. تلاش برای حل مسئله مقادیر گمشده،
بیشترین زمان را از دانشمندان داده میگیرد. پس از شناسایی دادهپرت باید
چه اقدامی انجام داد؟ آیا باید در صدد حذف آن برآمد؟ آیا باید مقدار مرتبطی
جایگزین آن کرد؟ این کار به دانشی بستگی دارد که باید برای مسائل تحلیلی
به کار برد. ممکن است دادهپرتها داستان جالبی داشته باشند. باید در خصوص
مسئلهای که قصد حلاش را دارید، دانش خوبی داشته باشید. بنابراین، در
پایان میتوان گفت که رفع مسائل کیفی داده به زمان زیادی نیاز دارد.
نکته کلیدی:
حین انجام یادگیری ماشین باید تمرکزتان را فقط روی مدیریت مقادیر گمشده،
شناسایی دادهپرت، کدگذاری متغیر و کسب دانش تخصصی درباره مسئله معطوف
کنید. این کار به شما کمک میکند تا به شغل رویاییتان در یادگیری ماشین
دست یابید.
واقعیت ۲: مهندسان یادگیری ماشین زمانی برای تنظیم هایپرپارامترها اختصاص نمیدهند.
نکته
دیگری که درباره یادگیری ماشین باید بدانید این است که تنظیم
هایپرپارامترها میتواند عملکرد مدل را تا حدی ارتقاء دهد. گزینههای
خودکارسازی از قبیل جستجوی شبکه یا جستجوی تصادفی نیز در تنظیم
هایپرپارامترها موجود هستند. این گزینهها از نوشتار زیاد برای
حلقهها پیشگیری کرده و باعث صرفهجویی در زمان میشوند. مهندسان یادگیری
ماشین به جای تمرکز بر تنظیم هایپرپارامترها، رفع مسائل کیفی دادهها را در
اولویت کارهایشان قرار میدهند زیرا مسائل کیفی داده میتواند به پروژه
آنها خاتمه دهد.
نکته کلیدی:
رفع مسائل کیفی داده در هنگام انجام کارهای یادگیری ماشین در دستور کارتان
باشد. وقتی میخواهید کار تنظیم هایپرپارامترها را انجام دهید، همیشه از
گزینههای خودکارسازی نظیر جستجوی شبکه یا جستجوی تصادفی استفاده کنید.
واقعیت ۳: ساخت مدل کاری نیست که در یک دوره عملیات انجام گیرد و فرایندی تکراری به شمار میرود.
یکی
از نکات جالب درباره یادگیری ماشین این است که نمیتوانید به سادگی در
زمان کم مدل خوبی بسازید. مدلسازی کاری نیست که در یک دوره عملیات انجام
گیرد و فرایندی تکراری به شمار میرود. اگر بخواهید مدل خوبی بسازید، حتماً
همه مراحل را پس و پیش میکنید تا نهایتاً به مدلی دست یابید که تنوع
بالای داده ها
را مدیریت کند. در ابتدا، ممکن است مدل پایهای بسازید که برای مقایسه با
سایر مدلها مورد استفاده قرار گیرد. سپس، ممکن است روشهای تنظیم
هایپرپارامتر دیگری را نیز امتحان کنید و عملکرد مدل را اندازه بگیرید.
همچنین، شاید بخواهید از روشهای کاهش بُعد استفاده کنید و مدلتان را
دوباره آموزش دهید. بنابراین، ساخت مدل مراحل تکراری زیادی دارد.
واقعیت ۴: تنظیم هایپرپارامتر چالش بزرگی در یادگیری بدون نظارت است.
درباره
یادگیری ماشین باید این را هم بدانید که در نوع نظارتنشده آن که برچسبی
وجود ندارد، اندازهگیریِ عملکرد مدل کار دشواری است. بنابراین، تنظیم
هایپرپارامتر چالش بزرگی در یادگیری بدون نظارت
محسوب میشود. ممکن است مقادیر مختلفی را برای هایپرپارامترها در نظر
بگیرید و نمودارهایی برای تایید انتخابتان ایجاد کنید. گاهی دانش زمینهای
در خصوص مسئله به افراد کمک میکند تا مقادیر درستی را برای
هایپرپارامترها به دست آورید.
واقعیت ۵: یادگیری ماشین خودکار نمیتواند جایگزین دانشمندان داده شود.
یادگیری
ماشین خودکار ابزاری در دست دانشمندان داده است تا کارها را به راحتی
انجام دهند؛ این ابزار به آنها کمک میکند تا کارهای تکراری و خستهکننده
را با آسودگی خاطر انجام دهند، در زمان ارزشمندشان صرفهجویی کنند و عملکرد
خوبی در سازگاری و حفظ کد داشته باشند. یادگیری ماشین خودکار دانشمندان
داده را از کار بیکار نمیکند. نیاز به دانش زمینهای و وجود دادههای
بدون برچسب در یادگیری نظارت نشده میتواند از فرایند خودکارسازی در
یادگیری ماشین پیشگیری کند.
نکته کلیدی:
چندی پیش، مقالهای درباره یادگیری ماشین خودکار منتشر کردم. این مقاله
میتواند اطلاعات بیشتری در اختیار علاقمندان قرار دهد. به لینک زیر مراجعه
کنید.
واقعیت ۶: مدلهای یادگیری ماشین Scikit-learn مثل تنسورفلو در صنعت کاربرد گستردهای ندارند.
نکته
دیگر درباره یادگیری ماشین این است که اگرچه ابزارهای ارزیابی
Scikit-learn از سازگاری بسیار بالایی برخوردارند، اما کاربرد گستردهای در
صنعت ندارند. شبکه های عصبی
به خوبی در Scikit-learn اجرا نمیشوند. Scikit-learn از GPU پشتیبانی
نمیکند. سایر الگوریتمهای موجود در عملکرد ضعیفتری نسبت به
کتابخانههایی مثل XGBoost دارند. همچنین، Scikit-learn عملکرد کُندی در
دیتاستهای بزرگ از خود نشان داده است. در مقابل، تنسورفلو گزینههای مناسبی برای شبکههای عصبی ارائه میکند.
نکته کلیدی: اگر تازه با یادگیری ماشین آشنا شدهاید، توصیه میکنم در ابتدا Scikit-learn
را یاد بگیرید تا دانش پایهای خوبی برای ادامه مسیر یادگیریتان کسب کرده
باشید. سپس، یادگیری کتابخانه تنسورفلو را در اولویت کاریتان قرار دهید.
واقعیت ۷: نیازی نیست دانشمندان داده از مسائل ریاضی الگوریتمهای یادگیری ماشین آگاهی داشته باشند.
اگرچه
بهتر است دانشمندان داده اطلاعاتی درباره هر کدام از الگوریتمها داشته
باشند، اما نیازی نیست از همه مسائل ریاضی الگوریتمهای یادگیری ماشین
آگاهی داشته باشند. دانشمندان داده فقط باید بدانند که کدام الگوریتمها
میتواند به بهترین شکل ممکن در انجام کارهای خاص به آنها کمک کند. همچنین،
باید از نحوه بکارگیری الگوریتمها آگاهی داشته باشند. علاوه بر این، آنها
باید بدانند الگوریتم
مورد نظرشان چه نوع دادههایی را به عنوان ورودی میپذیرد و از آنها خروجی
میگیرد. دانشمندان داده باید از نحوه تاثیرگذاریِ تغییرات پارامتر بر
عملکرد مدل نیز آگاه باشند. اگر آنها با مسائل ریاضی پیچیده در
الگوریتمها آشنا باشند، مزیت مضاعفی برایشان به حساب میآید، اما کسب این
دانش الزامی نیست.
واقعیت ۸: در یادگیری ماشین، هیچ برندهی مشخصی بین R و پایتون وجود ندارد.
حتماً میدانید که R و پایتون دو زبان برنامهنویسی پرکاربرد در علوم داده
و یادگیری ماشین هستند. این دو زبان مزایا و معایب خاص خود را دارند. هر
دوی آنها کتابخانههای متعددی برای تحلیل داده، دستکاری داده و کارهای
یادگیری ماشین عرضه میکنند. نمیتوان هیچ برندهای را از میان این دو
انتخاب کرد. بسته به نیازهای پروژه، ممکن است از کمکِ هر دو استفاده کنید.
با این حال، من به شخصه پایتون را ترجیح میدهم چون نحو آن به راحتی قابل
فهم است.
واقعیت ۹: SQL مهارت اصلی مهندس یادگیری ماشین است.
چون
%۷۰ یادگیری ماشین به کار با داده مربوط میشود، زبان پرسمان
ساختیافته (SQL) مهارت اصلی مهندس یادگیری ماشین است. شما میتوانید
اسکریپتهای پایتون و R را در سرورهای SQL اجرا کنید. اگر به دنبال شغلی
مرتبط با مهندسی یادگیری ماشین باشید، خواهید دید که SQL یکی از الزامات
اصلی است.
واقعیت ۱۰: مدلهای یادگیری ماشین دنیای واقعی در لپتاپ ساخته نمیشوند.
آخرین
نکته این مقاله درباره یادگیری ماشین این است که احتمالاً با ساخت مدلهای
یادگیری ماشین در لپتاپ آشنایی دارید. با این حال، این کار در کاربردهای
عملی دنیای واقعی امکانپذیر نیست. ایرادی ندارد که از لپتاپتان برای
ساخت نمونه اولیه از یک مدل استفاده کنید یا مدلسازی را تمرین کنید. بهتر
است با فرایند تلفیق و مقیاسبندیِ مدلها نیز آشنا باشید.