خواندن مقاله کاربردهای یادگیری تقویتی را با گفته کورای کاواکاغلو که رئیس بخش تحقیقات شرکت دیپمایند است آغاز میکنیم:
«اگر یکی از اهداف ما هوش مصنوعی باشد، این مدل در مرکز آن قرار دارد. یادگیری تقویتی یک چارچوب کلی برای یادگیری مسائلی است که نیاز به تصمیمگیریهای پیدرپی و متوالی دارند. یادگیری عمیق نیز مجموعهای از بهترین الگوریتمها برای یادگیری بازنمایی است. بنایراین، ترکیب این دو مدل بهترین راه موجود برای یادگیری بازنمایی وضعیت بهمنظور حل مسائل چالشبرانگیز در دنیای واقعی است.»
شبکههای عصبی پیچشی(CNN) و شبکههای عصبی بازگشتی(RNN)بهدلیل کاربردهایی که در بینایی رایانهای (CV) و پردازش زبان طبیعی(NLP)دارند، روزبهروز در حوزه کسبوکار محبوبیت بیشتری به دست میآورند. اما در این میان، اهمیت یادگیری تقویتی(RL)به عنوان چارچوبی برای علم اعصاب محاسباتی و مدلسازی فرآیندهای تصمیمگیری نادیده گرفته شده است و درخصوص نحوه بهکارگیری الگوریتمهای یادگیری تقویتی در صنایع مختلف اطلاعات چندانی دردسترس نیست. علیرغم تمامی انتقاداتی که از الگوریتمهای یادگیری تقویتی میشود، این الگوریتمها میتوانند در حوزه تصمیمگیری کمک زیادی به ما بکنند و به همین دلیل نباید نادیده گرفته شوند.
در این مقاله قصد داریم:
۱. کاربردهای یادگیری تقویتی در دنیای واقعی را با جزئیات بررسی کنیم
۲. از جنبهای دیگر به مبحث یادگیری تقویتی بپردازیم و
۳. اهمیت یادگیری تقویتی را به پژوهشگران و تصمیمگیرندگان یادآور شویم.
در بخش اول این مقاله یادگیری تقویتی بهطور کلی معرفی میشود و در بخش دوم، با ذکر مثالهایی از بهکارگیری یادگیری تقویتی، به بررسی کاربردهای آن در حوزههای مختلف میپردازیم. در بخش سوم نیز به مسائلی میپردازیم که باید پیش از بهکارگیری یادگیری تقویتی از آنها آگاه باشید. در بخش چهارم به آموزههای سایر علوم پرداختهایم. در بخش پنجم درخصوص کاربردها و منافع یادگیری تقویتی در آینده صحبت خواهیم کرد و بخش ششم نیز بخش آخر و نتیجهگیری خواهد بود.
بخش اول: مقدمهای بر یادگیری تقویتی
برای بررسی کاربردهای یادگیری تقویتی لازم است تعریف مشترکی از یادگیری تقویتی داشته باشیم . یادگیری تکنیکی است که به عامل تصمیمگیرنده اجازه میدهد تا با نشان دادن عکسالعمل به محیط و تعامل با آن، پاداش کل خود را حداکثر سازد. این نوع یادگیری در دنیای یادگیری ماشینی به عنوان یک مدل یادگیری نیمه نظارتی شناخته میشود. یادگیری تقویتی معمولاً در قالب
فرآیند تصمیمگیری مارکوف مدلسازی میشود.
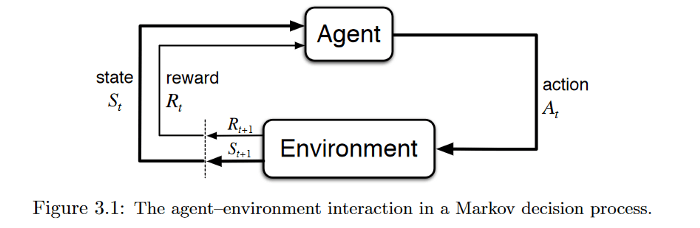
تصویر اول مقاله کاربردهای یادگیری تقویتی – تعامل عامل و محیط در فرآیند تصمیمگیری مارکوف
منبع: Reinforcement Learning:An Introduction
فرض کنید که در خانه(محیط) کنترل تلویزیون را به دست فرزند خود سپردهاید. کودک(عامل تصمیمگیرنده) ابتدا محیط را مشاهده میکند و یک بازنمایی یا تصور از محیط برای خود ایجاد میکند(وضعیت). پس از آن کودک کنجکاو روی کنترل ضربه میزند (اقدام) و واکنش تلویزیون (وضعیت بعدی) را مشاهده میکند. اگر تلویزیون پاسخی به این اقدام ندهد، جذابیتی برای کودک نخواهد داشت(کودک پاداش منفی دریافت میکند) و از این پس، اقداماتی که منجر به چنین نتیجهای شوند را کمتر انجام خواهد داد (بهروزرسانی سیاست) و برعکس. کودک این فرآیند را آنقدر تکرار میکند تا سیاستی(کاری که باید تحت شرایط مختلف انجام دهد) را پیدا کند که برایش جذاب باشد(حداکثرسازی پاداش (تنزیلشده) کل).
هدف یادگیری تقویتی ساخت یک
چارچوب ریاضیاتی برای حل مسائل است. برای مثال، برای پیدا کردن یک سیاست خوب میتوان از روشهای مبتنی بر ارزش همچون یادگیری کیفی استفاده کرد تا هماهنگی یک اقدام با یک وضعیت معین را سنجید. از طرف دیگر نیز میتوان با اعمال روشهای مبتنی بر سیاست، مستقیماً و بدون توجه به میزان هماهنگی اقدام و وضعیت، اقداماتی که میتوان در وضعیتهای مختلف انجام داد را شناسایی کرد.
اما مشکلات و مسائلی که در دنیای واقعی با آنها مواجه میشویم گاه آنقدر پیچیدهاند که الگوریتمهای رایج یادگیری تقویتی نمیتوانند هیچ راهی برای حل آنها پیدا کنند. برای مثال، فضای وضعیت(وضعیتهای محتمل) در بازی «گو»بسیار بزرگ است، یا در بازی پوکر الگوریتم قادر نیست محیط را بهطور کامل مشاهده و بررسی کند و در دنیای واقعی نیز عوامل تصمیمگیرنده با یکدیگر تعامل دارند و به اقدامات یکدیگر واکنش نشان میدهند. پژوهشگران برای حل برخی از این مسائل روشهایی ابداع کردهاند که در آنها از شبکههای عصبی عمیق برای مدلسازی سیاستهای مطلوب، توابع ارزش و حتی مدلهای انتقال استفاده میشود. این روشها یادگیری تقویتی عمیق نام گرفتهاند. البته ما در ادامه این مقاله، تمایزی بین یادگیری تقویتی و یادگیری تقویتی عمیق قائل نشدهایم. در ادامه بخش دوم را تحت عنوان کاربردهای یادگیری تقویتی مطالعه بفرمایید.
بخش دوم: کاربردهای یادگیری تقویتی
مباحث این بخش عمومی و غیرفنی است، اما خوانندگانی که با کاربردهای یادگیری تقویتی آشنایی دارند نیز میتوانند از این مطالب سود ببرند.
مدیریت منابع در محاسبات خوشهای
طراحی یک الگوریتم برای تخصیص منابع محدود به کارهای مختلف، کاری چالشبرانگیز و نیازمند الگوریتم مکاشفهای مانند ابتکار انسان است. در مقاله «Resource Management with Deep Reinforcement Learning» میخوانیم که سیستم چگونه میتواند با استفاده از الگوریتمهای یادگیری تقویتی، تخصیص و برنامهریزی منابع محاسباتی را بهطور خودکار بیاموزد و این منابع را به نحوی به پروژههای دردست اجرا تخصیص دهد که زمان تلفشده را به حداقل برسد.
در این مطالعه، فضای حالت را در قالب تخصیص کنونی منابع و مشخصات منابع موردنیاز هر پروژه تعیین کردند. برای
فضای حرکت نیز از تکنیک ویژهای استفاده نمودند که به عامل تصمیمگیرنده امکان میداد تا در هر مرحله زمانی بیش از یک اقدام انجام دهد و پاداش را هم از فرمول (∑▒〖[(-۱)/(کار هر انجام زمان مدت)]〗)/(سیستم در موجود کارهای تمام) به دست آوردند. سپس با ترکیب
الگوریتم تقویتی و
ارزش پایه ، گرادیان سیاسترا محاسبه کرده و بهترین پارامتر سیاست را که توزیع احتمال اقدامات برای حداقلسازی هدف به دست میدهد را شناسایی کردند.
کنترل چراغهای راهنمایی
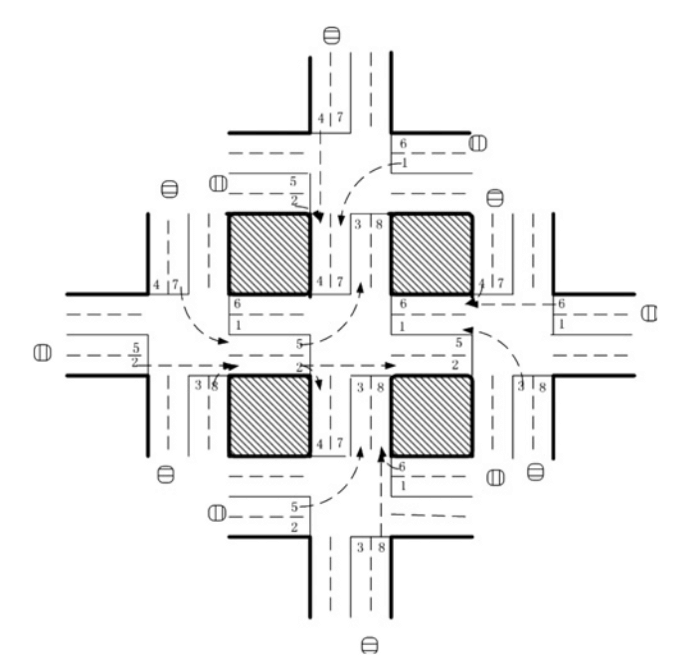
تصویر دوم مقاله کاربردهای یادگیری تقویتی – شبکه ترافیک با ۵ چهارراه منبع: http://web.eecs.utk.edu/~itamar/Papers/IET_ITS_2010.pdf
نویسندگان مقاله « Reinforcement learning-based multi-agent system for network traffic signal control» تلاش کردند تا سیستمی برای کنترل چراغهای راهنمایی طراحی نمایند که مسئله ترافیک سنگین خیابانها را حل کند. این الگوریتم تنها در محیط شبیهسازیشده و غیرواقعی آزمایش شد، اما نتایج آن بسیار بهتر از روش سنتی کنترل ترافیک بود و بدین ترتیب، کاربردهای بالقوه الگوریتمهای چند عاملی یادگیری تقویتی در حوزه طراحی سیستمهای کنترل ترافیک را برای همه آشکار کرد.
در این شبکه ترافیکی که دارای ۵ چهاراره است، یک الگوریتم یادگیری تقویتی ۵ عاملی بهکارگرفته شده که یک عامل آن در چهارراه مرکزی مستقر است تا سیگنالهای ترافیک را کنترل و هدایت کند. در اینجا، وضعیت(State) یک بردار ۸ بعدی است که هر عنصر آن نمایانگر جریان نسبی ترافیک در یکی از لاین هاست. بنابراین، عامل ۸ گزینه پیش رو دارد که هر یک از آنها نماد یک ترکیب فازی و تابع پاداش هستند. در اینجا پاداش تابعی از کاهش زمان تأخیر نسبت به مرحله زمانی قبلی است. نویسندگان در این پژوهش، بهمنظور تعیین مقدار کیفیهر جفت {وضعیت، اقدام} از شبکه عمیقQ استفاده کردند.
رباتیک
برای بهکار گرفتن الگوریتمهای یادگیری تقویتی در علم رباتیک تلاشهای زیادی شده است. برای یادگیری بیشتر شما را به مقاله « Reinforcement Learning in Robotics:A Survey» ارجاع میدهم. در پژوهشی دیگر تحت عنوان « End-to-End Training of Deep Visuomotor Policies » یک ربات تعلیم دید تا سیاستهای لازم جهت مقایسه و تطبیق تصاویر ویدیویی خام با فعالیتهای رباتی را بیاموزد. در این پژوهش، تصاویری با رنگهای RGB به شبکه عصبی پیچشی داده شدند تا الگوریتم نیروی گشتاور مورد نیاز موتور ربات را محاسبه کند و به عنوان خروجی تحویل دهد. در اینجا الگوریتم “جستجوی سیاست هدایت شده”که به عنوان مولفه یادگیری تقویتی در نظر گرفته شده است تا دادههای آموزشی موردنیاز براساس توزیع وضعیت خود الگوریتم تولید شوند.
پیکربندی سیستم وب
در هر سیستم وب بیش از ۱۰۰ پارامتر قابل پیکربندی وجود دارد. هماهنگ کردن این پارامترها نیازمند یک اپراتور ماهر و بهکارگیری روش آزمون و خطا است. مقاله Reinforcement Learning Approach to Online Web System Auto-configuration» یکی از اولین تلاشها در این زمینه است که نحوه پیکربندی مجدد پارامترها در سیستمهای وب چند لایه در محیطها پویای مبتنی بر ماشین مجازی را بررسی میکند.
فرآیند پیکربندی مجدد میتواند در قالب یک فرآیند تصمیمگیری مارکوف (MDP) محدود ارائه شود. در این پژوهش، فضای وضعیت همان پیکربندی سیستم و فضای اقدام به ازای هر پارامتر شامل {افزایش، کاهش، حفظ} بود. همچنین پاداش الگوریتم به صورت اختلاف میان زمان هدف مفروض برای پاسخگویی و زمان تخمینزده شده محاسبه میشد. پژوهشگران برای حل این مسئله از الگوریتم یادگیری کیفی فارغ از مدلاستفاده کردند.
پژوهشگران در این پژوهش بهجای ترکیب یادگیری تقویتی با شبکههای عصبی از تکنیکهای دیگری همچون مقداردهی ابتدایی به سیاستها استفاده کردند تا بتوانند مشکلات ناشی از فضای وضعیت بزرگ و پیچیدگیهای محاسباتی این مسئله را حل کنند. اما درهرحال، این پژوهش قدمی بزرگ بود که راه را برای پیشرفتهای آتی در این حوزه هموار کرد.
کاربردهای یادگیری تقویتی در حوزه شیمی
از الگوریتمهای یادگیری تقویتی میتوان در بهینهسازی واکنشهای شیمیایی نیز استفاده کرد. مدل ارائهشده در مقاله «Optimizing Chemical Reactions with Deep Reinforcement Learning» عملکرد بهتری از پیشرفتهترین الگوریتمهای موجود داشت و به ساختارهای اساسی و متفاوتی تعمیم داده شده است.
در این پژوهش، بهمنظور ارائه مدلی برای
تابع سیاست شبکه LSTM و الگوریتم یادگیری تقویتی با یکدیگر ادغام شدند تا عامل تصمیمگیرنده بتواند بهینهسازی واکنش شیمیایی را براساس فرآیند تصمیمگیری مارکوف (MDP) انجام دهد. MDP در اینجا به صورت {S,A,P,R} توصیف میشود که در آن S مجموعه شرایط آزمایش (از قبیل: دما، Ph و غیره) و A مجموعه تمام اقدامات محتملی است که میتوانند شرایط آزمایش را تغییر دهند،P احتمال انتقال از شرایط فعلی آزمایش به شرایط بعدی و R نماد پاداش میباشد که به صورت تابعی از وضعیت تعریف شده است.
این پژوهش به همه ثابت کرد که یادگیری تقویتی میتواند در محیطی نسبتاً باثبات، به خوبی از پس کارهای زمانبر و نیازمند آزمون و خطا برآید.
پیشنهادات شخصیسازیشده
کارهای پیشین در زمینه پیشنهاد اخبار با چالشهایی از جمله سرعت بالای تغییرات در پویایی اخبار، نارضایتی کاربران و نامناسب بودن معیارها مواجه شدند. فردی به نام گوانجی برای غلبه بر این مشکلات، در سیستم پیشنهاد اخبار خود از یادگیری تقویتی استفاده کرد و نتایج این کار را در مقالهای با عنوان «DRN: A Deep Reinforcement Learning Framework for News Recommendation» منتشر کرد.
پژوهشگران حاضر دراین پژوهش ۴ دسته ویژگی ایجاد کردند که عبارت بودند از:
- الف) ویژگیهای کاربر
- ب) ویژگیهای متن که همان ویژگیهای وضعیت ایجادشده در محیط بودند
- ج) ویژگیهای کاربر-خبر
- د) ویژگیهای خبر به عنوان ویژگیهای پارامتر اقدام
این ۴ ویژگی به عنوان ورودی به شبکه عمیق Q داده شدند تا مقدار کیفی مربوطه محاسبه شود. سپس براساس مقدار کیفی، فهرستی از اخبار پیشنهادی تهیه شد. در این الگوریتم یادگیری تقویتی، کلیک کاربران بر روی اخبار بخشی از پاداش عامل تصمیمگیرنده بود.
پژوهشگران برای غلبه بر سایر مشکلات از تکنیکهایی چون Memory Replay
تکرار حافظه ، مدلهای تحلیل بقا ، Dueling Bandit Gradient Descent و غیره استفاده کردند.
مزایده و تبلیغات
محققین گروه Alibaba مقالهای با عنوان «Real-Time Bidding with Multi-Agent Reinforcement Learningin Display Advertising» منتشر کردند و ادعا کردند که راهکار آنها با عنوان
مزایده چند عاملی توزیعیو مبتنی بر خوشهبندی (DCMAB) نتایج امیدوارکنندهای به دنبال داشته است و به همین دلیل، قصد دارند آن را بهصورت زنده بر روی سامانه TaoBao محک بزنند.
بررسی جزئیات نتایج این آزمایش به کاربران بستگی دارد. سامانه تبلیغاتی تائوبائو محلی است که پس از آغاز یک مزایده توسط فروشندگان، آگهی مربوط به آن به مشتریان نمایش داده میشود. این مسئله را میتوان یک مسئله چندعاملی درنظر گرفت، زیرا مزایده مربوط به هر فروشنده علیه فروشنده دیگر است و اقدامات هر عامل به اقدام سایرین بستگی دارد. در این پژوهش، فروشندگان و مشتریان در چند گروه خوشهبندی شده بودند تا از پیچیدگیهای محاسباتی کاسته شود. همچنین، فضای وضعیت هر عامل نمایانگر هزینه-فایده آن، فضای اقدام همان مزایده(پیوسته) و پاداش نیز درآمد ناشی از فرستادن تبلیغ به خوشه مشتری مناسب بود.
سوالاتی از قبیل اثر انواع مختلف پاداش(برای مثال، پاداش مبتنی بر نفع شخصی و نفع جمعی) بر درآمد عامل نیز در این مقاله پاسخ داده شدهاند.
بازیها
شناخته شدن الگوریتمهای یادگیری تقویتی عمدتاً به دلیل کاربردهای گسترده آن در بازیها و گاه عملکرد فرابشری این الگوریتمها بوده است.
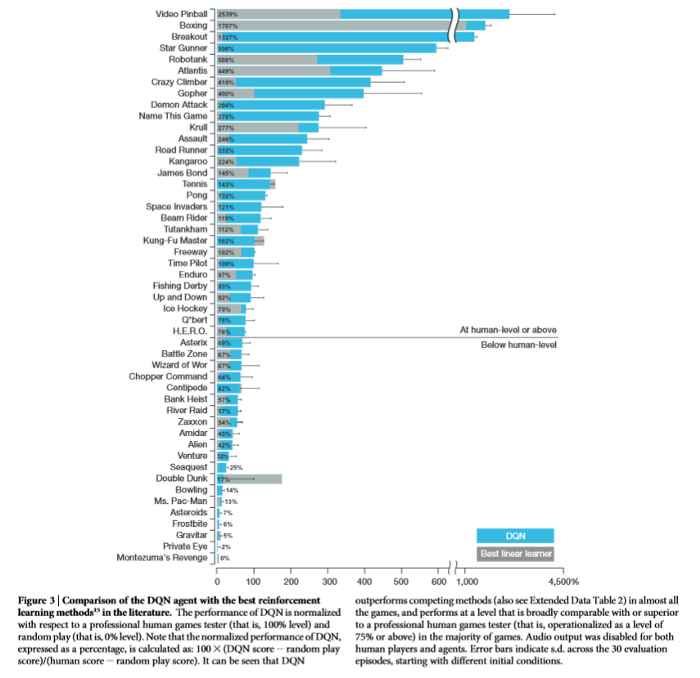
تصویر سوم مقاله کاربردهای یادگیری تقویتی – مقایسه عملکرد انسان، مدل خطی و یادگیری تقویتی
منبع: https://web.stanford.edu/class/psych209/Readings/MnihEtAlHassibis15NatureControlDeepRL.pdf
نامآشناترین الگوریتمها در این حوزه AlphaGo و AlphaGo Zero هستند. برای آموزش الگوریتم آلفاگو دادههای بیشماری از روند بازیهای انسانی جمعآوری و به آن داده شد. این الگوریتم با بهرهگیری از تکنیک جستوجوی درختی مونت کارلو (MCTS) و شبکه ارزش تعبیه شده در شبکه سیاست خود توانست عملکردی فرابشری داشته باشد. اما کمی بعد از آن، توسعهدهندگان این الگوریتم قدمی به عقب برداشته و تلاش کردند تا با رویکردی بهبودیافته یعنی آموزش الگوریتم از صفر، دوباره این کار را انجام دهد. بدین ترتیب، پژوهشگران عامل جدید خود یعنی AlphaGo Zero را در بازی، رقیب خودش قرار دادند. این الگوریتم جدید درنهایت توانست ۱۰۰-۰ آلفاگو را شکست دهد.
یادگیری عمیق
امروزه شاهد تلاشهای روزافزون برای ترکیب یادگیری تقویتی با سایر معماریهای یادگیری عمیق هستیم. برخی از این تلاشها نتایج شگفتانگیزی داشتهاند.
یکی از تأثیرگذارترین پروژهها در این حوزه، ترکیب شبکههای عصبی پیچشی (CNN) با یادگیری تقویتی بود که توسط شرکت DeepMind انجام گرفت. با ترکیب این دو، عامل تصمیمگیرنده به کمک حواس چند بُعدی خود توانایی دیدن محیط را خواهد داشت و نحوه تعامل با محیط را میآموزد.
یکی دیگر از ترکیباتی که برای آزمایش ایدههای جدید از آن استفاده میشود، ترکیب یادگیری تقویتی و شبکههای عصبی بازگشتی (RNN) است. شبکه عصبی بازگشتی یا RNN میتواند اتفاقات را به خاطر بسپارد. وقتی این شبکه عصبی با الگوریتمهای یادگیری تقویتی ترکیب شود، عامل تصمیمگیرنده نیز قادر به یادآوری و به خاطر سپردن اتفاقات خواهد بود. برای مثال، از ترکیب شبکه LSTM (حافظه طولانی کوتاهمدت) با یادگیری تقویتی، شبکه بازگشتی و عمیق Q (DRQN) به دست آمد که میتواند بازیهای آتاری ۲۶۰۰ را انجام دهد. علاوه براین، ترکیب یادیگری تقویتی و شبکه عصبی بازگشتی در بهینهسازی واکنشهای شیمیایی نیز کاربرد دارد.

تصویر چهارم مقاله کاربردهای یادگیری تقویتی – مقایسه ورودی با نتایج تولید شده توسط عامل
منبع: https://www.youtube.com/watch?v=N5oZIO8pE40
DeepMind به ما نشان داد که چگونه برای ساخت برنامههای خود از مدلهای مولد و یادگیری تقویتی بهره ببریم. در این مدل همانند فرآیند آموزش در شبکههای مولد تخاصمی (GAN) ، عامل درنتیجه تقابل با سایر عوامل آموزش میبیند و با کمک سیگنالهایی که به عنوان پاداش دریافت میکند، به جای پخش کردن گرادیانها در فضای ورودی، اقدامات خود را بهبود میبخشد.
بخش سوم: آنچه باید پیش از استفاده از یادگیری تقویتی بدانید
در ادامه موارد و نکاتی ذکر شدهاند که پیشنیاز بهکارگیری یادگیری تقویتی در حل مسائل مختلف میباشند:
شناخت مسئله مدنظر: هیچ الزامی برای استفاده از یادگیری تقویتی برای حل یک مسئله وجود ندارد و حتی گاه این روش برای حل مسئلهای که با آن مواجهیم، مناسب نیست. بهتر است پیش از بهکارگیری یادگیری تقویتی بررسی کنید که آیا مسئله موردنظر شما ویژگیهای لازم را دارد یا خیر. برخی از این ویژگیها عبارتند از:
- ۱. آزمون و خطا (بهبود کیفیت یادگیری در اثر دریافت بازخورد از محیط)
- ۲. پاداش متأخر
- ۳. امکان مدلسازی در قالب MDP
- ۴. موضوع کنترل مطرح باشد
محیط شبیهسازی شده: پیش از شروع به کار یک الگوریتم یادگیری تقویتی، روش حل مسئله آن باید بارها تکرار شود. مطمئناً ما نمیخواهیم عامل یادگیری تقویتی که پشت یک اتومبیل خودران قرار گرفته، در وسط بزرگراه، روشهای مختلف حل مسئله را امتحان کند. بنابراین، به یک محیط شبیهسازی شده که بازتاب دقیقی از دنیای واقعی باشد، نیاز داریم.
فرآیند تصمیمگیری مارکوف (MDP): شما باید بتوانید مسئله مدنظر خود را در قالب یک MDP مدلسازی کنید. بدین منظور باید فضای وضعیت، فضای اقدام، تابع پاداش و سایر موارد موردنیاز را طراحی کنید. عامل تصمیمگیرنده شما نیز تحت قیود تعریف شده و براساس پاداشی که دریافت کرده، اقداماتی را در پیش میگیرد. اگر طراحی این موارد دقیق و متناسب با هدف نباشد، ممکن است به نتایج دلخواهتان دست پیدا نکنید.
الگوریتمها: در دنیای یادگیری تقویتی الگوریتمهای زیادی وجود دارد. اما برای انتخاب الگوریتم مناسب باید از خود بپرسید که آیا میخواهید الگوریتم مستقیماً سیاست را پیدا کند یا میخواهید براساس تابع ارزش آموزش ببیند؟ میخواهید الگوریتم شما مبتنی بر مدل باشد یا بدون مدل؟ آیا میخواهید برای حل این مسئله، علاوه بر یادگیری تقویتی از سایر شبکههای عصبی یا روشها نیز کمک بگیرید یا خیر؟
بهمنظور تصمیمگیری درست و واقعبینانه، باید از کاستیهای یادگیری تقویتی نیز آگاه باشید. با مراجعه به این لینک میتوانید نقاطضعف این الگوریتمها را نیز بشناسید.
بخش چهارم: آموزه هایی از سایر علوم
یادگیری تقویتی رابطه نزدیکی با علوم روانشناسی، زیستشناسی و عصبشناسی دارد. اگر کمی دقیقتر بنگرید، تنها کاری که یک عامل تصمیمگیرنده در الگوریتم یادگیری تقویتی انجام میدهد، آزمون و خطاست. این عامل براساس پاداشی که از محیط دریافت میکند، میآموزد که اقداماتش درست بودهاند یا اشتباه. این دقیقاً همان مسیری است که یک انسان برای یادگیری یک مسئله بارها و بارها طی میکند. علاوه براین، ما هر روز با مسائلی چون اکتشاف و انتفاع و تخصیص اعتبار مواجه میشویم و سعی در ارائه یک مدل از محیط اطراف خود داریم.
برخی نظریات اقتصادی نیز گاه وارد دنیای یادگیری تقویتی میشوند. برای مثال، در حوزه تحلیل یادگیری تقویتی چندعاملی (MARL) از نظریه بازیها کمک میگیریم. نظریه بازیها که توسط جان نَش ارائه شده است، در درک تعاملات عوامل حاضر در یک سیستم به ما کمک میکند. علاوه بر کاربرد نظریه بازیها در MARL، فرآیندهای تصمیمگیری مارکوف با مشاهدهپذیری جزئی (POMDP) نیز در فهم موضوعات اقتصادی از جمله ساختار بازارها(انحصار یک جانبه، انحصار چند جانبه و غیره)، اثرات خارجی و اطلاعات نامتقارن به کمک اقتصاددانان میروند.
بخش پنجم: دستآوردهای احتمالی یادگیری تقویتی در آینده
یادگیری تقویتی هنوز مشکلات و نقصهای زیادی دارد و استفاده از آن آسان نیست. اما با توجه به تلاشهای روزافزونی که بهمنظور رفع این نقصها صورت میگیرد، یادگیری تقویتی میتواند در آنیده در حوزههای زیر تأثیرگذار باشد:
همکاری با انسانها: شاید گفتن اینکه یادگیری تقویتی در آینده میتواند بخشی از دنیای هوش مصنوعی عمومی باشد، زیادهروی بهنظر برسد، اما یادگیری تقویتی توانایی همکاری و همراهی با انسان را دارد. برای مثال فرض کنید ربات یا دستیار مجازی که با شما کار میکند، برای اقدام و یا تصمیم بعدی خود، اقدامات پیشین شما را مدنظر قرار دهد. واقعاً شگفتانگیز نیست؟
برآورد عواقب استراتژیها مختلف: در دنیای ما زمان به عقب برنمیگردد و هر اتفاق تنها یکبار رخ میدهد و همین است که زندگی را اعجاببرانگیز میسازد. اما گاهی میخواهیم بدانیم اگر در گذشته تصمیمی متفاوت گرفته بودیم، شرایط کنونی چگونه بود؟ یا اگر مربی تیم ملی کرواسی استراتژی متفاوتی را در پیش میگرفت، شانس این تیم برای پیروزی در جامجهانی ۲۰۱۸ بیشتر میشد؟ البته برای انجام چنین برآوردهایی باید تابع انتقال و محیط را بسیار دقیق مدلسازی کنیم و تعاملات میان محیط و عامل را تجزیه و تحلیل کنیم. کاری که درحالحاضر غیرممکن بهنظر میرسد.
بخش ششم: نتیجهگیری
در این مقاله تنها چند مثال از کاربرد یادگیری تقویتی در صنایع مختلف را ذکر کردیم، اما شما نباید ذهن خود را به این مثالها محدود کنید و مثل همیشه، ابتدا باید بهطور کاملاً اصولی و دقیق طبیعت و ذات الگوریتمهای یادگیری تقویتی و مسئله خود را بشناسید.
اگر تصمیمگیری یکی از وظایف شغلی شماست، امیداوارم این مقاله شما را به سوی بررسی شرایط و پیدا کردن راهی برای استفاده از یادگیری تقویتی سوق داده باشد. و اگر پژوهشگر هستید، امیدوارم پذیرفته باشید که یادگیری تقویتی علیرغم تمام کاستیهایش، پتانسیل زیادی برای بهبود یافتن دارد و فرصتهای زیادی برای تحقیق و پژوهش در این زمینه فراهم است.
منبع: hooshio.com